 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking XAI Evaluation: A Human-Centered Audit of Shapley Benchmarks in High-Stakes Settings
Apr 24, 2026Shapley values are a cornerstone of explainable AI, yet their proliferation into competing formulations has created a fragmented landscape with little consensus on practical deployment. While theoretical differences are well-documented, evaluation remains reliant on quantitative proxies whose alignment with human utility is unverified. In this work, we use a unified amortized framework to isolate semantic differences between eight Shapley variants under the low-latency constraints of operational risk workflows. We conduct a large-scale empirical evaluation across four risk datasets and a realistic fraud-detection environment involving professional analysts and 3,735 case reviews. Our results reveal a fundamental misalignment: standard quantitative metrics, such as sparsity and faithfulness, are decoupled from human-perceived clarity and decision utility. Furthermore, while no formulation improved objective analyst performance, explanations consistently increased decision confidence, signaling a critical risk of automation bias in high-stakes settings. These findings suggest that current evaluation proxies are insufficient for predicting downstream human impact, and we provide evidence-based guidance for selecting formulations and metrics in operational decision systems.
Histogram approaches for imbalanced data streams regression
Jan 29, 2025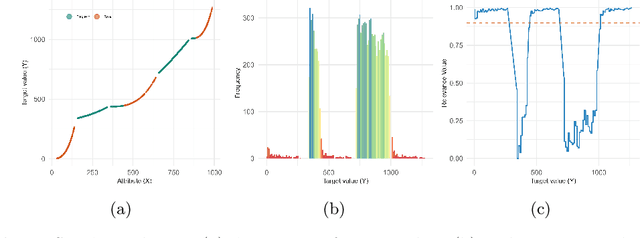
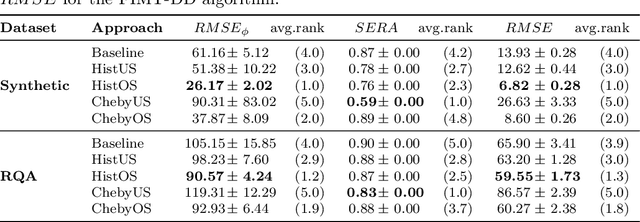
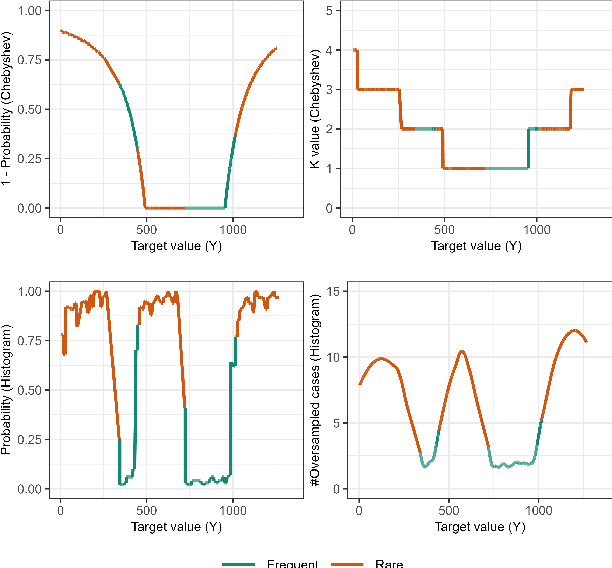
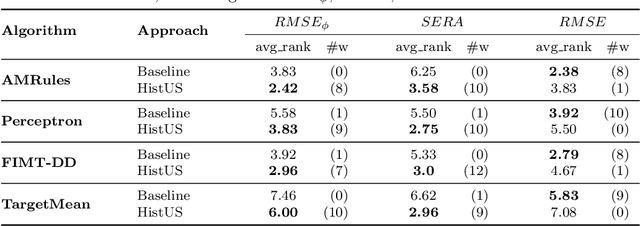
Handling imbalanced data streams in regression tasks presents a significant challenge, as rare instances can appear anywhere in the target distribution rather than being confined to its extreme values. In this paper, we introduce novel data-level sampling strategies, \texttt{HistUS} and \texttt{HistOS}, that utilize histogram-based approaches to dynamically balance data streams. Unlike previous methods based on Chebyshev\textquotesingle s inequality, our proposed techniques identify and handle rare cases across the entire distribution effectively. We demonstrate that \texttt{HistUS} and \texttt{HistOS} outperform traditional methods through extensive experiments on synthetic and real-world datasets, leading to more accurate and robust regression models in streaming environments.
