 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAviationGPT: A Large Language Model for the Aviation Domain
Nov 29, 2023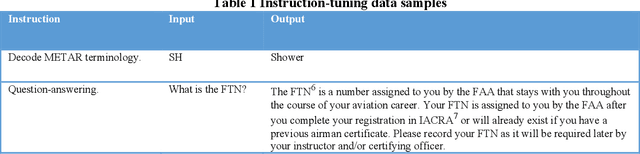
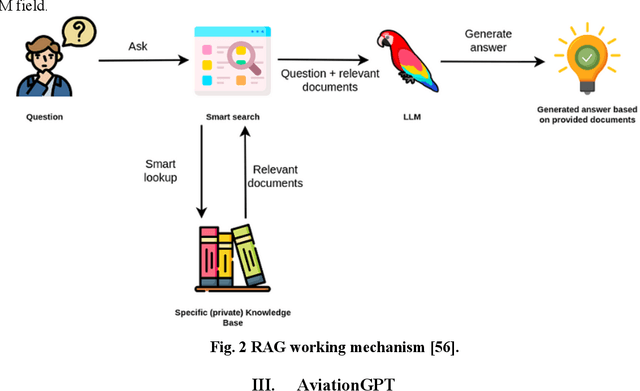
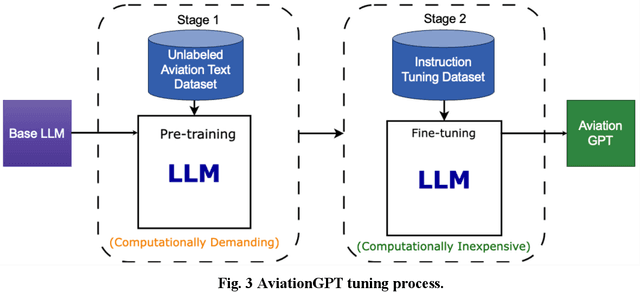
The advent of ChatGPT and GPT-4 has captivated the world with large language models (LLMs), demonstrating exceptional performance in question-answering, summarization, and content generation. The aviation industry is characterized by an abundance of complex, unstructured text data, replete with technical jargon and specialized terminology. Moreover, labeled data for model building are scarce in this domain, resulting in low usage of aviation text data. The emergence of LLMs presents an opportunity to transform this situation, but there is a lack of LLMs specifically designed for the aviation domain. To address this gap, we propose AviationGPT, which is built on open-source LLaMA-2 and Mistral architectures and continuously trained on a wealth of carefully curated aviation datasets. Experimental results reveal that AviationGPT offers users multiple advantages, including the versatility to tackle diverse natural language processing (NLP) problems (e.g., question-answering, summarization, document writing, information extraction, report querying, data cleaning, and interactive data exploration). It also provides accurate and contextually relevant responses within the aviation domain and significantly improves performance (e.g., over a 40% performance gain in tested cases). With AviationGPT, the aviation industry is better equipped to address more complex research problems and enhance the efficiency and safety of National Airspace System (NAS) operations.
Adapting Sentence Transformers for the Aviation Domain
May 16, 2023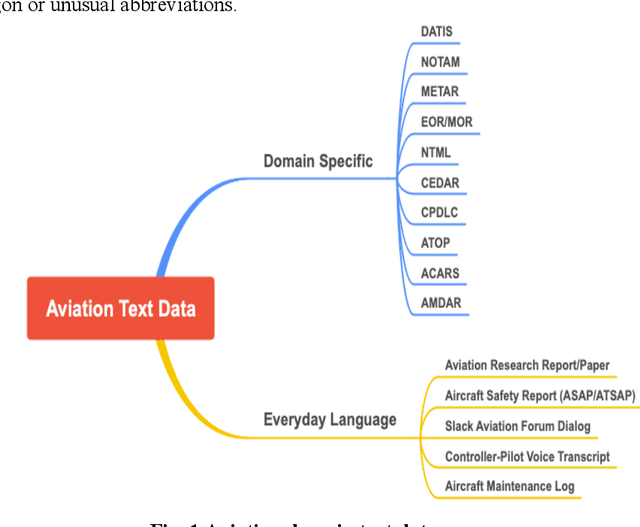

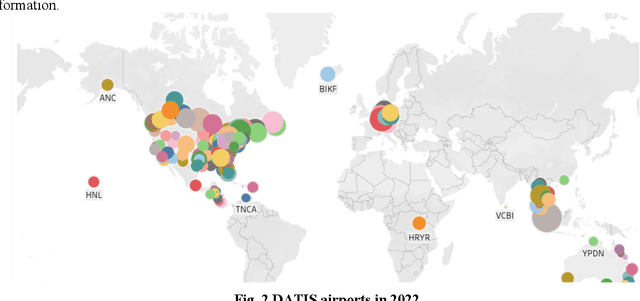

Learning effective sentence representations is crucial for many Natural Language Processing (NLP) tasks, including semantic search, semantic textual similarity (STS), and clustering. While multiple transformer models have been developed for sentence embedding learning, these models may not perform optimally when dealing with specialized domains like aviation, which has unique characteristics such as technical jargon, abbreviations, and unconventional grammar. Furthermore, the absence of labeled datasets makes it difficult to train models specifically for the aviation domain. To address these challenges, we propose a