 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Forecast Accuracy and Inventory KPIs: A Simulation-Based Software Framework
Jan 29, 2026Efficient management of spare parts inventory is crucial in the automotive aftermarket, where demand is highly intermittent and uncertainty drives substantial cost and service risks. Forecasting is therefore central, but the quality of a forecasting model should be judged not by statistical accuracy (e.g., MAE, RMSE, IAE) but rather by its impact on key operational performance indicators (KPIs), such as total cost and service level. Yet most existing work evaluates models exclusively using accuracy metrics, and the relationship between these metrics and operational KPIs remains poorly understood. To address this gap, we propose a decision-centric simulation software framework that enables systematic evaluation of forecasting model in realistic inventory management setting. The framework comprises: (i) a synthetic demand generator tailored to spare-parts demand characteristics, (ii) a flexible forecasting module that can host arbitrary predictive models, and (iii) an inventory control simulator that consumes the forecasts and computes operational KPIs. This closed-loop setup enables researchers to evaluate models not only in terms of statistical error but also in terms of their downstream implications for inventory decisions. Using a wide range of simulation scenarios, we show that improvements in conventional accuracy metrics do not necessarily translate into better operational performance, and that models with similar statistical error profiles can induce markedly different cost-service trade-offs. We analyze these discrepancies to characterize how specific aspects of forecast performance affect inventory outcomes and derive guidance for model selection. Overall, the framework operationalizes the link between demand forecasting and inventory management, shifting evaluation from purely predictive accuracy toward operational relevance in the automotive aftermarket and related domains.
Contrastive Time Series Forecasting with Anomalies
Dec 12, 2025Time series forecasting predicts future values from past data. In real-world settings, some anomalous events have lasting effects and influence the forecast, while others are short-lived and should be ignored. Standard forecasting models fail to make this distinction, often either overreacting to noise or missing persistent shifts. We propose Co-TSFA (Contrastive Time Series Forecasting with Anomalies), a regularization framework that learns when to ignore anomalies and when to respond. Co-TSFA generates input-only and input-output augmentations to model forecast-irrelevant and forecast-relevant anomalies, and introduces a latent-output alignment loss that ties representation changes to forecast changes. This encourages invariance to irrelevant perturbations while preserving sensitivity to meaningful distributional shifts. Experiments on the Traffic and Electricity benchmarks, as well as on a real-world cash-demand dataset, demonstrate that Co-TSFA improves performance under anomalous conditions while maintaining accuracy on normal data. An anonymized GitHub repository with the implementation of Co-TSFA is provided and will be made public upon acceptance.
Weighted Contrastive Learning for Anomaly-Aware Time-Series Forecasting
Dec 08, 2025



Reliable forecasting of multivariate time series under anomalous conditions is crucial in applications such as ATM cash logistics, where sudden demand shifts can disrupt operations. Modern deep forecasters achieve high accuracy on normal data but often fail when distribution shifts occur. We propose Weighted Contrastive Adaptation (WECA), a Weighted contrastive objective that aligns normal and anomaly-augmented representations, preserving anomaly-relevant information while maintaining consistency under benign variations. Evaluations on a nationwide ATM transaction dataset with domain-informed anomaly injection show that WECA improves SMAPE on anomaly-affected data by 6.1 percentage points compared to a normally trained baseline, with negligible degradation on normal data. These results demonstrate that WECA enhances forecasting reliability under anomalies without sacrificing performance during regular operations.