Aequitas Flow: Streamlining Fair ML Experimentation
May 09, 2024Aequitas Flow is an open-source framework for end-to-end Fair Machine Learning (ML) experimentation in Python. This package fills the existing integration gaps in other Fair ML packages of complete and accessible experimentation. It provides a pipeline for fairness-aware model training, hyperparameter optimization, and evaluation, enabling rapid and simple experiments and result analysis. Aimed at ML practitioners and researchers, the framework offers implementations of methods, datasets, metrics, and standard interfaces for these components to improve extensibility. By facilitating the development of fair ML practices, Aequitas Flow seeks to enhance the adoption of these concepts in AI technologies.
A Neuro-Symbolic Explainer for Rare Events: A Case Study on Predictive Maintenance
Apr 21, 2024



Predictive Maintenance applications are increasingly complex, with interactions between many components. Black box models are popular approaches based on deep learning techniques due to their predictive accuracy. This paper proposes a neural-symbolic architecture that uses an online rule-learning algorithm to explain when the black box model predicts failures. The proposed system solves two problems in parallel: anomaly detection and explanation of the anomaly. For the first problem, we use an unsupervised state of the art autoencoder. For the second problem, we train a rule learning system that learns a mapping from the input features to the autoencoder reconstruction error. Both systems run online and in parallel. The autoencoder signals an alarm for the examples with a reconstruction error that exceeds a threshold. The causes of the signal alarm are hard for humans to understand because they result from a non linear combination of sensor data. The rule that triggers that example describes the relationship between the input features and the autoencoder reconstruction error. The rule explains the failure signal by indicating which sensors contribute to the alarm and allowing the identification of the component involved in the failure. The system can present global explanations for the black box model and local explanations for why the black box model predicts a failure. We evaluate the proposed system in a real-world case study of Metro do Porto and provide explanations that illustrate its benefits.
Super-Resolution Analysis for Landfill Waste Classification
Apr 02, 2024Illegal landfills are a critical issue due to their environmental, economic, and public health impacts. This study leverages aerial imagery for environmental crime monitoring. While advances in artificial intelligence and computer vision hold promise, the challenge lies in training models with high-resolution literature datasets and adapting them to open-access low-resolution images. Considering the substantial quality differences and limited annotation, this research explores the adaptability of models across these domains. Motivated by the necessity for a comprehensive evaluation of waste detection algorithms, it advocates cross-domain classification and super-resolution enhancement to analyze the impact of different image resolutions on waste classification as an evaluation to combat the proliferation of illegal landfills. We observed performance improvements by enhancing image quality but noted an influence on model sensitivity, necessitating careful threshold fine-tuning.
