 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSV-TrustEval-C: Evaluating Structure and Semantic Reasoning in Large Language Models for Source Code Vulnerability Analysis
May 27, 2025As Large Language Models (LLMs) evolve in understanding and generating code, accurately evaluating their reliability in analyzing source code vulnerabilities becomes increasingly vital. While studies have examined LLM capabilities in tasks like vulnerability detection and repair, they often overlook the importance of both structure and semantic reasoning crucial for trustworthy vulnerability analysis. To address this gap, we introduce SV-TrustEval-C, a benchmark designed to evaluate LLMs' abilities for vulnerability analysis of code written in the C programming language through two key dimensions: structure reasoning - assessing how models identify relationships between code elements under varying data and control flow complexities; and semantic reasoning - examining their logical consistency in scenarios where code is structurally and semantically perturbed. Our results show that current LLMs are far from satisfactory in understanding complex code relationships and that their vulnerability analyses rely more on pattern matching than on robust logical reasoning. These findings underscore the effectiveness of the SV-TrustEval-C benchmark and highlight critical areas for enhancing the reasoning capabilities and trustworthiness of LLMs in real-world vulnerability analysis tasks. Our initial benchmark dataset is publicly available.
Generalized Attacks on Face Verification Systems
Sep 12, 2023



Face verification (FV) using deep neural network models has made tremendous progress in recent years, surpassing human accuracy and seeing deployment in various applications such as border control and smartphone unlocking. However, FV systems are vulnerable to Adversarial Attacks, which manipulate input images to deceive these systems in ways usually unnoticeable to humans. This paper provides an in-depth study of attacks on FV systems. We introduce the DodgePersonation Attack that formulates the creation of face images that impersonate a set of given identities while avoiding being identified as any of the identities in a separate, disjoint set. A taxonomy is proposed to provide a unified view of different types of Adversarial Attacks against FV systems, including Dodging Attacks, Impersonation Attacks, and Master Face Attacks. Finally, we propose the ''One Face to Rule Them All'' Attack which implements the DodgePersonation Attack with state-of-the-art performance on a well-known scenario (Master Face Attack) and which can also be used for the new scenarios introduced in this paper. While the state-of-the-art Master Face Attack can produce a set of 9 images to cover 43.82% of the identities in their test database, with 9 images our attack can cover 57.27% to 58.5% of these identifies while giving the attacker the choice of the identity to use to create the impersonation. Moreover, the 9 generated attack images appear identical to a casual observer.
An Empirical Study on Log-based Anomaly Detection Using Machine Learning
Jul 31, 2023The growth of systems complexity increases the need of automated techniques dedicated to different log analysis tasks such as Log-based Anomaly Detection (LAD). The latter has been widely addressed in the literature, mostly by means of different deep learning techniques. Nevertheless, the focus on deep learning techniques results in less attention being paid to traditional Machine Learning (ML) techniques, which may perform well in many cases, depending on the context and the used datasets. Further, the evaluation of different ML techniques is mostly based on the assessment of their detection accuracy. However, this is is not enough to decide whether or not a specific ML technique is suitable to address the LAD problem. Other aspects to consider include the training and prediction time as well as the sensitivity to hyperparameter tuning. In this paper, we present a comprehensive empirical study, in which we evaluate different supervised and semi-supervised, traditional and deep ML techniques w.r.t. four evaluation criteria: detection accuracy, time performance, sensitivity of detection accuracy as well as time performance to hyperparameter tuning. The experimental results show that supervised traditional and deep ML techniques perform very closely in terms of their detection accuracy and prediction time. Moreover, the overall evaluation of the sensitivity of the detection accuracy of the different ML techniques to hyperparameter tuning shows that supervised traditional ML techniques are less sensitive to hyperparameter tuning than deep learning techniques. Further, semi-supervised techniques yield significantly worse detection accuracy than supervised techniques.