Physics-incorporated Graph Neural Network for Multivariate Time Series Imputation
May 16, 2024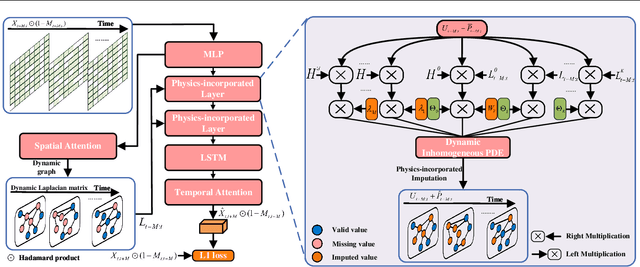
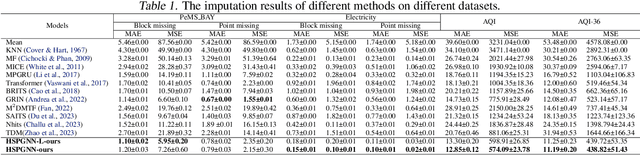
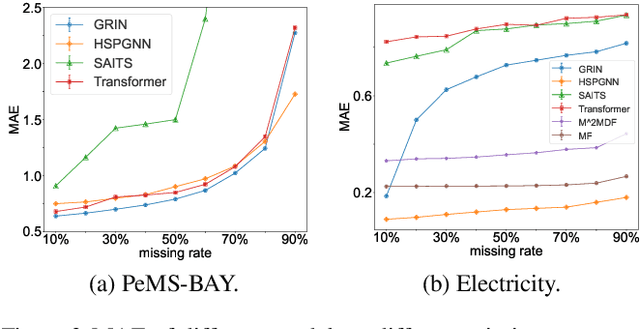
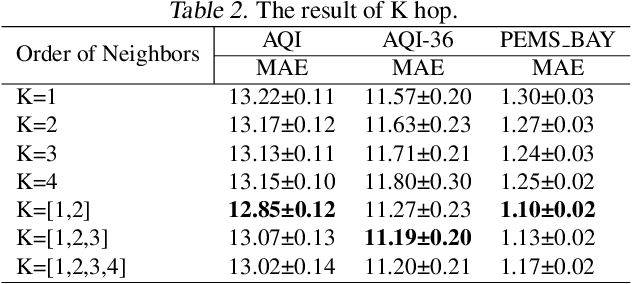
Exploring the missing values is an essential but challenging issue due to the complex latent spatio-temporal correlation and dynamic nature of time series. Owing to the outstanding performance in dealing with structure learning potentials, Graph Neural Networks (GNNs) and Recurrent Neural Networks (RNNs) are often used to capture such complex spatio-temporal features in multivariate time series. However, these data-driven models often fail to capture the essential spatio-temporal relationships when significant signal corruption occurs. Additionally, calculating the high-order neighbor nodes in these models is of high computational complexity. To address these problems, we propose a novel higher-order spatio-temporal physics-incorporated GNN (HSPGNN). Firstly, the dynamic Laplacian matrix can be obtained by the spatial attention mechanism. Then, the generic inhomogeneous partial differential equation (PDE) of physical dynamic systems is used to construct the dynamic higher-order spatio-temporal GNN to obtain the missing time series values. Moreover, we estimate the missing impact by Normalizing Flows (NF) to evaluate the importance of each node in the graph for better explainability. Experimental results on four benchmark datasets demonstrate the effectiveness of HSPGNN and the superior performance when combining various order neighbor nodes. Also, graph-like optical flow, dynamic graphs, and missing impact can be obtained naturally by HSPGNN, which provides better dynamic analysis and explanation than traditional data-driven models. Our code is available at https://github.com/gorgen2020/HSPGNN.
