 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffCAP: Diffusion-based Cumulative Adversarial Purification for Vision Language Models
Jun 04, 2025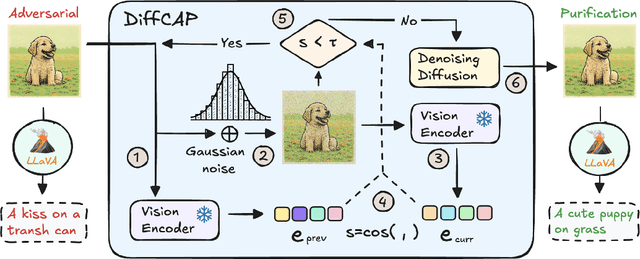
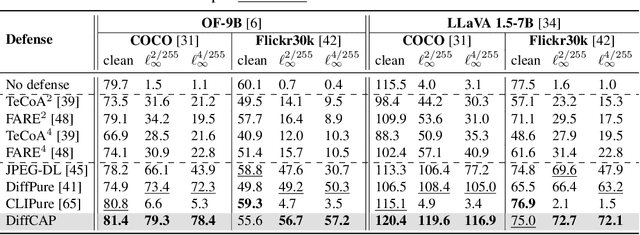
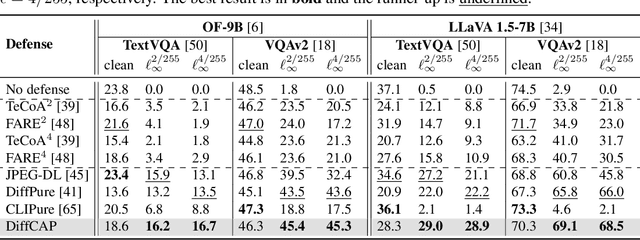
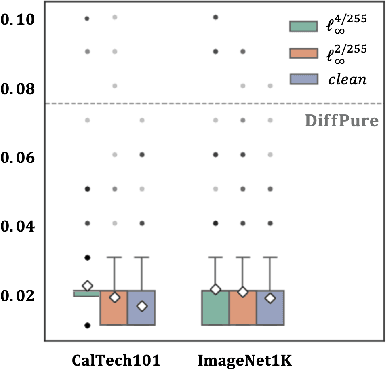
Vision Language Models (VLMs) have shown remarkable capabilities in multimodal understanding, yet their susceptibility to perturbations poses a significant threat to their reliability in real-world applications. Despite often being imperceptible to humans, these perturbations can drastically alter model outputs, leading to erroneous interpretations and decisions. This paper introduces DiffCAP, a novel diffusion-based purification strategy that can effectively neutralize adversarial corruptions in VLMs. We observe that adding minimal noise to an adversarially corrupted image significantly alters its latent embedding with respect to VLMs. Building on this insight, DiffCAP cumulatively injects random Gaussian noise into adversarially perturbed input data. This process continues until the embeddings of two consecutive noisy images reach a predefined similarity threshold, indicating a potential approach to neutralize the adversarial effect. Subsequently, a pretrained diffusion model is employed to denoise the stabilized image, recovering a clean representation suitable for the VLMs to produce an output. Through extensive experiments across six datasets with three VLMs under varying attack strengths in three task scenarios, we show that DiffCAP consistently outperforms existing defense techniques by a substantial margin. Notably, DiffCAP significantly reduces both hyperparameter tuning complexity and the required diffusion time, thereby accelerating the denoising process. Equipped with strong theoretical and empirical support, DiffCAP provides a robust and practical solution for securely deploying VLMs in adversarial environments.
