 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoCodeBench: Large Language Models are Automatic Code Benchmark Generators
Aug 12, 2025



Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains, with code generation emerging as a key area of focus. While numerous benchmarks have been proposed to evaluate their code generation abilities, these benchmarks face several critical limitations. First, they often rely on manual annotations, which are time-consuming and difficult to scale across different programming languages and problem complexities. Second, most existing benchmarks focus primarily on Python, while the few multilingual benchmarks suffer from limited difficulty and uneven language distribution. To address these challenges, we propose AutoCodeGen, an automated method for generating high-difficulty multilingual code generation datasets without manual annotations. AutoCodeGen ensures the correctness and completeness of test cases by generating test inputs with LLMs and obtaining test outputs through a multilingual sandbox, while achieving high data quality through reverse-order problem generation and multiple filtering steps. Using this novel method, we introduce AutoCodeBench, a large-scale code generation benchmark comprising 3,920 problems evenly distributed across 20 programming languages. It is specifically designed to evaluate LLMs on challenging, diverse, and practical multilingual tasks. We evaluate over 30 leading open-source and proprietary LLMs on AutoCodeBench and its simplified version AutoCodeBench-Lite. The results show that even the most advanced LLMs struggle with the complexity, diversity, and multilingual nature of these tasks. Besides, we introduce AutoCodeBench-Complete, specifically designed for base models to assess their few-shot code generation capabilities. We hope the AutoCodeBench series will serve as a valuable resource and inspire the community to focus on more challenging and practical multilingual code generation scenarios.
AviationGPT: A Large Language Model for the Aviation Domain
Nov 29, 2023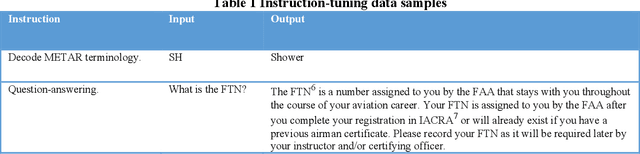
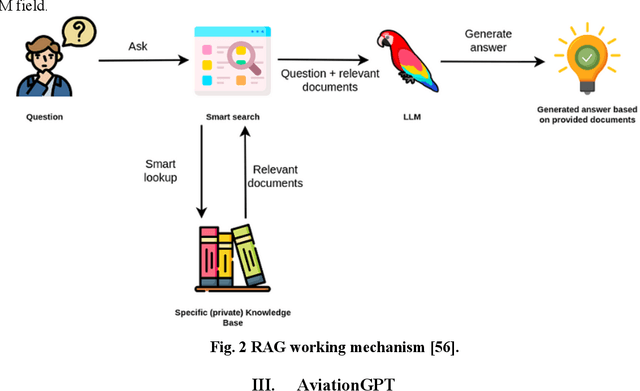
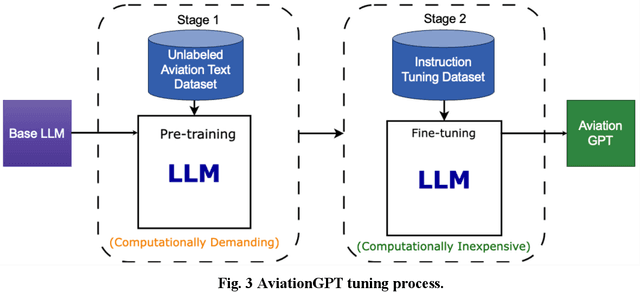
The advent of ChatGPT and GPT-4 has captivated the world with large language models (LLMs), demonstrating exceptional performance in question-answering, summarization, and content generation. The aviation industry is characterized by an abundance of complex, unstructured text data, replete with technical jargon and specialized terminology. Moreover, labeled data for model building are scarce in this domain, resulting in low usage of aviation text data. The emergence of LLMs presents an opportunity to transform this situation, but there is a lack of LLMs specifically designed for the aviation domain. To address this gap, we propose AviationGPT, which is built on open-source LLaMA-2 and Mistral architectures and continuously trained on a wealth of carefully curated aviation datasets. Experimental results reveal that AviationGPT offers users multiple advantages, including the versatility to tackle diverse natural language processing (NLP) problems (e.g., question-answering, summarization, document writing, information extraction, report querying, data cleaning, and interactive data exploration). It also provides accurate and contextually relevant responses within the aviation domain and significantly improves performance (e.g., over a 40% performance gain in tested cases). With AviationGPT, the aviation industry is better equipped to address more complex research problems and enhance the efficiency and safety of National Airspace System (NAS) operations.