Explainable Predictive Maintenance
Jun 08, 2023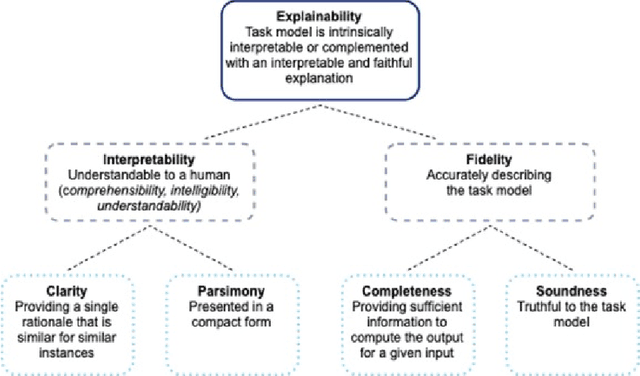

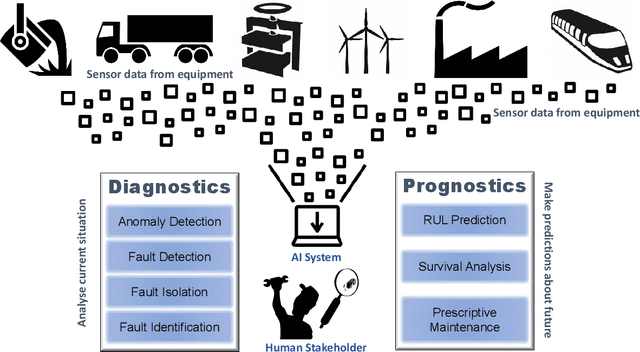
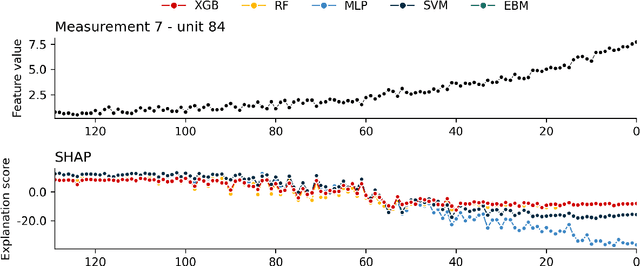
Explainable Artificial Intelligence (XAI) fills the role of a critical interface fostering interactions between sophisticated intelligent systems and diverse individuals, including data scientists, domain experts, end-users, and more. It aids in deciphering the intricate internal mechanisms of ``black box'' Machine Learning (ML), rendering the reasons behind their decisions more understandable. However, current research in XAI primarily focuses on two aspects; ways to facilitate user trust, or to debug and refine the ML model. The majority of it falls short of recognising the diverse types of explanations needed in broader contexts, as different users and varied application areas necessitate solutions tailored to their specific needs. One such domain is Predictive Maintenance (PdM), an exploding area of research under the Industry 4.0 \& 5.0 umbrella. This position paper highlights the gap between existing XAI methodologies and the specific requirements for explanations within industrial applications, particularly the Predictive Maintenance field. Despite explainability's crucial role, this subject remains a relatively under-explored area, making this paper a pioneering attempt to bring relevant challenges to the research community's attention. We provide an overview of predictive maintenance tasks and accentuate the need and varying purposes for corresponding explanations. We then list and describe XAI techniques commonly employed in the literature, discussing their suitability for PdM tasks. Finally, to make the ideas and claims more concrete, we demonstrate XAI applied in four specific industrial use cases: commercial vehicles, metro trains, steel plants, and wind farms, spotlighting areas requiring further research.
Turning the Tables: Biased, Imbalanced, Dynamic Tabular Datasets for ML Evaluation
Nov 28, 2022Evaluating new techniques on realistic datasets plays a crucial role in the development of ML research and its broader adoption by practitioners. In recent years, there has been a significant increase of publicly available unstructured data resources for computer vision and NLP tasks. However, tabular data -- which is prevalent in many high-stakes domains -- has been lagging behind. To bridge this gap, we present Bank Account Fraud (BAF), the first publicly available privacy-preserving, large-scale, realistic suite of tabular datasets. The suite was generated by applying state-of-the-art tabular data generation techniques on an anonymized,real-world bank account opening fraud detection dataset. This setting carries a set of challenges that are commonplace in real-world applications, including temporal dynamics and significant class imbalance. Additionally, to allow practitioners to stress test both performance and fairness of ML methods, each dataset variant of BAF contains specific types of data bias. With this resource, we aim to provide the research community with a more realistic, complete, and robust test bed to evaluate novel and existing methods.