DiffPAD: Denoising Diffusion-based Adversarial Patch Decontamination
Oct 31, 2024In the ever-evolving adversarial machine learning landscape, developing effective defenses against patch attacks has become a critical challenge, necessitating reliable solutions to safeguard real-world AI systems. Although diffusion models have shown remarkable capacity in image synthesis and have been recently utilized to counter $\ell_p$-norm bounded attacks, their potential in mitigating localized patch attacks remains largely underexplored. In this work, we propose DiffPAD, a novel framework that harnesses the power of diffusion models for adversarial patch decontamination. DiffPAD first performs super-resolution restoration on downsampled input images, then adopts binarization, dynamic thresholding scheme and sliding window for effective localization of adversarial patches. Such a design is inspired by the theoretically derived correlation between patch size and diffusion restoration error that is generalized across diverse patch attack scenarios. Finally, DiffPAD applies inpainting techniques to the original input images with the estimated patch region being masked. By integrating closed-form solutions for super-resolution restoration and image inpainting into the conditional reverse sampling process of a pre-trained diffusion model, DiffPAD obviates the need for text guidance or fine-tuning. Through comprehensive experiments, we demonstrate that DiffPAD not only achieves state-of-the-art adversarial robustness against patch attacks but also excels in recovering naturalistic images without patch remnants.
CoxSE: Exploring the Potential of Self-Explaining Neural Networks with Cox Proportional Hazards Model for Survival Analysis
Jul 18, 2024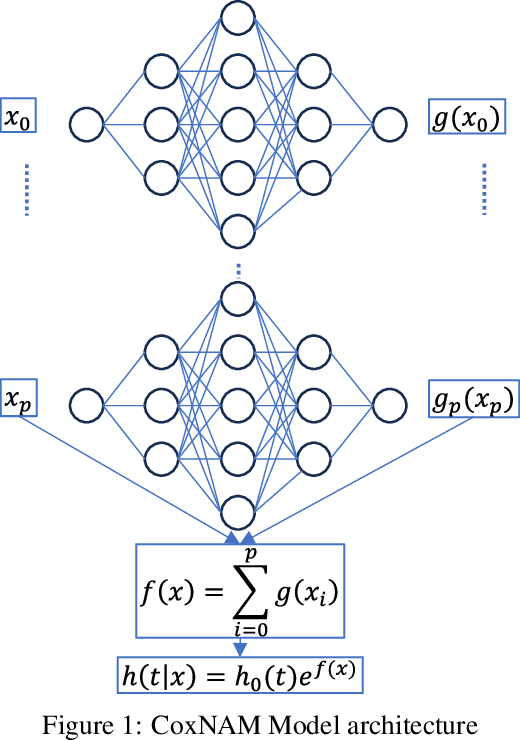



The Cox Proportional Hazards (CPH) model has long been the preferred survival model for its explainability. However, to increase its predictive power beyond its linear log-risk, it was extended to utilize deep neural networks sacrificing its explainability. In this work, we explore the potential of self-explaining neural networks (SENN) for survival analysis. we propose a new locally explainable Cox proportional hazards model, named CoxSE, by estimating a locally-linear log-hazard function using the SENN. We also propose a modification to the Neural additive (NAM) models hybrid with SENN, named CoxSENAM, which enables the control of the stability and consistency of the generated explanations. Several experiments using synthetic and real datasets have been performed comparing with a NAM-based model, DeepSurv model explained with SHAP, and a linear CPH model. The results show that, unlike the NAM-based model, the SENN-based model can provide more stable and consistent explanations while maintaining the same expressiveness power of the black-box model. The results also show that, due to their structural design, NAM-based models demonstrated better robustness to non-informative features. Among these models, the hybrid model exhibited the best robustness.
Rolling the dice for better deep learning performance: A study of randomness techniques in deep neural networks
Apr 05, 2024



This paper investigates how various randomization techniques impact Deep Neural Networks (DNNs). Randomization, like weight noise and dropout, aids in reducing overfitting and enhancing generalization, but their interactions are poorly understood. The study categorizes randomness techniques into four types and proposes new methods: adding noise to the loss function and random masking of gradient updates. Using Particle Swarm Optimizer (PSO) for hyperparameter optimization, it explores optimal configurations across MNIST, FASHION-MNIST, CIFAR10, and CIFAR100 datasets. Over 30,000 configurations are evaluated, revealing data augmentation and weight initialization randomness as main performance contributors. Correlation analysis shows different optimizers prefer distinct randomization types. The complete implementation and dataset are available on GitHub.
