 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging ChatGPT's Multimodal Vision Capabilities to Rank Satellite Images by Poverty Level: Advancing Tools for Social Science Research
Jan 24, 2025This paper investigates the novel application of Large Language Models (LLMs) with vision capabilities to analyze satellite imagery for village-level poverty prediction. Although LLMs were originally designed for natural language understanding, their adaptability to multimodal tasks, including geospatial analysis, has opened new frontiers in data-driven research. By leveraging advancements in vision-enabled LLMs, we assess their ability to provide interpretable, scalable, and reliable insights into human poverty from satellite images. Using a pairwise comparison approach, we demonstrate that ChatGPT can rank satellite images based on poverty levels with accuracy comparable to domain experts. These findings highlight both the promise and the limitations of LLMs in socioeconomic research, providing a foundation for their integration into poverty assessment workflows. This study contributes to the ongoing exploration of unconventional data sources for welfare analysis and opens pathways for cost-effective, large-scale poverty monitoring.
CoxSE: Exploring the Potential of Self-Explaining Neural Networks with Cox Proportional Hazards Model for Survival Analysis
Jul 18, 2024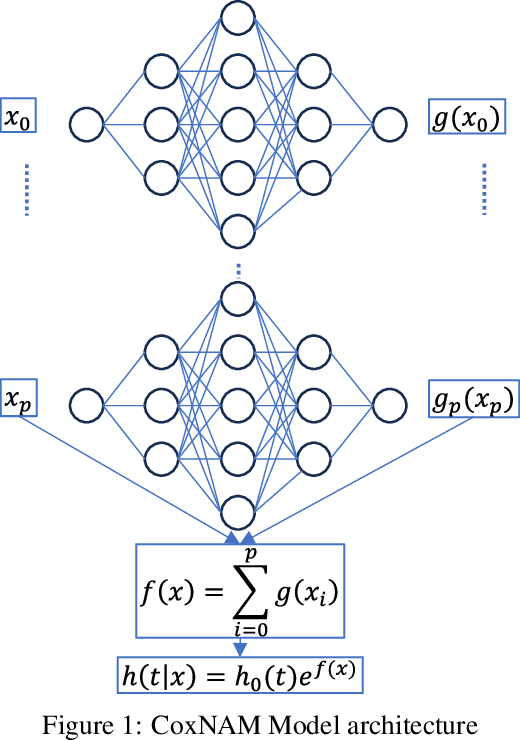



The Cox Proportional Hazards (CPH) model has long been the preferred survival model for its explainability. However, to increase its predictive power beyond its linear log-risk, it was extended to utilize deep neural networks sacrificing its explainability. In this work, we explore the potential of self-explaining neural networks (SENN) for survival analysis. we propose a new locally explainable Cox proportional hazards model, named CoxSE, by estimating a locally-linear log-hazard function using the SENN. We also propose a modification to the Neural additive (NAM) models hybrid with SENN, named CoxSENAM, which enables the control of the stability and consistency of the generated explanations. Several experiments using synthetic and real datasets have been performed comparing with a NAM-based model, DeepSurv model explained with SHAP, and a linear CPH model. The results show that, unlike the NAM-based model, the SENN-based model can provide more stable and consistent explanations while maintaining the same expressiveness power of the black-box model. The results also show that, due to their structural design, NAM-based models demonstrated better robustness to non-informative features. Among these models, the hybrid model exhibited the best robustness.
A Masked language model for multi-source EHR trajectories contextual representation learning
Feb 07, 2024Using electronic health records data and machine learning to guide future decisions needs to address challenges, including 1) long/short-term dependencies and 2) interactions between diseases and interventions. Bidirectional transformers have effectively addressed the first challenge. Here we tackled the latter challenge by masking one source (e.g., ICD10 codes) and training the transformer to predict it using other sources (e.g., ATC codes).
Towards Explaining Satellite Based Poverty Predictions with Convolutional Neural Networks
Dec 01, 2023Deep convolutional neural networks (CNNs) have been shown to predict poverty and development indicators from satellite images with surprising accuracy. This paper presents a first attempt at analyzing the CNNs responses in detail and explaining the basis for the predictions. The CNN model, while trained on relatively low resolution day- and night-time satellite images, is able to outperform human subjects who look at high-resolution images in ranking the Wealth Index categories. Multiple explainability experiments performed on the model indicate the importance of the sizes of the objects, pixel colors in the image, and provide a visualization of the importance of different structures in input images. A visualization is also provided of type images that maximize the network prediction of Wealth Index, which provides clues on what the CNN prediction is based on.
Satellite Image and Machine Learning based Knowledge Extraction in the Poverty and Welfare Domain
Mar 02, 2022
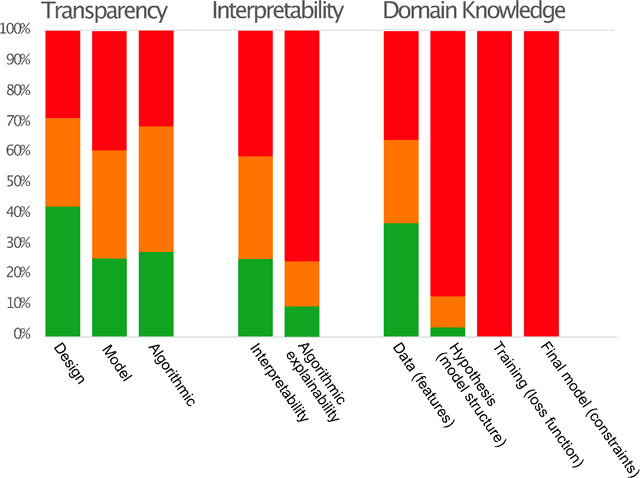