Spatial Clustering Approach for Vessel Path Identification
Mar 09, 2024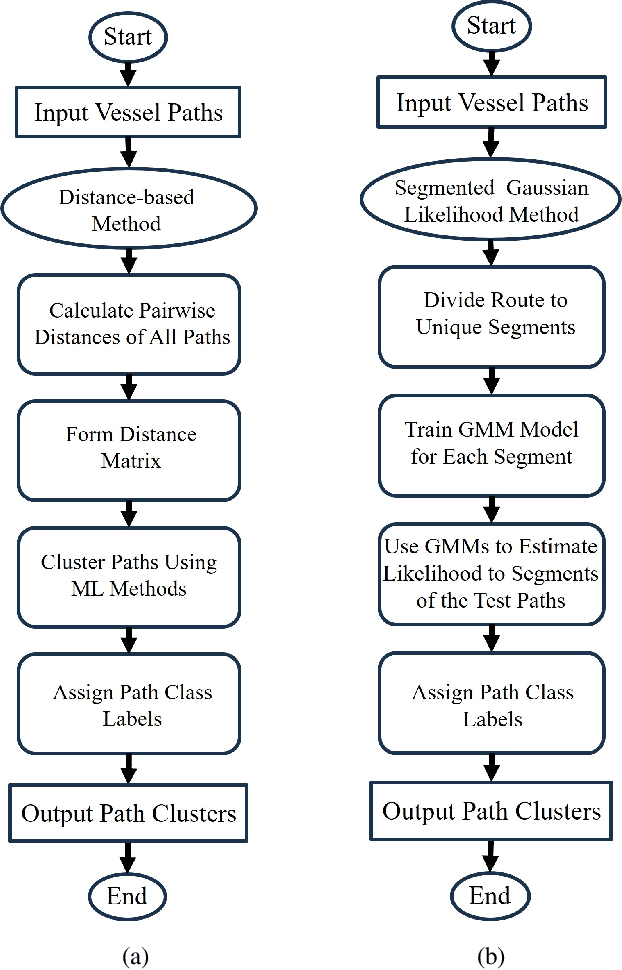
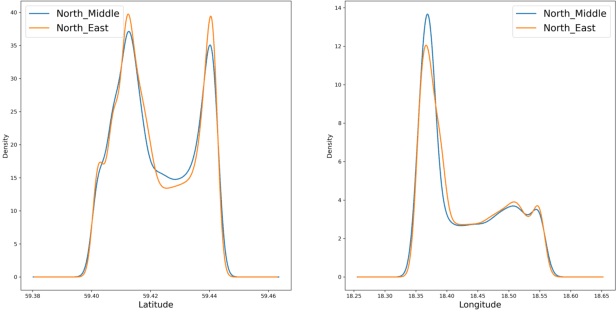
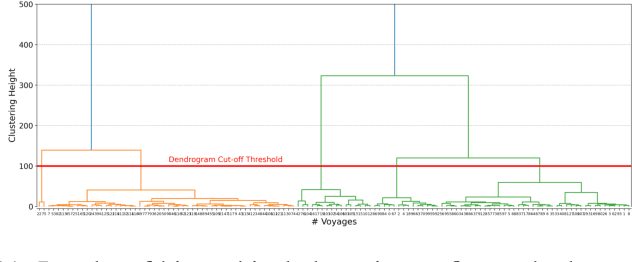
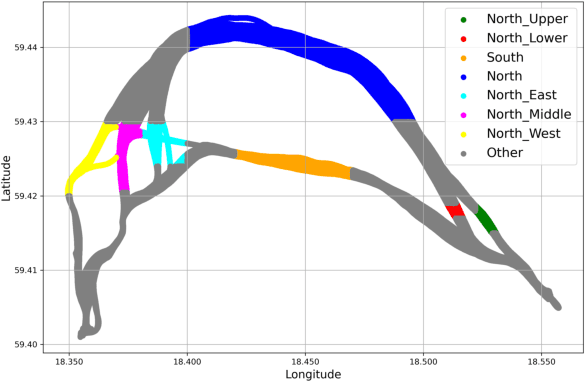
This paper addresses the challenge of identifying the paths for vessels with operating routes of repetitive paths, partially repetitive paths, and new paths. We propose a spatial clustering approach for labeling the vessel paths by using only position information. We develop a path clustering framework employing two methods: a distance-based path modeling and a likelihood estimation method. The former enhances the accuracy of path clustering through the integration of unsupervised machine learning techniques, while the latter focuses on likelihood-based path modeling and introduces segmentation for a more detailed analysis. The result findings highlight the superior performance and efficiency of the developed approach, as both methods for clustering vessel paths into five classes achieve a perfect F1-score. The approach aims to offer valuable insights for route planning, ultimately contributing to improving safety and efficiency in maritime transportation.