Fast Genetic Algorithm for feature selection -- A qualitative approximation approach
Apr 05, 2024Evolutionary Algorithms (EAs) are often challenging to apply in real-world settings since evolutionary computations involve a large number of evaluations of a typically expensive fitness function. For example, an evaluation could involve training a new machine learning model. An approximation (also known as meta-model or a surrogate) of the true function can be used in such applications to alleviate the computation cost. In this paper, we propose a two-stage surrogate-assisted evolutionary approach to address the computational issues arising from using Genetic Algorithm (GA) for feature selection in a wrapper setting for large datasets. We define 'Approximation Usefulness' to capture the necessary conditions to ensure correctness of the EA computations when an approximation is used. Based on this definition, we propose a procedure to construct a lightweight qualitative meta-model by the active selection of data instances. We then use a meta-model to carry out the feature selection task. We apply this procedure to the GA-based algorithm CHC (Cross generational elitist selection, Heterogeneous recombination and Cataclysmic mutation) to create a Qualitative approXimations variant, CHCQX. We show that CHCQX converges faster to feature subset solutions of significantly higher accuracy (as compared to CHC), particularly for large datasets with over 100K instances. We also demonstrate the applicability of the thinking behind our approach more broadly to Swarm Intelligence (SI), another branch of the Evolutionary Computation (EC) paradigm with results of PSOQX, a qualitative approximation adaptation of the Particle Swarm Optimization (PSO) method. A GitHub repository with the complete implementation is available.
Forecasting Auxiliary Energy Consumption for Electric Heavy-Duty Vehicles
Nov 27, 2023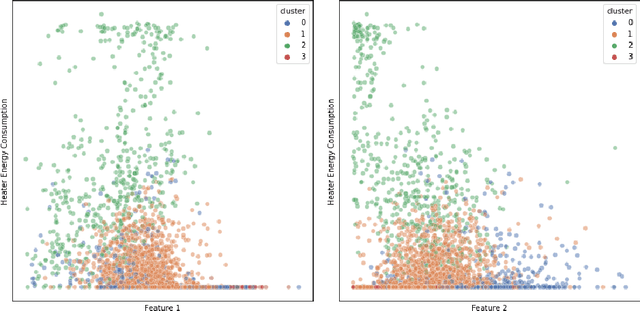
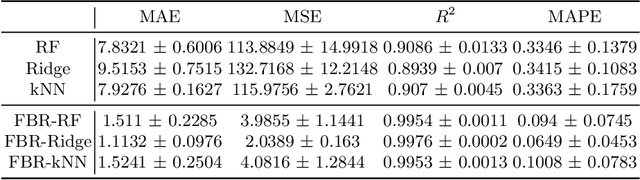
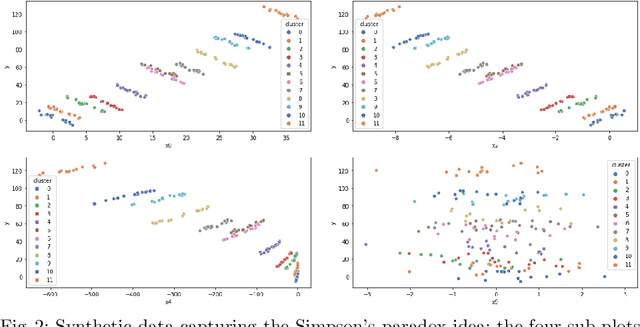
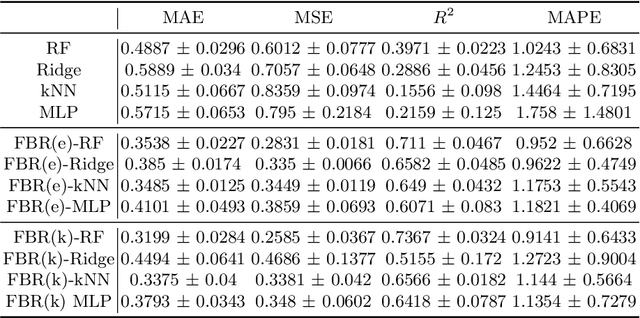
Accurate energy consumption prediction is crucial for optimizing the operation of electric commercial heavy-duty vehicles, e.g., route planning for charging. Moreover, understanding why certain predictions are cast is paramount for such a predictive model to gain user trust and be deployed in practice. Since commercial vehicles operate differently as transportation tasks, ambient, and drivers vary, a heterogeneous population is expected when building an AI system for forecasting energy consumption. The dependencies between the input features and the target values are expected to also differ across sub-populations. One well-known example of such a statistical phenomenon is the Simpson paradox. In this paper, we illustrate that such a setting poses a challenge for existing XAI methods that produce global feature statistics, e.g. LIME or SHAP, causing them to yield misleading results. We demonstrate a potential solution by training multiple regression models on subsets of data. It not only leads to superior regression performance but also more relevant and consistent LIME explanations. Given that the employed groupings correspond to relevant sub-populations, the associations between the input features and the target values are consistent within each cluster but different across clusters. Experiments on both synthetic and real-world datasets show that such splitting of a complex problem into simpler ones yields better regression performance and interpretability.
