 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAviationGPT: A Large Language Model for the Aviation Domain
Nov 29, 2023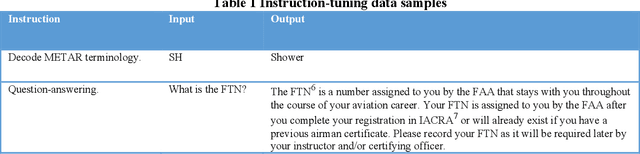
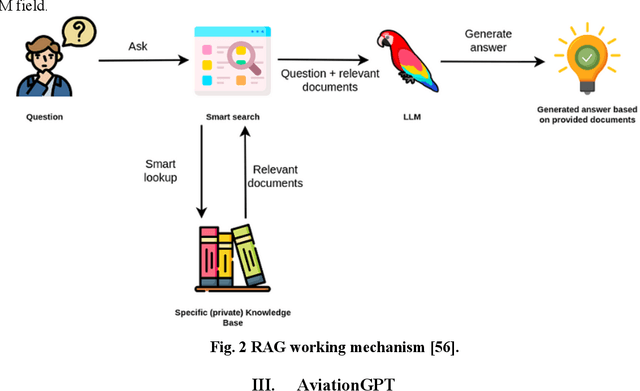
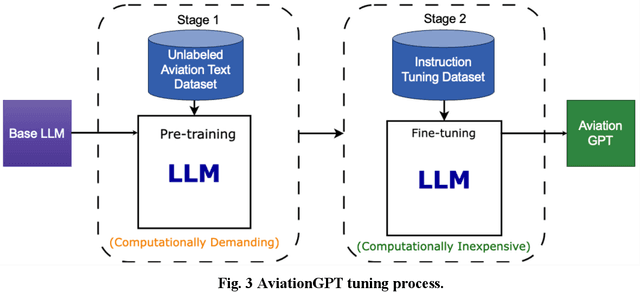
The advent of ChatGPT and GPT-4 has captivated the world with large language models (LLMs), demonstrating exceptional performance in question-answering, summarization, and content generation. The aviation industry is characterized by an abundance of complex, unstructured text data, replete with technical jargon and specialized terminology. Moreover, labeled data for model building are scarce in this domain, resulting in low usage of aviation text data. The emergence of LLMs presents an opportunity to transform this situation, but there is a lack of LLMs specifically designed for the aviation domain. To address this gap, we propose AviationGPT, which is built on open-source LLaMA-2 and Mistral architectures and continuously trained on a wealth of carefully curated aviation datasets. Experimental results reveal that AviationGPT offers users multiple advantages, including the versatility to tackle diverse natural language processing (NLP) problems (e.g., question-answering, summarization, document writing, information extraction, report querying, data cleaning, and interactive data exploration). It also provides accurate and contextually relevant responses within the aviation domain and significantly improves performance (e.g., over a 40% performance gain in tested cases). With AviationGPT, the aviation industry is better equipped to address more complex research problems and enhance the efficiency and safety of National Airspace System (NAS) operations.