Forecasting Auxiliary Energy Consumption for Electric Heavy-Duty Vehicles
Nov 27, 2023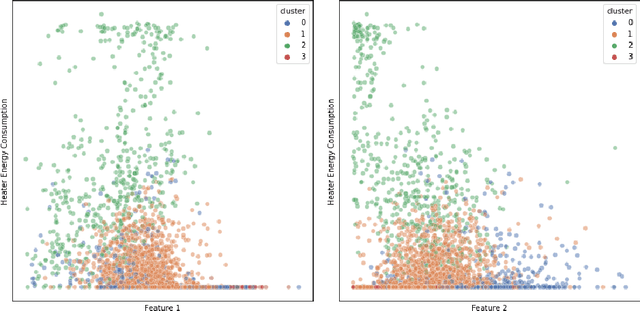
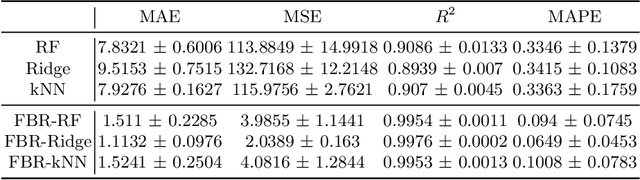
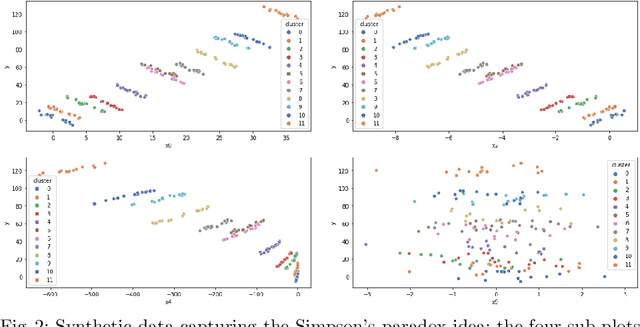
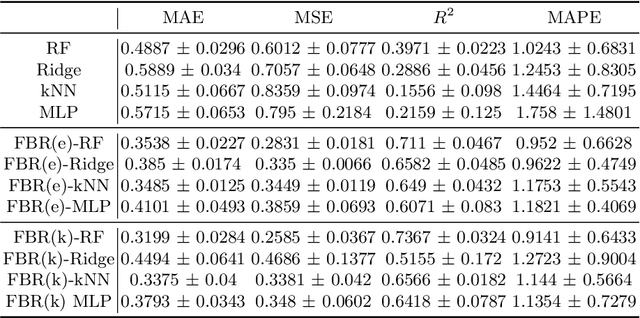
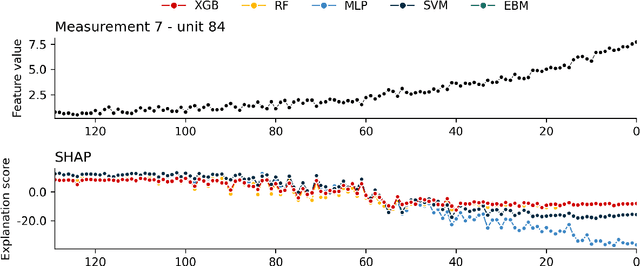
Accurate energy consumption prediction is crucial for optimizing the operation of electric commercial heavy-duty vehicles, e.g., route planning for charging. Moreover, understanding why certain predictions are cast is paramount for such a predictive model to gain user trust and be deployed in practice. Since commercial vehicles operate differently as transportation tasks, ambient, and drivers vary, a heterogeneous population is expected when building an AI system for forecasting energy consumption. The dependencies between the input features and the target values are expected to also differ across sub-populations. One well-known example of such a statistical phenomenon is the Simpson paradox. In this paper, we illustrate that such a setting poses a challenge for existing XAI methods that produce global feature statistics, e.g. LIME or SHAP, causing them to yield misleading results. We demonstrate a potential solution by training multiple regression models on subsets of data. It not only leads to superior regression performance but also more relevant and consistent LIME explanations. Given that the employed groupings correspond to relevant sub-populations, the associations between the input features and the target values are consistent within each cluster but different across clusters. Experiments on both synthetic and real-world datasets show that such splitting of a complex problem into simpler ones yields better regression performance and interpretability.