Heterogeneous Federated Learning via Personalized Generative Networks
Aug 25, 2023Federated Learning (FL) allows several clients to construct a common global machine-learning model without having to share their data. FL, however, faces the challenge of statistical heterogeneity between the client's data, which degrades performance and slows down the convergence toward the global model. In this paper, we provide theoretical proof that minimizing heterogeneity between clients facilitates the convergence of a global model for every single client. This becomes particularly important under empirical concept shifts among clients, rather than merely considering imbalanced classes, which have been studied until now. Therefore, we propose a method for knowledge transfer between clients where the server trains client-specific generators. Each generator generates samples for the corresponding client to remove the conflict with other clients' models. Experiments conducted on synthetic and real data, along with a theoretical study, support the effectiveness of our method in constructing a well-generalizable global model by reducing the conflict between local models.
Explainable Predictive Maintenance
Jun 08, 2023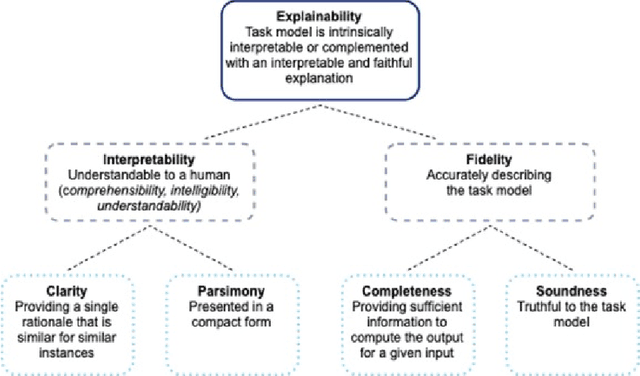

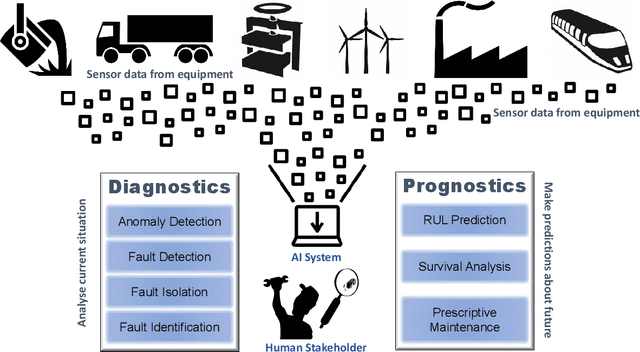
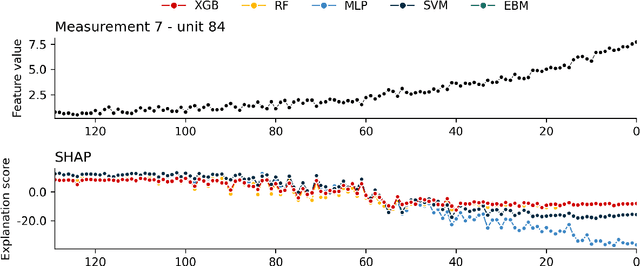
Explainable Artificial Intelligence (XAI) fills the role of a critical interface fostering interactions between sophisticated intelligent systems and diverse individuals, including data scientists, domain experts, end-users, and more. It aids in deciphering the intricate internal mechanisms of ``black box'' Machine Learning (ML), rendering the reasons behind their decisions more understandable. However, current research in XAI primarily focuses on two aspects; ways to facilitate user trust, or to debug and refine the ML model. The majority of it falls short of recognising the diverse types of explanations needed in broader contexts, as different users and varied application areas necessitate solutions tailored to their specific needs. One such domain is Predictive Maintenance (PdM), an exploding area of research under the Industry 4.0 \& 5.0 umbrella. This position paper highlights the gap between existing XAI methodologies and the specific requirements for explanations within industrial applications, particularly the Predictive Maintenance field. Despite explainability's crucial role, this subject remains a relatively under-explored area, making this paper a pioneering attempt to bring relevant challenges to the research community's attention. We provide an overview of predictive maintenance tasks and accentuate the need and varying purposes for corresponding explanations. We then list and describe XAI techniques commonly employed in the literature, discussing their suitability for PdM tasks. Finally, to make the ideas and claims more concrete, we demonstrate XAI applied in four specific industrial use cases: commercial vehicles, metro trains, steel plants, and wind farms, spotlighting areas requiring further research.