Adapting Sentence Transformers for the Aviation Domain
May 16, 2023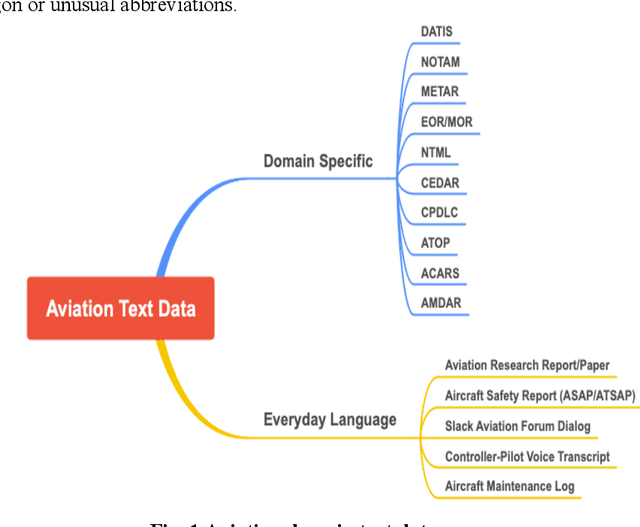

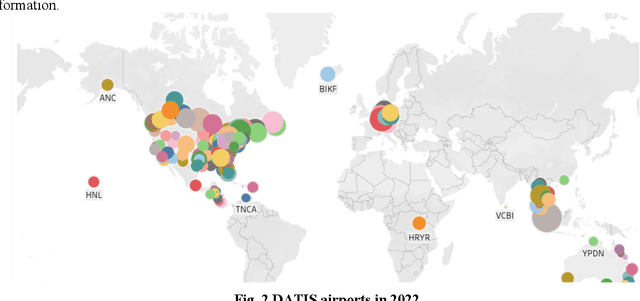

Learning effective sentence representations is crucial for many Natural Language Processing (NLP) tasks, including semantic search, semantic textual similarity (STS), and clustering. While multiple transformer models have been developed for sentence embedding learning, these models may not perform optimally when dealing with specialized domains like aviation, which has unique characteristics such as technical jargon, abbreviations, and unconventional grammar. Furthermore, the absence of labeled datasets makes it difficult to train models specifically for the aviation domain. To address these challenges, we propose a novel approach for adapting sentence transformers for the aviation domain. Our method is a two-stage process consisting of pre-training followed by fine-tuning. During pre-training, we use Transformers and Sequential Denoising AutoEncoder (TSDAE) with aviation text data as input to improve the initial model performance. Subsequently, we fine-tune our models using a Natural Language Inference (NLI) dataset in the Sentence Bidirectional Encoder Representations from Transformers (SBERT) architecture to mitigate overfitting issues. Experimental results on several downstream tasks show that our adapted sentence transformers significantly outperform general-purpose transformers, demonstrating the effectiveness of our approach in capturing the nuances of the aviation domain. Overall, our work highlights the importance of domain-specific adaptation in developing high-quality NLP solutions for specialized industries like aviation.
Remote Sensing Scene Classification with Masked Image Modeling (MIM)
Feb 28, 2023Remote sensing scene classification has been extensively studied for its critical roles in geological survey, oil exploration, traffic management, earthquake prediction, wildfire monitoring, and intelligence monitoring. In the past, the Machine Learning (ML) methods for performing the task mainly used the backbones pretrained in the manner of supervised learning (SL). As Masked Image Modeling (MIM), a self-supervised learning (SSL) technique, has been shown as a better way for learning visual feature representation, it presents a new opportunity for improving ML performance on the scene classification task. This research aims to explore the potential of MIM pretrained backbones on four well-known classification datasets: Merced, AID, NWPU-RESISC45, and Optimal-31. Compared to the published benchmarks, we show that the MIM pretrained Vision Transformer (ViTs) backbones outperform other alternatives (up to 18% on top 1 accuracy) and that the MIM technique can learn better feature representation than the supervised learning counterparts (up to 5% on top 1 accuracy). Moreover, we show that the general-purpose MIM-pretrained ViTs can achieve competitive performance as the specially designed yet complicated Transformer for Remote Sensing (TRS) framework. Our experiment results also provide a performance baseline for future studies.