Heterogeneous Federated Learning via Personalized Generative Networks
Aug 25, 2023Federated Learning (FL) allows several clients to construct a common global machine-learning model without having to share their data. FL, however, faces the challenge of statistical heterogeneity between the client's data, which degrades performance and slows down the convergence toward the global model. In this paper, we provide theoretical proof that minimizing heterogeneity between clients facilitates the convergence of a global model for every single client. This becomes particularly important under empirical concept shifts among clients, rather than merely considering imbalanced classes, which have been studied until now. Therefore, we propose a method for knowledge transfer between clients where the server trains client-specific generators. Each generator generates samples for the corresponding client to remove the conflict with other clients' models. Experiments conducted on synthetic and real data, along with a theoretical study, support the effectiveness of our method in constructing a well-generalizable global model by reducing the conflict between local models.
Explainable Predictive Maintenance
Jun 08, 2023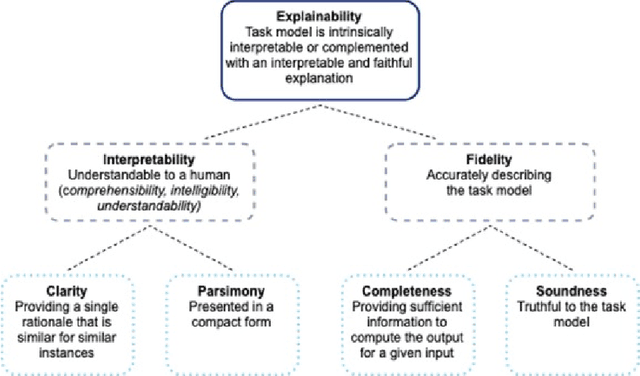

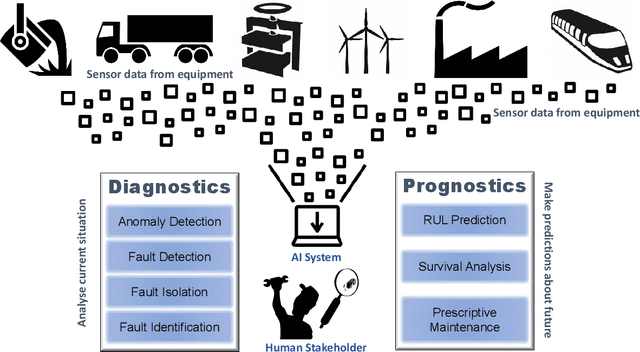
Explainable Artificial Intelligence (XAI) fills the role of a critical interface fostering interactions between sophisticated intelligent systems and diverse individuals, including data scientists, domain experts, end-users, and more. It aids in deciphering the intricate internal mechanisms of ``black box'' Machine Learning (ML), rendering the reasons behind their decisions more understandable. However, current research in XAI primarily focuses on two aspects; ways to facilitate user trust, or to debug and refine the ML model. The majority of it falls short of recognising the diverse types of explanations needed in broader contexts, as different users and varied application areas necessitate solutions tailored to their specific needs. One such domain is Predictive Maintenance (PdM), an exploding area of research under the Industry 4.0 \& 5.0 umbrella. This position paper highlights the gap between existing XAI methodologies and the specific requirements for explanations within industrial applications, particularly the Predictive Maintenance field. Despite explainability's crucial role, this subject remains a relatively under-explored area, making this paper a pioneering attempt to bring relevant challenges to the research community's attention. We provide an overview of predictive maintenance tasks and accentuate the need and varying purposes for corresponding explanations. We then list and describe XAI techniques commonly employed in the literature, discussing their suitability for PdM tasks. Finally, to make the ideas and claims more concrete, we demonstrate XAI applied in four specific industrial use cases: commercial vehicles, metro trains, steel plants, and wind farms, spotlighting areas requiring further research.