The Concordance Index decomposition: a measure for a deeper understanding of survival prediction models
Mar 02, 2022
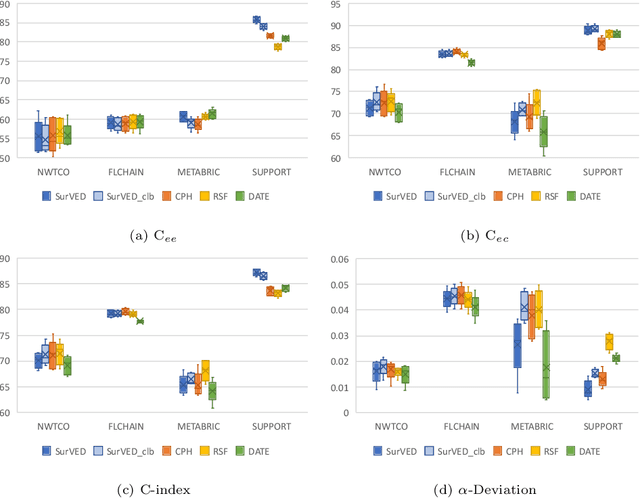
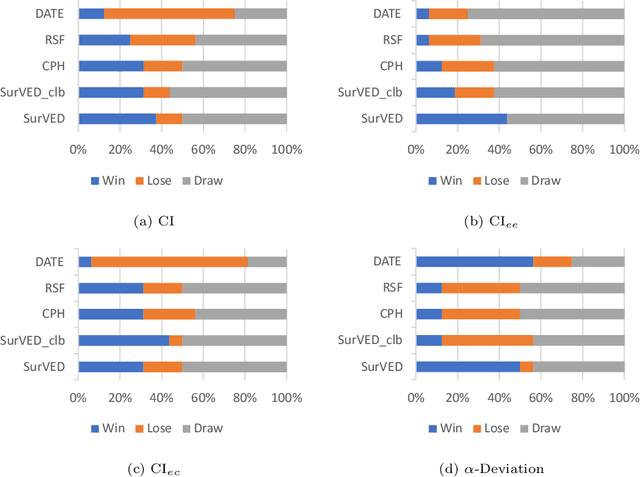

The Concordance Index (C-index) is a commonly used metric in Survival Analysis to evaluate how good a prediction model is. This paper proposes a decomposition of the C-Index into a weighted harmonic mean of two quantities: one for ranking observed events versus other observed events, and the other for ranking observed events versus censored cases. This decomposition allows a more fine-grained analysis of the pros and cons of survival prediction methods. The utility of the decomposition is demonstrated using three benchmark survival analysis models (Cox Proportional Hazard, Random Survival Forest, and Deep Adversarial Time-to-Event Network) together with a new variational generative neural-network-based method (SurVED), which is also proposed in this paper. The demonstration is done on four publicly available datasets with varying censoring levels. The analysis with the C-index decomposition shows that all methods essentially perform equally well when the censoring level is high because of the dominance of the term measuring the ranking of events versus censored cases. In contrast, some methods deteriorate when the censoring level decreases because they do not rank the events versus other events well.