Aerial Image Object Detection With Vision Transformer Detector (ViTDet)
Feb 02, 2023
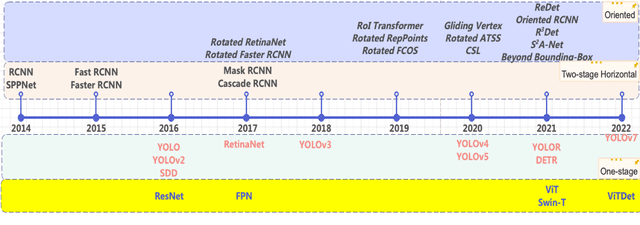
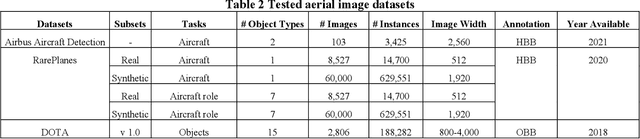
The past few years have seen an increased interest in aerial image object detection due to its critical value to large-scale geo-scientific research like environmental studies, urban planning, and intelligence monitoring. However, the task is very challenging due to the birds-eye view perspective, complex backgrounds, large and various image sizes, different appearances of objects, and the scarcity of well-annotated datasets. Recent advances in computer vision have shown promise tackling the challenge. Specifically, Vision Transformer Detector (ViTDet) was proposed to extract multi-scale features for object detection. The empirical study shows that ViTDet's simple design achieves good performance on natural scene images and can be easily embedded into any detector architecture. To date, ViTDet's potential benefit to challenging aerial image object detection has not been explored. Therefore, in our study, 25 experiments were carried out to evaluate the effectiveness of ViTDet for aerial image object detection on three well-known datasets: Airbus Aircraft, RarePlanes, and Dataset of Object DeTection in Aerial images (DOTA). Our results show that ViTDet can consistently outperform its convolutional neural network counterparts on horizontal bounding box (HBB) object detection by a large margin (up to 17% on average precision) and that it achieves the competitive performance for oriented bounding box (OBB) object detection. Our results also establish a baseline for future research.
Flight Demand Forecasting with Transformers
Nov 04, 2021
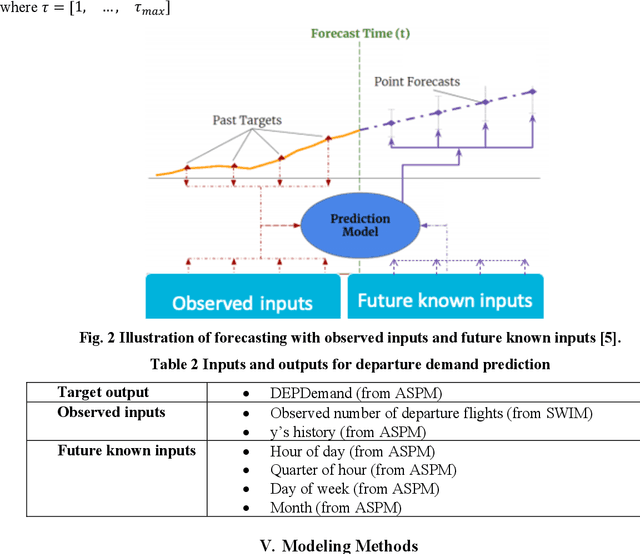
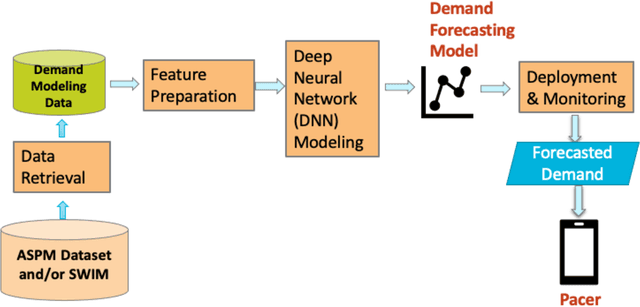
Transformers have become the de-facto standard in the natural language processing (NLP) field. They have also gained momentum in computer vision and other domains. Transformers can enable artificial intelligence (AI) models to dynamically focus on certain parts of their input and thus reason more effectively. Inspired by the success of transformers, we adopted this technique to predict strategic flight departure demand in multiple horizons. This work was conducted in support of a MITRE-developed mobile application, Pacer, which displays predicted departure demand to general aviation (GA) flight operators so they can have better situation awareness of the potential for departure delays during busy periods. Field demonstrations involving Pacer's previously designed rule-based prediction method showed that the prediction accuracy of departure demand still has room for improvement. This research strives to improve prediction accuracy from two key aspects: better data sources and robust forecasting algorithms. We leveraged two data sources, Aviation System Performance Metrics (ASPM) and System Wide Information Management (SWIM), as our input. We then trained forecasting models with temporal fusion transformer (TFT) for five different airports. Case studies show that TFTs can perform better than traditional forecasting methods by large margins, and they can result in better prediction across diverse airports and with better interpretability.