A Benchmark dataset for predictive maintenance
Jul 18, 2022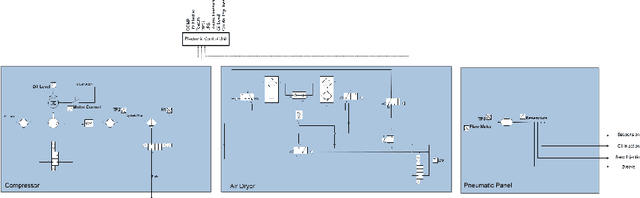
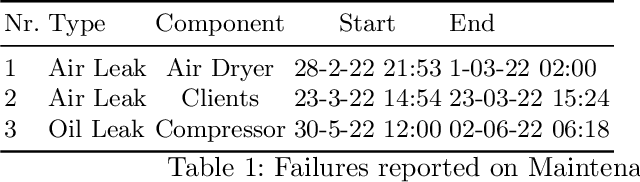
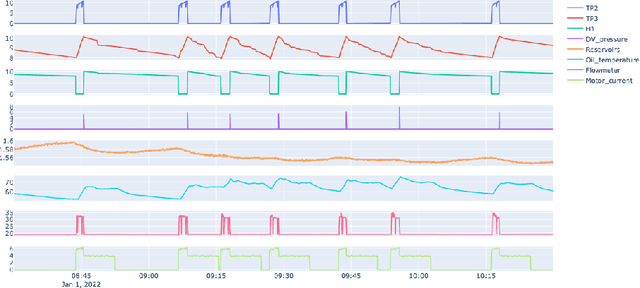
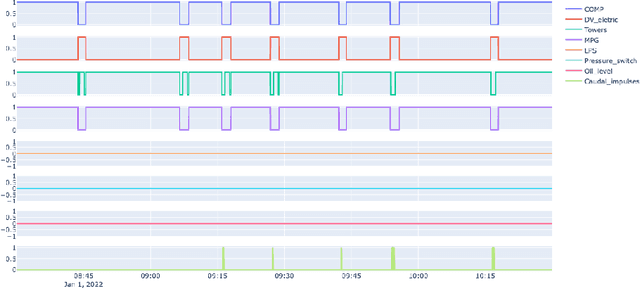
The paper describes the MetroPT data set, an outcome of a eXplainable Predictive Maintenance (XPM) project with an urban metro public transportation service in Porto, Portugal. The data was collected in 2022 that aimed to evaluate machine learning methods for online anomaly detection and failure prediction. By capturing several analogic sensor signals (pressure, temperature, current consumption), digital signals (control signals, discrete signals), and GPS information (latitude, longitude, and speed), we provide a dataset that can be easily used to evaluate online machine learning methods. This dataset contains some interesting characteristics and can be a good benchmark for predictive maintenance models.
Model Optimization in Imbalanced Regression
Jun 20, 2022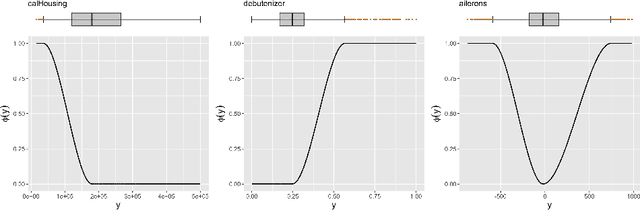
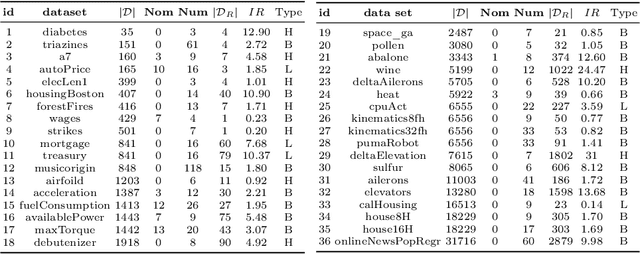

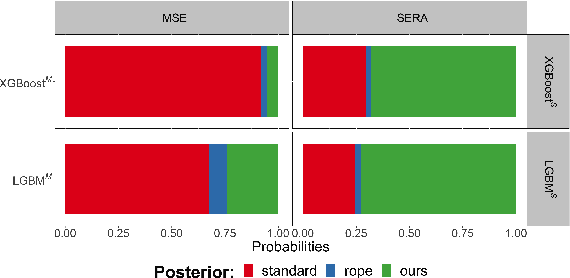
Imbalanced domain learning aims to produce accurate models in predicting instances that, though underrepresented, are of utmost importance for the domain. Research in this field has been mainly focused on classification tasks. Comparatively, the number of studies carried out in the context of regression tasks is negligible. One of the main reasons for this is the lack of loss functions capable of focusing on minimizing the errors of extreme (rare) values. Recently, an evaluation metric was introduced: Squared Error Relevance Area (SERA). This metric posits a bigger emphasis on the errors committed at extreme values while also accounting for the performance in the overall target variable domain, thus preventing severe bias. However, its effectiveness as an optimization metric is unknown. In this paper, our goal is to study the impacts of using SERA as an optimization criterion in imbalanced regression tasks. Using gradient boosting algorithms as proof of concept, we perform an experimental study with 36 data sets of different domains and sizes. Results show that models that used SERA as an objective function are practically better than the models produced by their respective standard boosting algorithms at the prediction of extreme values. This confirms that SERA can be embedded as a loss function into optimization-based learning algorithms for imbalanced regression scenarios.