Adapting Sentence Transformers for the Aviation Domain
May 16, 2023


Learning effective sentence representations is crucial for many Natural Language Processing (NLP) tasks, including semantic search, semantic textual similarity (STS), and clustering. While multiple transformer models have been developed for sentence embedding learning, these models may not perform optimally when dealing with specialized domains like aviation, which has unique characteristics such as technical jargon, abbreviations, and unconventional grammar. Furthermore, the absence of labeled datasets makes it difficult to train models specifically for the aviation domain. To address these challenges, we propose a novel approach for adapting sentence transformers for the aviation domain. Our method is a two-stage process consisting of pre-training followed by fine-tuning. During pre-training, we use Transformers and Sequential Denoising AutoEncoder (TSDAE) with aviation text data as input to improve the initial model performance. Subsequently, we fine-tune our models using a Natural Language Inference (NLI) dataset in the Sentence Bidirectional Encoder Representations from Transformers (SBERT) architecture to mitigate overfitting issues. Experimental results on several downstream tasks show that our adapted sentence transformers significantly outperform general-purpose transformers, demonstrating the effectiveness of our approach in capturing the nuances of the aviation domain. Overall, our work highlights the importance of domain-specific adaptation in developing high-quality NLP solutions for specialized industries like aviation.
Multi-Airport Delay Prediction with Transformers
Nov 04, 2021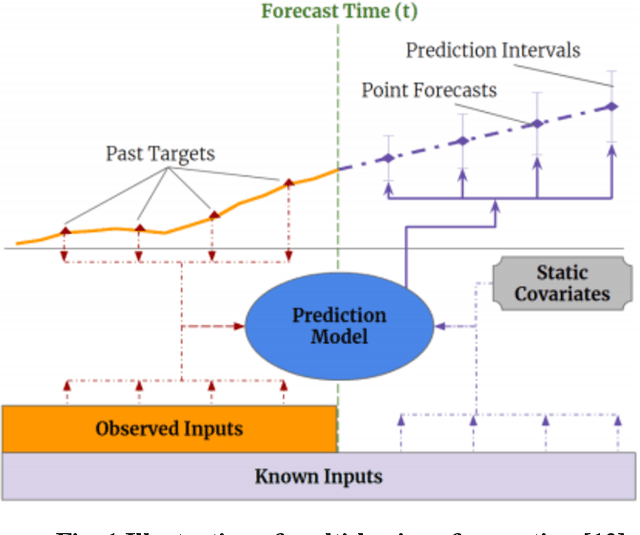
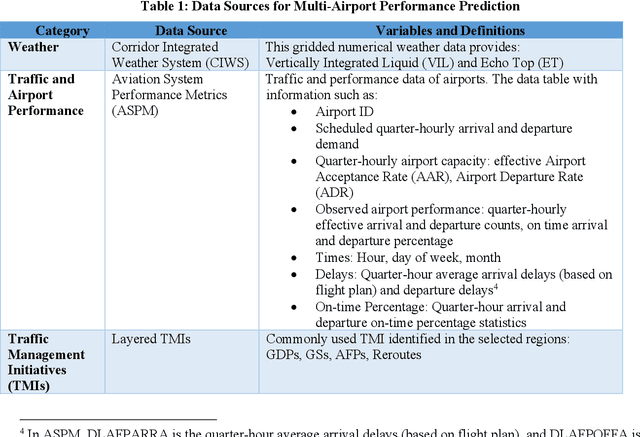
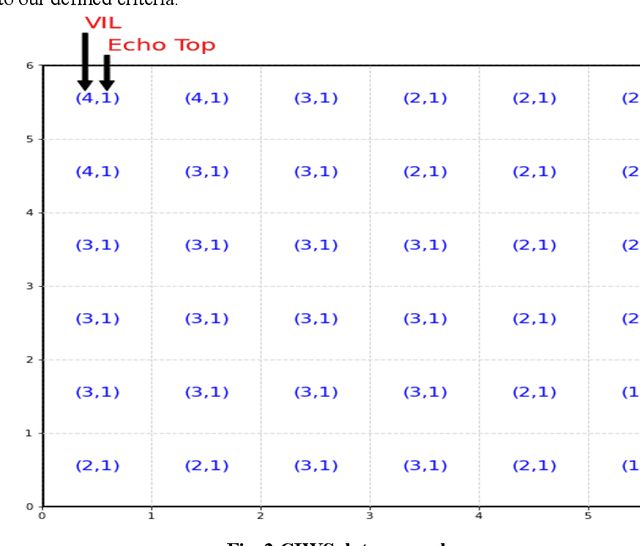
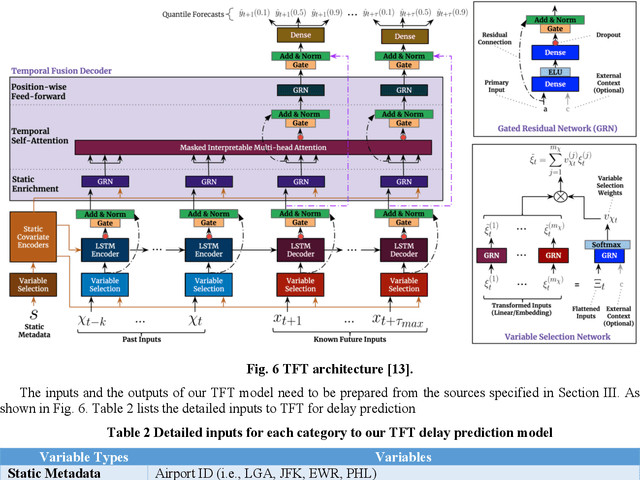
Airport performance prediction with a reasonable look-ahead time is a challenging task and has been attempted by various prior research. Traffic, demand, weather, and traffic management actions are all critical inputs to any prediction model. In this paper, a novel approach based on Temporal Fusion Transformer (TFT) was proposed to predict departure and arrival delays simultaneously for multiple airports at once. This approach can capture complex temporal dynamics of the inputs known at the time of prediction and then forecast selected delay metrics up to four hours into the future. When dealing with weather inputs, a self-supervised learning (SSL) model was developed to encode high-dimensional weather data into a much lower-dimensional representation to make the training of TFT more efficiently and effectively. The initial results show that the TFT-based delay prediction model achieves satisfactory performance measured by smaller prediction errors on a testing dataset. In addition, the interpretability analysis of the model outputs identifies the important input factors for delay prediction. The proposed approach is expected to help air traffic managers or decision makers gain insights about traffic management actions on delay mitigation and once operationalized, provide enough lead time to plan for predicted performance degradation.