Multi-Airport Delay Prediction with Transformers
Nov 04, 2021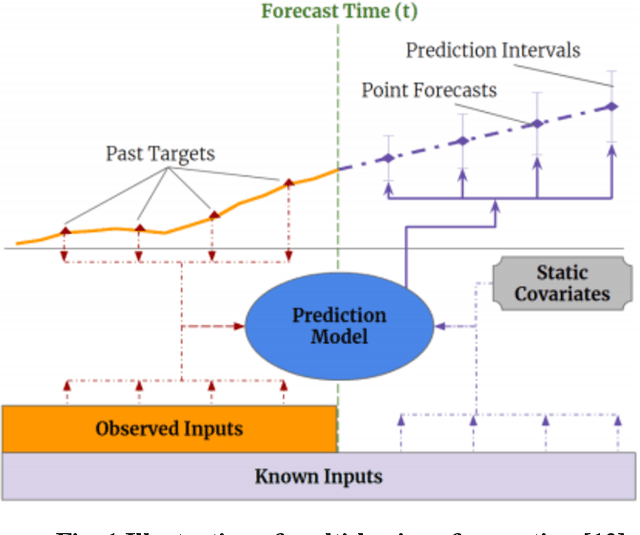
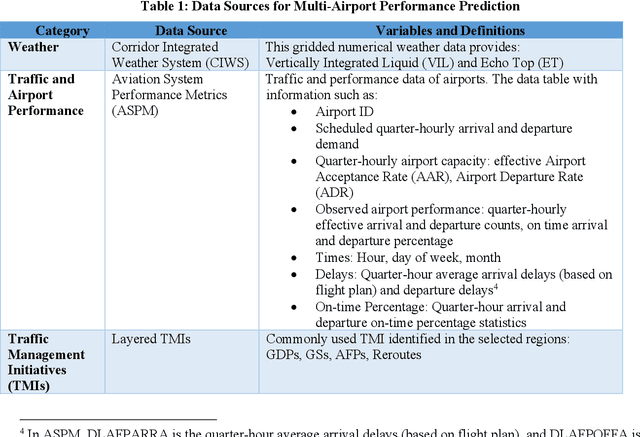
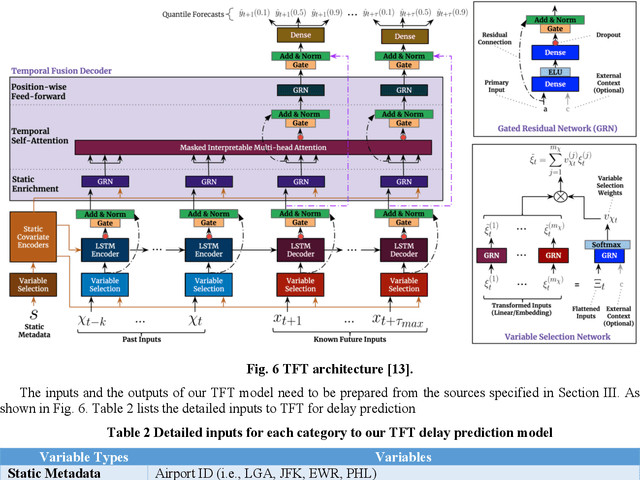
Airport performance prediction with a reasonable look-ahead time is a challenging task and has been attempted by various prior research. Traffic, demand, weather, and traffic management actions are all critical inputs to any prediction model. In this paper, a novel approach based on Temporal Fusion Transformer (TFT) was proposed to predict departure and arrival delays simultaneously for multiple airports at once. This approach can capture complex temporal dynamics of the inputs known at the time of prediction and then forecast selected delay metrics up to four hours into the future. When dealing with weather inputs, a self-supervised learning (SSL) model was developed to encode high-dimensional weather data into a much lower-dimensional representation to make the training of TFT more efficiently and effectively. The initial results show that the TFT-based delay prediction model achieves satisfactory performance measured by smaller prediction errors on a testing dataset. In addition, the interpretability analysis of the model outputs identifies the important input factors for delay prediction. The proposed approach is expected to help air traffic managers or decision makers gain insights about traffic management actions on delay mitigation and once operationalized, provide enough lead time to plan for predicted performance degradation.