Measuring Improvement of F$_1$-Scores in Detection of Self-Admitted Technical Debt
Mar 16, 2023
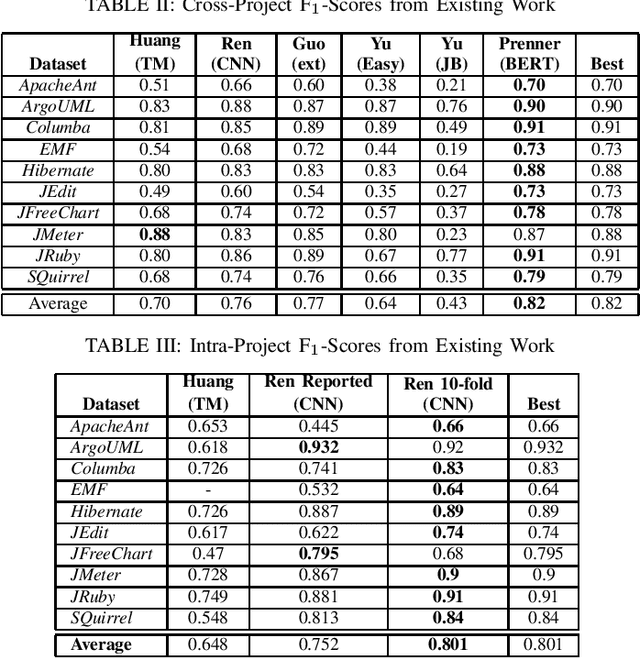
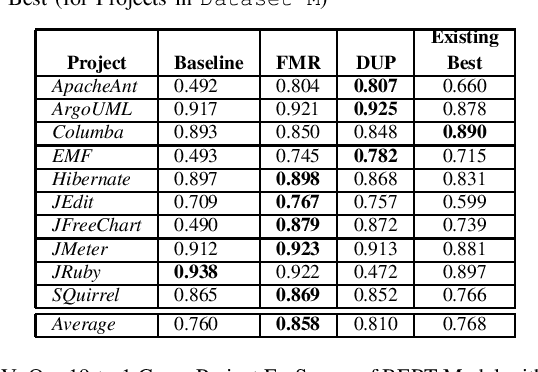
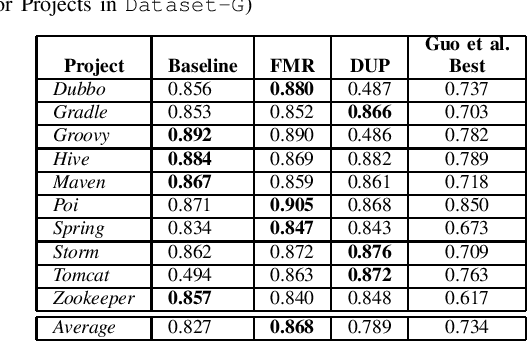
Artificial Intelligence and Machine Learning have witnessed rapid, significant improvements in Natural Language Processing (NLP) tasks. Utilizing Deep Learning, researchers have taken advantage of repository comments in Software Engineering to produce accurate methods for detecting Self-Admitted Technical Debt (SATD) from 20 open-source Java projects' code. In this work, we improve SATD detection with a novel approach that leverages the Bidirectional Encoder Representations from Transformers (BERT) architecture. For comparison, we re-evaluated previous deep learning methods and applied stratified 10-fold cross-validation to report reliable F$_1$-scores. We examine our model in both cross-project and intra-project contexts. For each context, we use re-sampling and duplication as augmentation strategies to account for data imbalance. We find that our trained BERT model improves over the best performance of all previous methods in 19 of the 20 projects in cross-project scenarios. However, the data augmentation techniques were not sufficient to overcome the lack of data present in the intra-project scenarios, and existing methods still perform better. Future research will look into ways to diversify SATD datasets in order to maximize the latent power in large BERT models.