novel approach for adapting sentence transformers for the aviation domain. Our method is a two-stage process consisting of pre-training followed by fine-tuning. During pre-training, we use Transformers and Sequential Denoising AutoEncoder (TSDAE) with aviation text data as input to improve the initial model performance. Subsequently, we fine-tune our models using a Natural Language Inference (NLI) dataset in the Sentence Bidirectional Encoder Representations from Transformers (SBERT) architecture to mitigate overfitting issues. Experimental results on several downstream tasks show that our adapted sentence transformers significantly outperform general-purpose transformers, demonstrating the effectiveness of our approach in capturing the nuances of the aviation domain. Overall, our work highlights the importance of domain-specific adaptation in developing high-quality NLP solutions for specialized industries like aviation.
Remote Sensing Scene Classification with Masked Image Modeling (MIM)
Feb 28, 2023Remote sensing scene classification has been extensively studied for its critical roles in geological survey, oil exploration, traffic management, earthquake prediction, wildfire monitoring, and intelligence monitoring. In the past, the Machine Learning (ML) methods for performing the task mainly used the backbones pretrained in the manner of supervised learning (SL). As Masked Image Modeling (MIM), a self-supervised learning (SSL) technique, has been shown as a better way for learning visual feature representation, it presents a new opportunity for improving ML performance on the scene classification task. This research aims to explore the potential of MIM pretrained backbones on four well-known classification datasets: Merced, AID, NWPU-RESISC45, and Optimal-31. Compared to the published benchmarks, we show that the MIM pretrained Vision Transformer (ViTs) backbones outperform other alternatives (up to 18% on top 1 accuracy) and that the MIM technique can learn better feature representation than the supervised learning counterparts (up to 5% on top 1 accuracy). Moreover, we show that the general-purpose MIM-pretrained ViTs can achieve competitive performance as the specially designed yet complicated Transformer for Remote Sensing (TRS) framework. Our experiment results also provide a performance baseline for future studies.
Aerial Image Object Detection With Vision Transformer Detector (ViTDet)
Feb 02, 2023
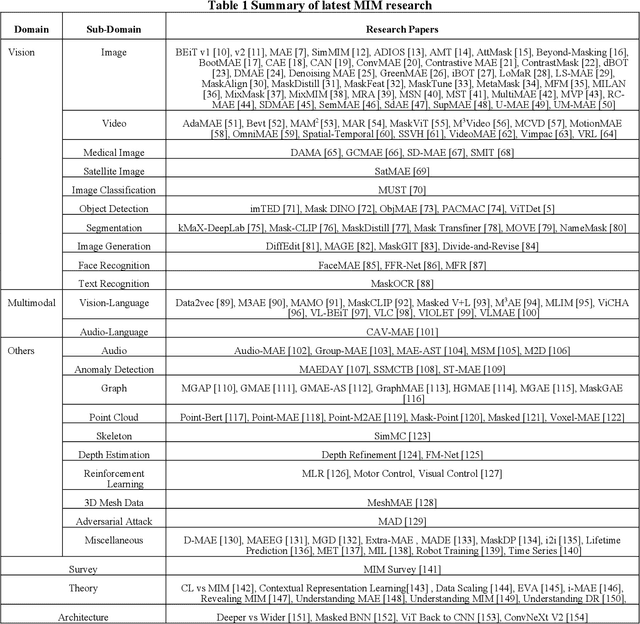