UBL: an R package for Utility-based Learning
Jul 12, 2016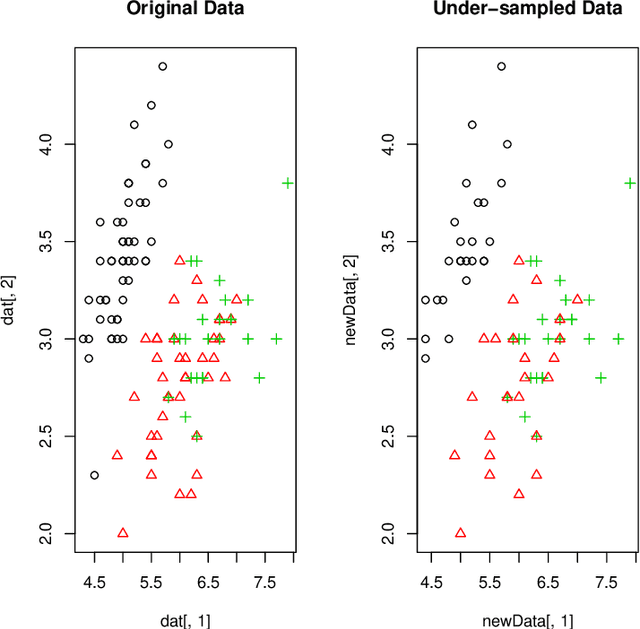

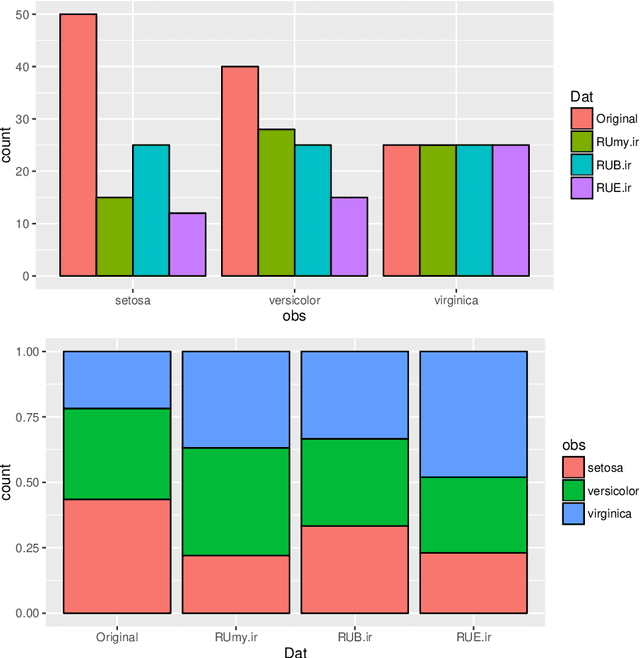

This document describes the R package UBL that allows the use of several methods for handling utility-based learning problems. Classification and regression problems that assume non-uniform costs and/or benefits pose serious challenges to predictive analytic tasks. In the context of meteorology, finance, medicine, ecology, among many other, specific domain information concerning the preference bias of the users must be taken into account to enhance the models predictive performance. To deal with this problem, a large number of techniques was proposed by the research community for both classification and regression tasks. The main goal of UBL package is to facilitate the utility-based predictive analytic task by providing a set of methods to deal with this type of problems in the R environment. It is a versatile tool that provides mechanisms to handle both regression and classification (binary and multiclass) tasks. Moreover, UBL package allows the user to specify his domain preferences, but it also provides some automatic methods that try to infer those preference bias from the domain, considering some common known settings.