Learning Causal Mechanisms through Orthogonal Neural Networks
Jun 05, 2023A fundamental feature of human intelligence is the ability to infer high-level abstractions from low-level sensory data. An essential component of such inference is the ability to discover modularized generative mechanisms. Despite many efforts to use statistical learning and pattern recognition for finding disentangled factors, arguably human intelligence remains unmatched in this area. In this paper, we investigate a problem of learning, in a fully unsupervised manner, the inverse of a set of independent mechanisms from distorted data points. We postulate, and justify this claim with experimental results, that an important weakness of existing machine learning solutions lies in the insufficiency of cross-module diversification. Addressing this crucial discrepancy between human and machine intelligence is an important challenge for pattern recognition systems. To this end, our work proposes an unsupervised method that discovers and disentangles a set of independent mechanisms from unlabeled data, and learns how to invert them. A number of experts compete against each other for individual data points in an adversarial setting: one that best inverses the (unknown) generative mechanism is the winner. We demonstrate that introducing an orthogonalization layer into the expert architectures enforces additional diversity in the outputs, leading to significantly better separability. Moreover, we propose a procedure for relocating data points between experts to further prevent any one from claiming multiple mechanisms. We experimentally illustrate that these techniques allow discovery and modularization of much less pronounced transformations, in addition to considerably faster convergence.
Information-Gathering in Latent Bandits
Jul 08, 2022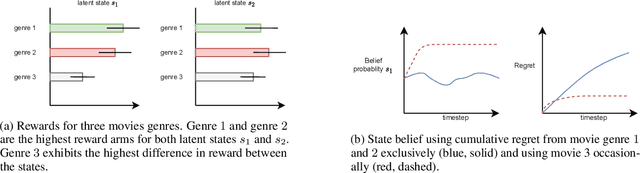
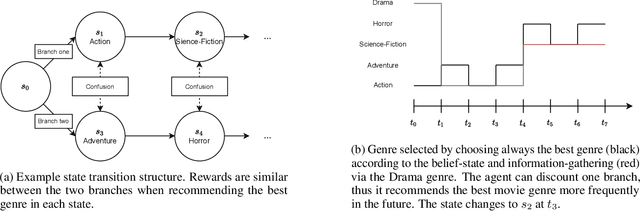
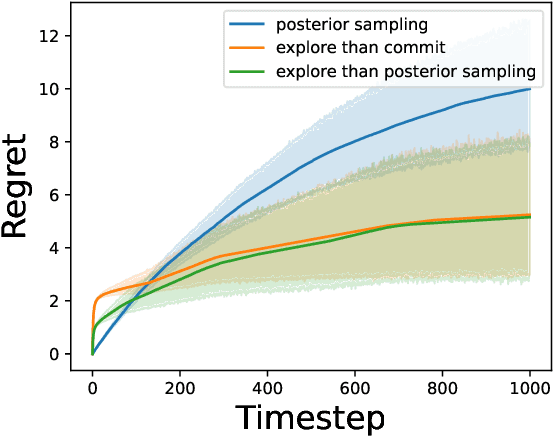
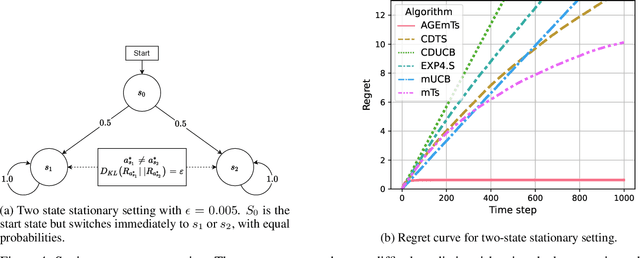
In the latent bandit problem, the learner has access to reward distributions and -- for the non-stationary variant -- transition models of the environment. The reward distributions are conditioned on the arm and unknown latent states. The goal is to use the reward history to identify the latent state, allowing for the optimal choice of arms in the future. The latent bandit setting lends itself to many practical applications, such as recommender and decision support systems, where rich data allows the offline estimation of environment models with online learning remaining a critical component. Previous solutions in this setting always choose the highest reward arm according to the agent's beliefs about the state, not explicitly considering the value of information-gathering arms. Such information-gathering arms do not necessarily provide the highest reward, thus may never be chosen by an agent that chooses the highest reward arms at all times. In this paper, we present a method for information-gathering in latent bandits. Given particular reward structures and transition matrices, we show that choosing the best arm given the agent's beliefs about the states incurs higher regret. Furthermore, we show that by choosing arms carefully, we obtain an improved estimation of the state distribution, and thus lower the cumulative regret through better arm choices in the future. We evaluate our method on both synthetic and real-world data sets, showing significant improvement in regret over state-of-the-art methods.