Generated Loss and Augmented Training of MNIST VAE
Apr 24, 2019



The variational autoencoder (VAE) framework is a popular option for training unsupervised generative models, featuring ease of training and latent representation of data. The objective function of VAE does not guarantee to achieve the latter, however, and failure to do so leads to a frequent failure mode called posterior collapse. Even in successful cases, VAEs often result in low-precision reconstructions and generated samples. The introduction of the KL-divergence weight $\beta$ can help steer the model clear of posterior collapse, but its tuning is often a trial-and-error process with no guiding metrics. Here we test the idea of using the total VAE loss of generated samples (generated loss) as the proxy metric for generation quality, the related hypothesis that VAE reconstruction from the mean latent vector tends to be a more typical example of its class than the original, and the idea of exploiting this property by augmenting training data with generated variants (augmented training). The results are mixed, but repeated encoding and decoding indeed result in qualitatively and quantitatively more typical examples from both convolutional and fully-connected MNIST VAEs, suggesting that it may be an inherent property of the VAE framework.
Generated Loss, Augmented Training, and Multiscale VAE
Apr 23, 2019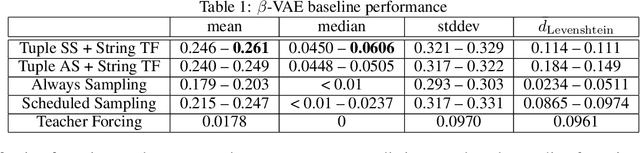



The variational autoencoder (VAE) framework remains a popular option for training unsupervised generative models, especially for discrete data where generative adversarial networks (GANs) require workaround to create gradient for the generator. In our work modeling US postal addresses, we show that our discrete VAE with tree recursive architecture demonstrates limited capability of capturing field correlations within structured data, even after overcoming the challenge of posterior collapse with scheduled sampling and tuning of the KL-divergence weight $\beta$. Worse, VAE seems to have difficulty mapping its generated samples to the latent space, as their VAE loss lags behind or even increases during the training process. Motivated by this observation, we show that augmenting training data with generated variants (augmented training) and training a VAE with multiple values of $\beta$ simultaneously (multiscale VAE) both improve the generation quality of VAE. Despite their differences in motivation and emphasis, we show that augmented training and multiscale VAE are actually connected and have similar effects on the model.