Helicopter Track Identification with Autoencoder
Mar 03, 2021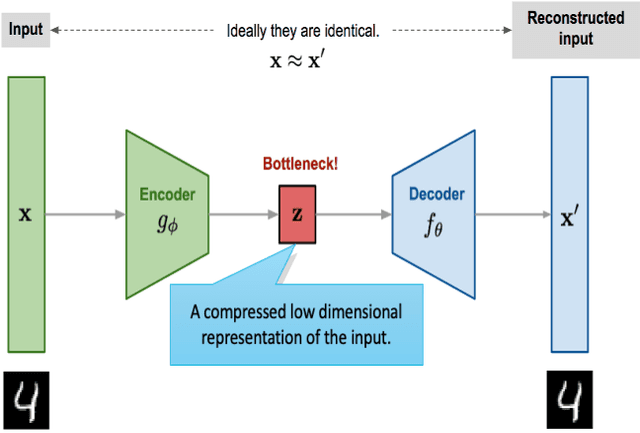
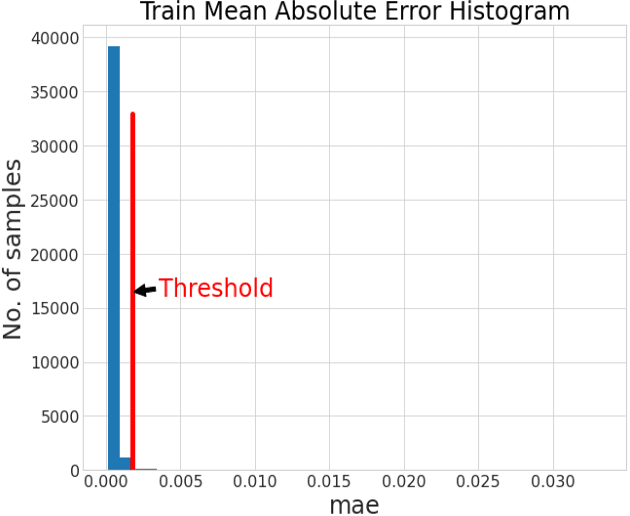
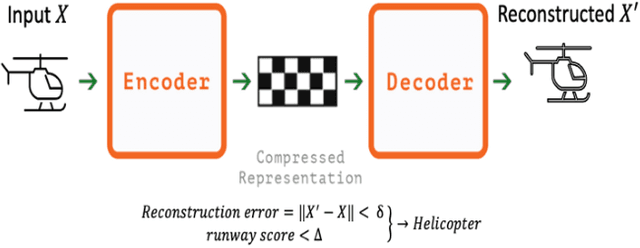
Computing power, big data, and advancement of algorithms have led to a renewed interest in artificial intelligence (AI), especially in deep learning (DL). The success of DL largely lies on data representation because different representations can indicate to a degree the different explanatory factors of variation behind the data. In the last few year, the most successful story in DL is supervised learning. However, to apply supervised learning, one challenge is that data labels are expensive to get, noisy, or only partially available. With consideration that we human beings learn in an unsupervised way; self-supervised learning methods have garnered a lot of attention recently. A dominant force in self-supervised learning is the autoencoder, which has multiple uses (e.g., data representation, anomaly detection, denoise). This research explored the application of an autoencoder to learn effective data representation of helicopter flight track data, and then to support helicopter track identification. Our testing results are promising. For example, at Phoenix Deer Valley (DVT) airport, where 70% of recorded flight tracks have missing aircraft types, the autoencoder can help to identify twenty-two times more helicopters than otherwise detectable using rule-based methods; for Grand Canyon West Airport (1G4) airport, the autoencoder can identify thirteen times more helicopters than a current rule-based approach. Our approach can also identify mislabeled aircraft types in the flight track data and find true types for records with pseudo aircraft type labels such as HELO. With improved labelling, studies using these data sets can produce more reliable results.
