 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Predictive Modelling under Imbalanced Distributions
May 13, 2015
Many real world data mining applications involve obtaining predictive models using data sets with strongly imbalanced distributions of the target variable. Frequently, the least common values of this target variable are associated with events that are highly relevant for end users (e.g. fraud detection, unusual returns on stock markets, anticipation of catastrophes, etc.). Moreover, the events may have different costs and benefits, which when associated with the rarity of some of them on the available training data creates serious problems to predictive modelling techniques. This paper presents a survey of existing techniques for handling these important applications of predictive analytics. Although most of the existing work addresses classification tasks (nominal target variables), we also describe methods designed to handle similar problems within regression tasks (numeric target variables). In this survey we discuss the main challenges raised by imbalanced distributions, describe the main approaches to these problems, propose a taxonomy of these methods and refer to some related problems within predictive modelling.
Pattern Recognition in Collective Cognitive Systems: Hybrid Human-Machine Learning (HHML) By Heterogeneous Ensembles
Aug 31, 2010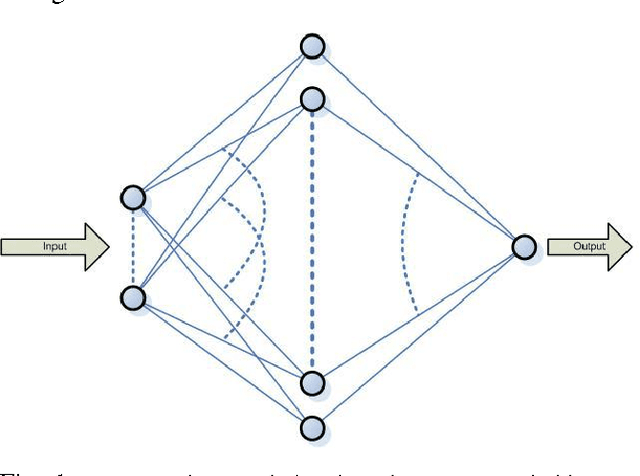
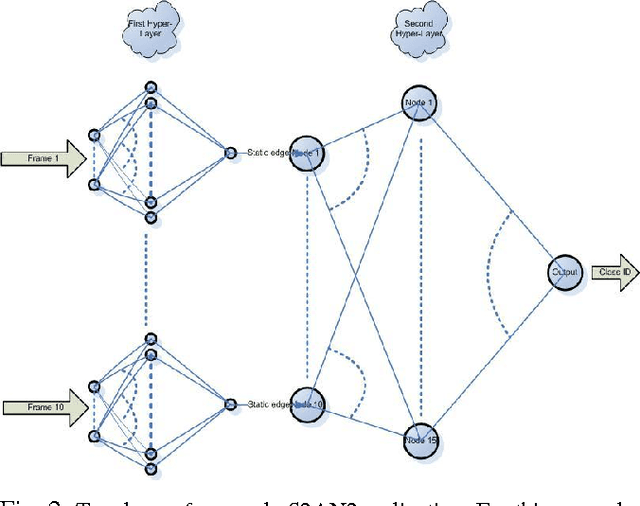
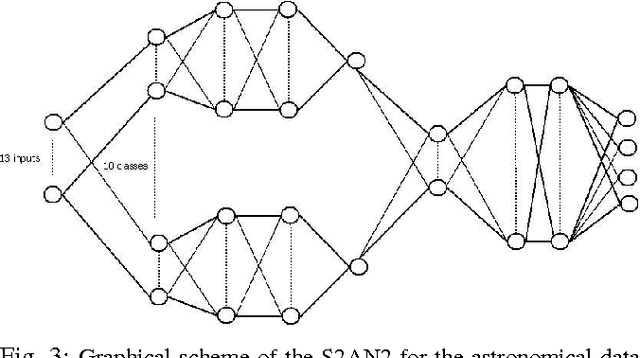
The ubiquitous role of the cyber-infrastructures, such as the WWW, provides myriad opportunities for machine learning and its broad spectrum of application domains taking advantage of digital communication. Pattern classification and feature extraction are among the first applications of machine learning that have received extensive attention. The most remarkable achievements have addressed data sets of moderate-to-large size. The 'data deluge' in the last decade or two has posed new challenges for AI researchers to design new, effective and accurate algorithms for similar tasks using ultra-massive data sets and complex (natural or synthetic) dynamical systems. We propose a novel principled approach to feature extraction in hybrid architectures comprised of humans and machines in networked communication, who collaborate to solve a pre-assigned pattern recognition (feature extraction) task. There are two practical considerations addressed below: (1) Human experts, such as plant biologists or astronomers, often use their visual perception and other implicit prior knowledge or expertise without any obvious constraints to search for the significant features, whereas machines are limited to a pre-programmed set of criteria to work with; (2) in a team collaboration of collective problem solving, the human experts have diverse abilities that are complementary, and they learn from each other to succeed in cognitively complex tasks in ways that are still impossible imitate by machines.
* International Conference on Artificial Intelligence, WorldComp 2010