Adversarial Robustness of Neural-Statistical Features in Detection of Generative Transformers
Mar 02, 2022
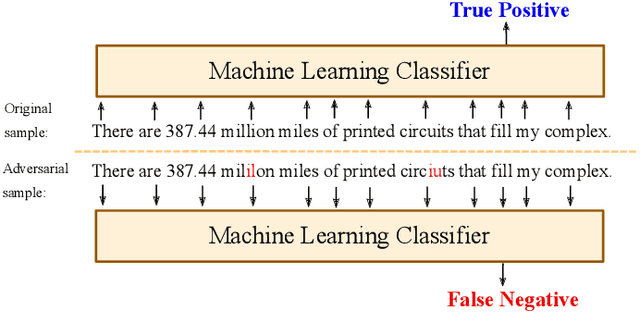
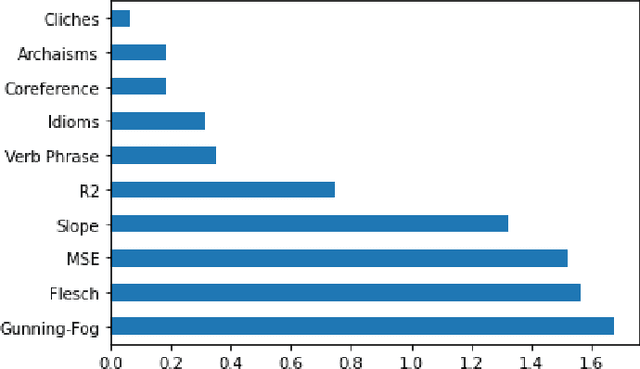
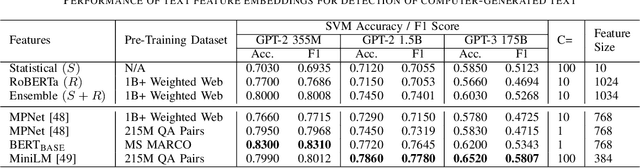
The detection of computer-generated text is an area of rapidly increasing significance as nascent generative models allow for efficient creation of compelling human-like text, which may be abused for the purposes of spam, disinformation, phishing, or online influence campaigns. Past work has studied detection of current state-of-the-art models, but despite a developing threat landscape, there has been minimal analysis of the robustness of detection methods to adversarial attacks. To this end, we evaluate neural and non-neural approaches on their ability to detect computer-generated text, their robustness against text adversarial attacks, and the impact that successful adversarial attacks have on human judgement of text quality. We find that while statistical features underperform neural features, statistical features provide additional adversarial robustness that can be leveraged in ensemble detection models. In the process, we find that previously effective complex phrasal features for detection of computer-generated text hold little predictive power against contemporary generative models, and identify promising statistical features to use instead. Finally, we pioneer the usage of $\Delta$MAUVE as a proxy measure for human judgement of adversarial text quality.
Graph-based Solutions with Residuals for Intrusion Detection: the Modified E-GraphSAGE and E-ResGAT Algorithms
Nov 26, 2021
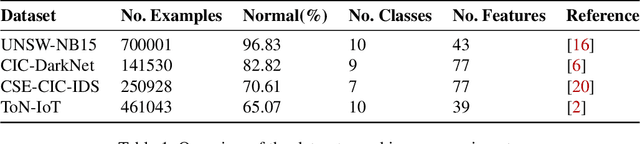
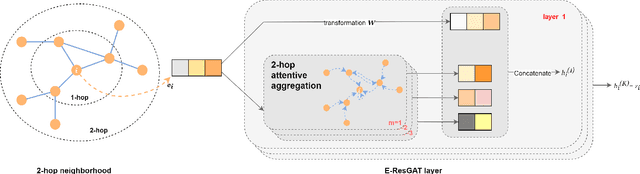

The high volume of increasingly sophisticated cyber threats is drawing growing attention to cybersecurity, where many challenges remain unresolved. Namely, for intrusion detection, new algorithms that are more robust, effective, and able to use more information are needed. Moreover, the intrusion detection task faces a serious challenge associated with the extreme class imbalance between normal and malicious traffics. Recently, graph-neural network (GNN) achieved state-of-the-art performance to model the network topology in cybersecurity tasks. However, only a few works exist using GNNs to tackle the intrusion detection problem. Besides, other promising avenues such as applying the attention mechanism are still under-explored. This paper presents two novel graph-based solutions for intrusion detection, the modified E-GraphSAGE, and E-ResGATalgorithms, which rely on the established GraphSAGE and graph attention network (GAT), respectively. The key idea is to integrate residual learning into the GNN leveraging the available graph information. Residual connections are added as a strategy to deal with the high-class imbalance, aiming at retaining the original information and improving the minority classes' performance. An extensive experimental evaluation of four recent intrusion detection datasets shows the excellent performance of our approaches, especially when predicting minority classes.