Deep Learning for Flight Demand and Delays Forecasting
Nov 10, 2020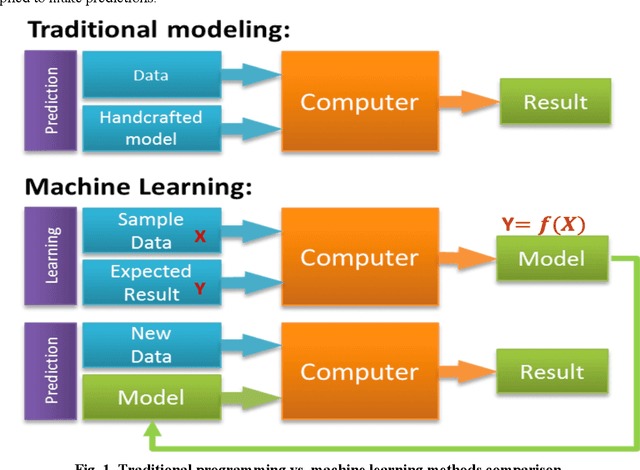
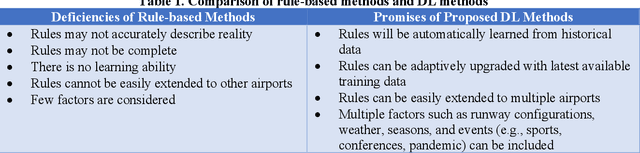

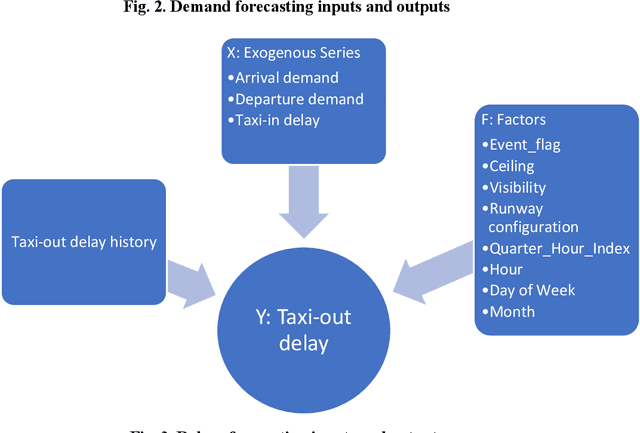
The last few years have seen an increased interest in deep learning (DL) due to its success in applications such as computer vision, natural language processing (NLP), and self-driving cars. Inspired by this success, this paper applied DL to predict flight demand and delays, which have been a concern for airlines and the other stakeholders in the National Airspace System (NAS). Demand and delay prediction can be formulated as a supervised learning problem, where, given an understanding of past historical demand and delays, a deep learning network can examine sequences of historic data to predict current and future sequences. With that in mind, we applied a well-known DL method, sequence to sequence (seq2seq), to solve the problem. Our results show that the seq2seq method can reduce demand prediction mean squared error (MSE) by 50%, compared to two classical baseline algorithms.