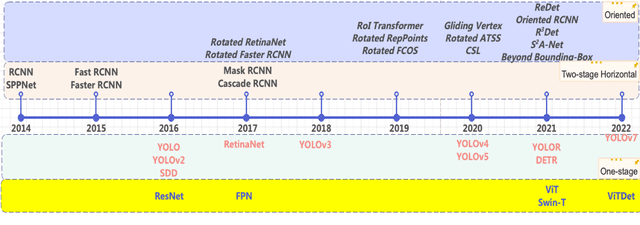
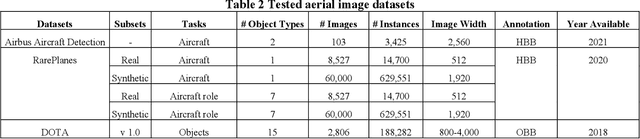
The past few years have seen an increased interest in aerial image object detection due to its critical value to large-scale geo-scientific research like environmental studies, urban planning, and intelligence monitoring. However, the task is very challenging due to the birds-eye view perspective, complex backgrounds, large and various image sizes, different appearances of objects, and the scarcity of well-annotated datasets. Recent advances in computer vision have shown promise tackling the challenge. Specifically, Vision Transformer Detector (ViTDet) was proposed to extract multi-scale features for object detection. The empirical study shows that ViTDet's simple design achieves good performance on natural scene images and can be easily embedded into any detector architecture. To date, ViTDet's potential benefit to challenging aerial image object detection has not been explored. Therefore, in our study, 25 experiments were carried out to evaluate the effectiveness of ViTDet for aerial image object detection on three well-known datasets: Airbus Aircraft, RarePlanes, and Dataset of Object DeTection in Aerial images (DOTA). Our results show that ViTDet can consistently outperform its convolutional neural network counterparts on horizontal bounding box (HBB) object detection by a large margin (up to 17% on average precision) and that it achieves the competitive performance for oriented bounding box (OBB) object detection. Our results also establish a baseline for future research.
Airport Taxi Time Prediction and Alerting: A Convolutional Neural Network Approach
Nov 17, 2021

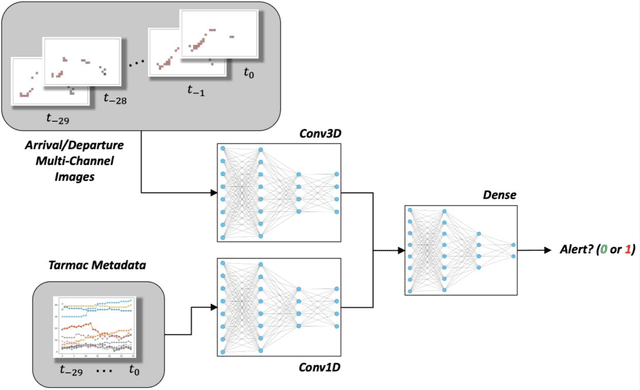
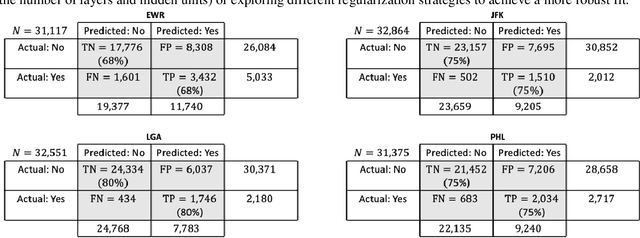
This paper proposes a novel approach to predict and determine whether the average taxi- out time at an airport will exceed a pre-defined threshold within the next hour of operations. Prior work in this domain has focused exclusively on predicting taxi-out times on a flight-by-flight basis, which requires significant efforts and data on modeling taxiing activities from gates to runways. Learning directly from surface radar information with minimal processing, a computer vision-based model is proposed that incorporates airport surface data in such a way that adaptation-specific information (e.g., runway configuration, the state of aircraft in the taxiing process) is inferred implicitly and automatically by Artificial Intelligence (AI).