UBL: an R package for Utility-based Learning
Jul 12, 2016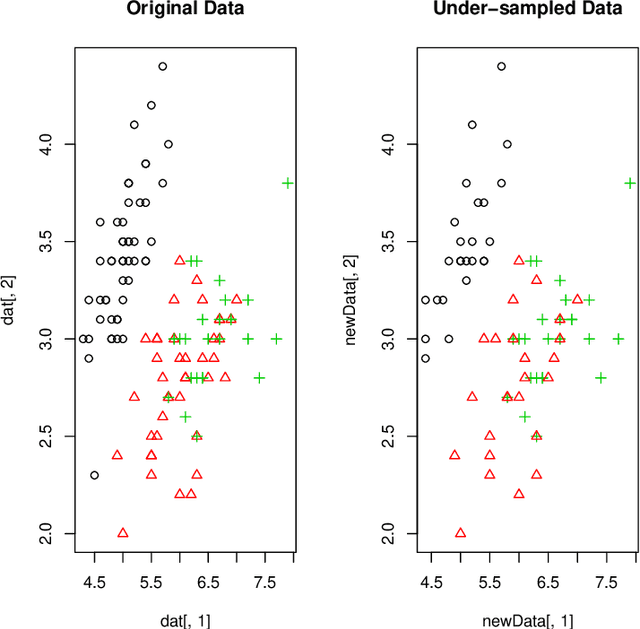

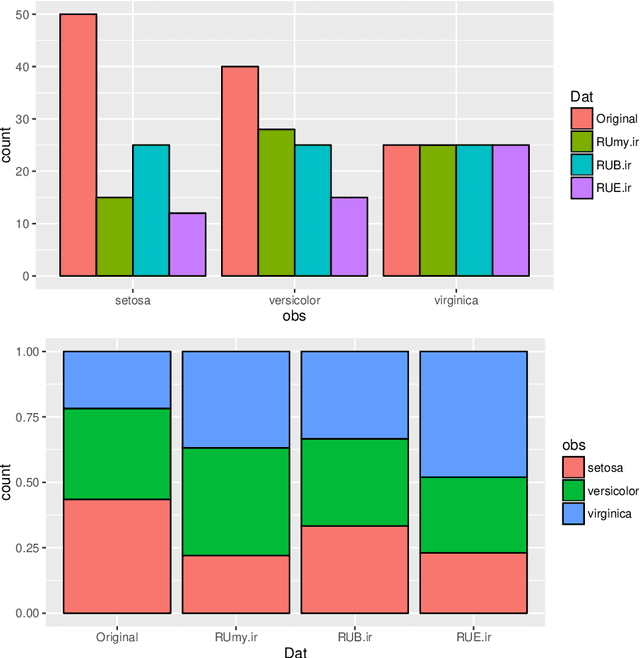

This document describes the R package UBL that allows the use of several methods for handling utility-based learning problems. Classification and regression problems that assume non-uniform costs and/or benefits pose serious challenges to predictive analytic tasks. In the context of meteorology, finance, medicine, ecology, among many other, specific domain information concerning the preference bias of the users must be taken into account to enhance the models predictive performance. To deal with this problem, a large number of techniques was proposed by the research community for both classification and regression tasks. The main goal of UBL package is to facilitate the utility-based predictive analytic task by providing a set of methods to deal with this type of problems in the R environment. It is a versatile tool that provides mechanisms to handle both regression and classification (binary and multiclass) tasks. Moreover, UBL package allows the user to specify his domain preferences, but it also provides some automatic methods that try to infer those preference bias from the domain, considering some common known settings.