Autoencoding Features for Aviation Machine Learning Problems
Nov 07, 2020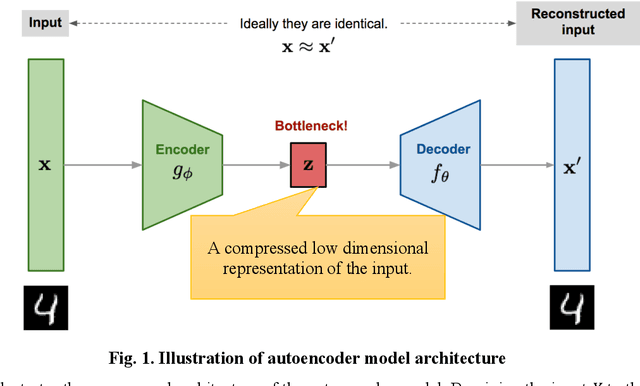
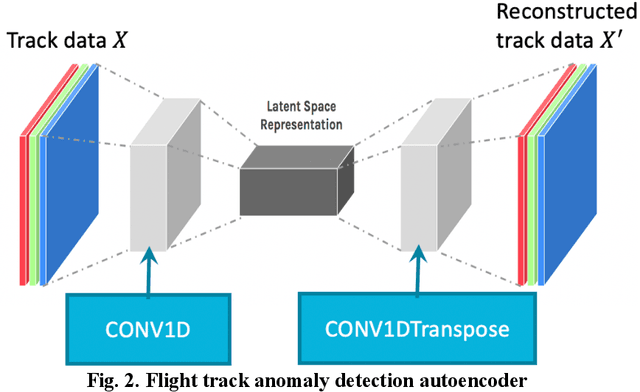

The current practice of manually processing features for high-dimensional and heterogeneous aviation data is labor-intensive, does not scale well to new problems, and is prone to information loss, affecting the effectiveness and maintainability of machine learning (ML) procedures. This research explored an unsupervised learning method, autoencoder, to extract effective features for aviation machine learning problems. The study explored variants of autoencoders with the aim of forcing the learned representations of the input to assume useful properties. A flight track anomaly detection autoencoder was developed to demonstrate the versatility of the technique. The research results show that the autoencoder can not only automatically extract effective features for the flight track data, but also efficiently deep clean data, thereby reducing the workload of data scientists. Moreover, the research leveraged transfer learning to efficiently train models for multiple airports. Transfer learning can reduce model training times from days to hours, as well as improving model performance. The developed applications and techniques are shared with the whole aviation community to improve effectiveness of ongoing and future machine learning studies.
Applications of Machine Learning Methods to Quantifying Phenotypic Traits that Distinguish the Wild Type from the Mutant Arabidopsis Thaliana Seedlings during Root Gravitropism
Aug 31, 2010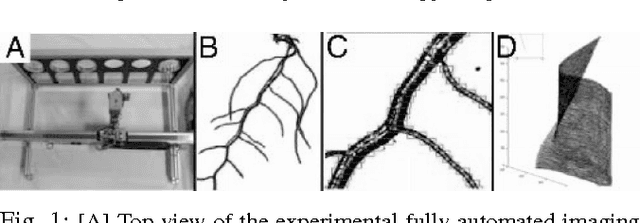

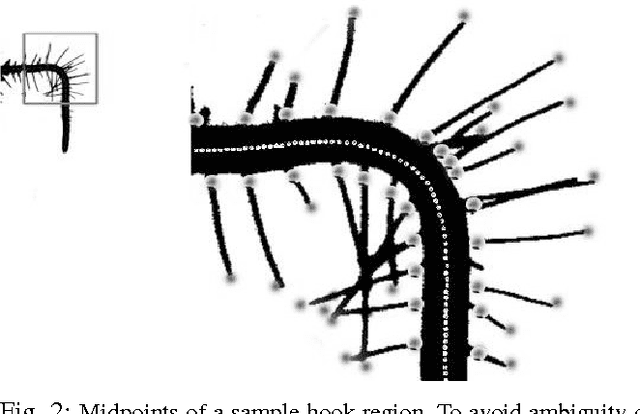
Post-genomic research deals with challenging problems in screening genomes of organisms for particular functions or potential for being the targets of genetic engineering for desirable biological features. 'Phenotyping' of wild type and mutants is a time-consuming and costly effort by many individuals. This article is a preliminary progress report in research on large-scale automation of phenotyping steps (imaging, informatics and data analysis) needed to study plant gene-proteins networks that influence growth and development of plants. Our results undermine the significance of phenotypic traits that are implicit in patterns of dynamics in plant root response to sudden changes of its environmental conditions, such as sudden re-orientation of the root tip against the gravity vector. Including dynamic features besides the common morphological ones has paid off in design of robust and accurate machine learning methods to automate a typical phenotyping scenario, i.e. to distinguish the wild type from the mutants.