Multi-Airport Delay Prediction with Transformers
Nov 04, 2021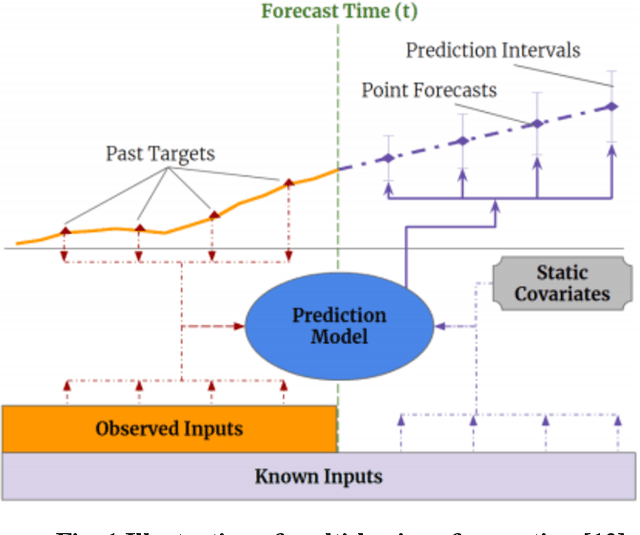
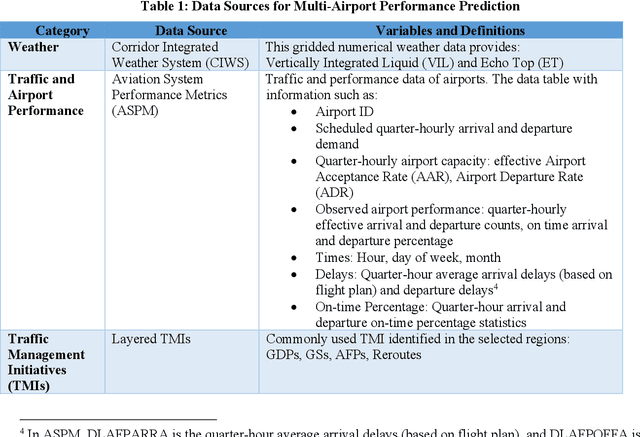
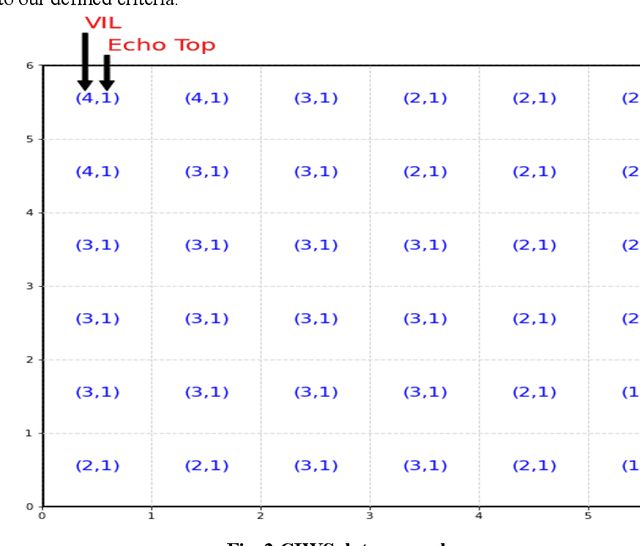
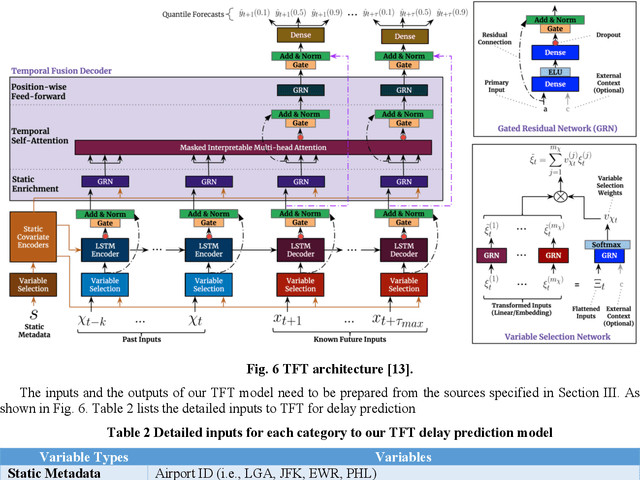
Airport performance prediction with a reasonable look-ahead time is a challenging task and has been attempted by various prior research. Traffic, demand, weather, and traffic management actions are all critical inputs to any prediction model. In this paper, a novel approach based on Temporal Fusion Transformer (TFT) was proposed to predict departure and arrival delays simultaneously for multiple airports at once. This approach can capture complex temporal dynamics of the inputs known at the time of prediction and then forecast selected delay metrics up to four hours into the future. When dealing with weather inputs, a self-supervised learning (SSL) model was developed to encode high-dimensional weather data into a much lower-dimensional representation to make the training of TFT more efficiently and effectively. The initial results show that the TFT-based delay prediction model achieves satisfactory performance measured by smaller prediction errors on a testing dataset. In addition, the interpretability analysis of the model outputs identifies the important input factors for delay prediction. The proposed approach is expected to help air traffic managers or decision makers gain insights about traffic management actions on delay mitigation and once operationalized, provide enough lead time to plan for predicted performance degradation.