Surrogate-Assisted Genetic Algorithm for Wrapper Feature Selection
Nov 17, 2021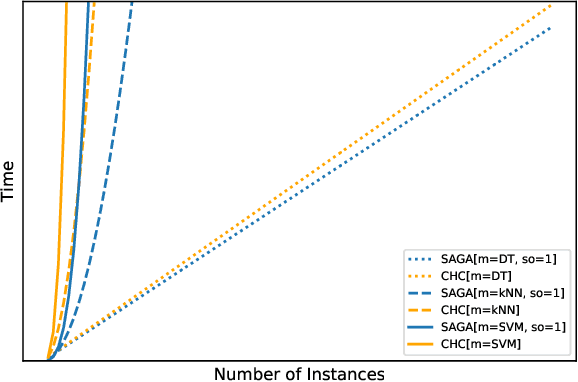
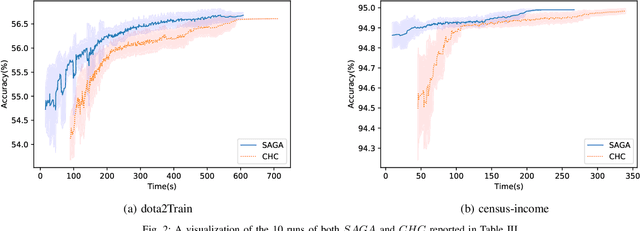
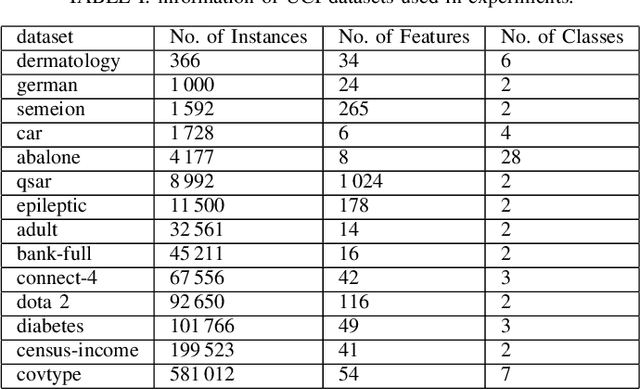
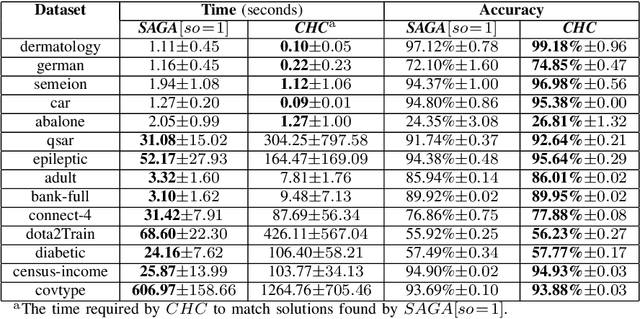
Feature selection is an intractable problem, therefore practical algorithms often trade off the solution accuracy against the computation time. In this paper, we propose a novel multi-stage feature selection framework utilizing multiple levels of approximations, or surrogates. Such a framework allows for using wrapper approaches in a much more computationally efficient way, significantly increasing the quality of feature selection solutions achievable, especially on large datasets. We design and evaluate a Surrogate-Assisted Genetic Algorithm (SAGA) which utilizes this concept to guide the evolutionary search during the early phase of exploration. SAGA only switches to evaluating the original function at the final exploitation phase. We prove that the run-time upper bound of SAGA surrogate-assisted stage is at worse equal to the wrapper GA, and it scales better for induction algorithms of high order of complexity in number of instances. We demonstrate, using 14 datasets from the UCI ML repository, that in practice SAGA significantly reduces the computation time compared to a baseline wrapper Genetic Algorithm (GA), while converging to solutions of significantly higher accuracy. Our experiments show that SAGA can arrive at near-optimal solutions three times faster than a wrapper GA, on average. We also showcase the importance of evolution control approach designed to prevent surrogates from misleading the evolutionary search towards false optima.