A Survey of Predictive Modelling under Imbalanced Distributions
May 13, 2015
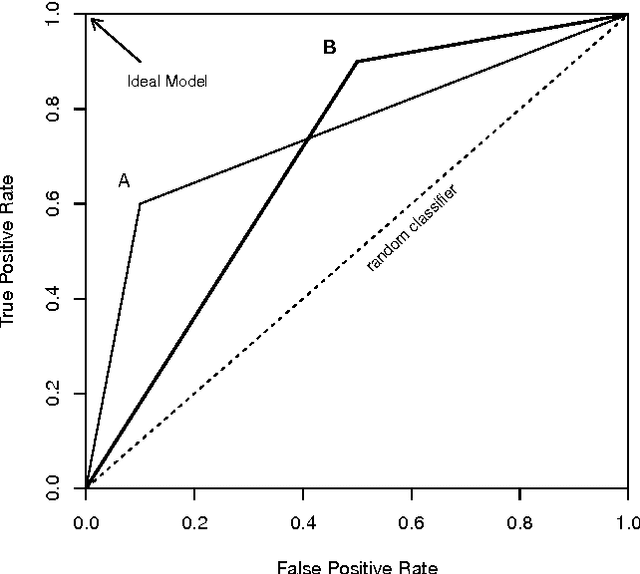
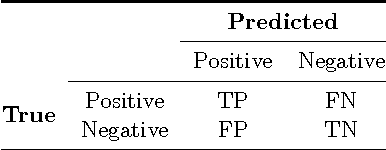
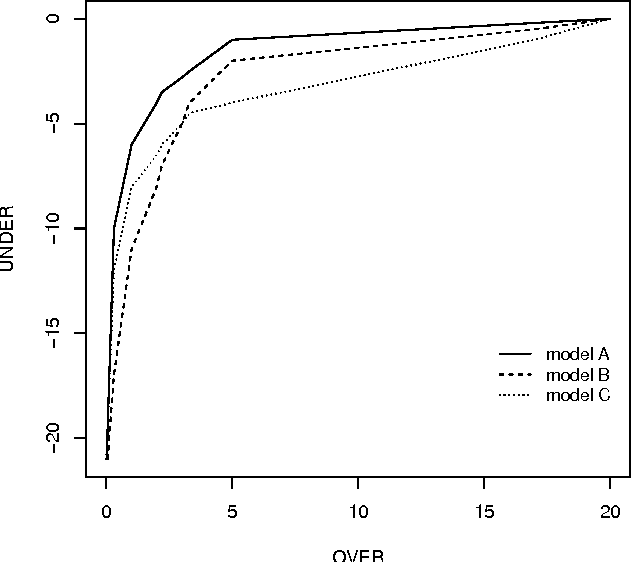
Many real world data mining applications involve obtaining predictive models using data sets with strongly imbalanced distributions of the target variable. Frequently, the least common values of this target variable are associated with events that are highly relevant for end users (e.g. fraud detection, unusual returns on stock markets, anticipation of catastrophes, etc.). Moreover, the events may have different costs and benefits, which when associated with the rarity of some of them on the available training data creates serious problems to predictive modelling techniques. This paper presents a survey of existing techniques for handling these important applications of predictive analytics. Although most of the existing work addresses classification tasks (nominal target variables), we also describe methods designed to handle similar problems within regression tasks (numeric target variables). In this survey we discuss the main challenges raised by imbalanced distributions, describe the main approaches to these problems, propose a taxonomy of these methods and refer to some related problems within predictive modelling.