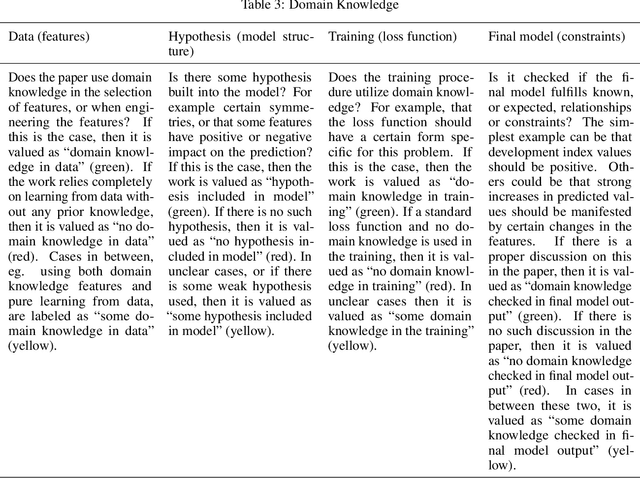
Recent advances in artificial intelligence and machine learning have created a step change in how to measure human development indicators, in particular asset based poverty. The combination of satellite imagery and machine learning has the capability to estimate poverty at a level similar to what is achieved with workhorse methods such as face-to-face interviews and household surveys. An increasingly important issue beyond static estimations is whether this technology can contribute to scientific discovery and consequently new knowledge in the poverty and welfare domain. A foundation for achieving scientific insights is domain knowledge, which in turn translates into explainability and scientific consistency. We review the literature focusing on three core elements relevant in this context: transparency, interpretability, and explainability and investigate how they relates to the poverty, machine learning and satellite imagery nexus. Our review of the field shows that the status of the three core elements of explainable machine learning (transparency, interpretability and domain knowledge) is varied and does not completely fulfill the requirements set up for scientific insights and discoveries. We argue that explainability is essential to support wider dissemination and acceptance of this research, and explainability means more than just interpretability.
The Concordance Index decomposition: a measure for a deeper understanding of survival prediction models
Mar 02, 2022
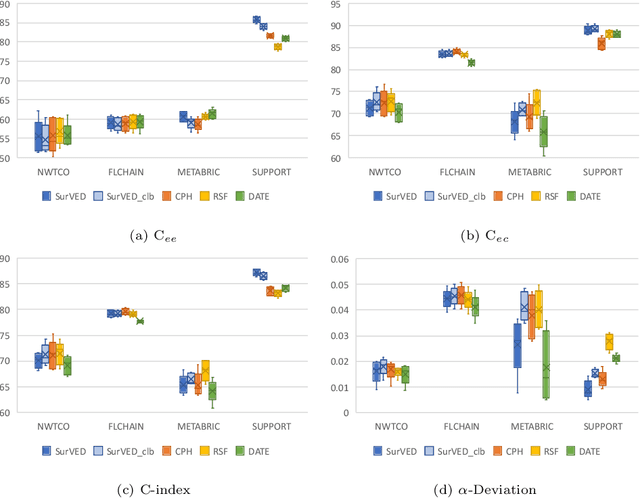
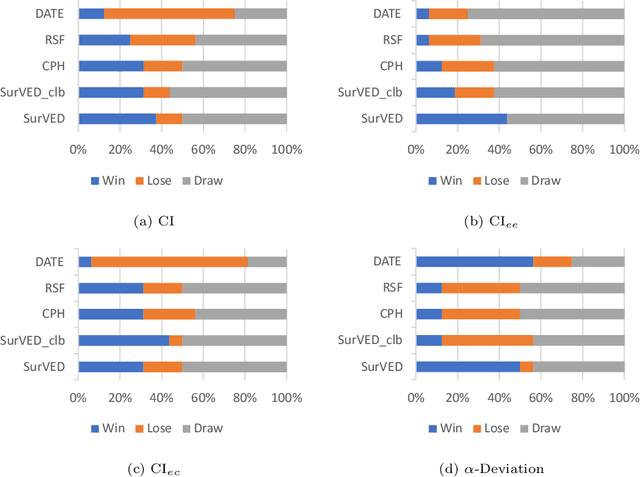

The Concordance Index (C-index) is a commonly used metric in Survival Analysis to evaluate how good a prediction model is. This paper proposes a decomposition of the C-Index into a weighted harmonic mean of two quantities: one for ranking observed events versus other observed events, and the other for ranking observed events versus censored cases. This decomposition allows a more fine-grained analysis of the pros and cons of survival prediction methods. The utility of the decomposition is demonstrated using three benchmark survival analysis models (Cox Proportional Hazard, Random Survival Forest, and Deep Adversarial Time-to-Event Network) together with a new variational generative neural-network-based method (SurVED), which is also proposed in this paper. The demonstration is done on four publicly available datasets with varying censoring levels. The analysis with the C-index decomposition shows that all methods essentially perform equally well when the censoring level is high because of the dominance of the term measuring the ranking of events versus censored cases. In contrast, some methods deteriorate when the censoring level decreases because they do not rank the events versus other events well.
Corrupted Contextual Bandits with Action Order Constraints
Nov 16, 2020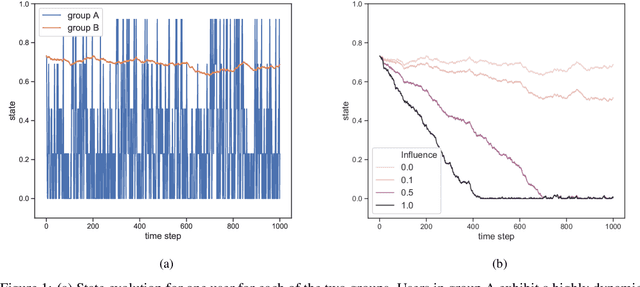
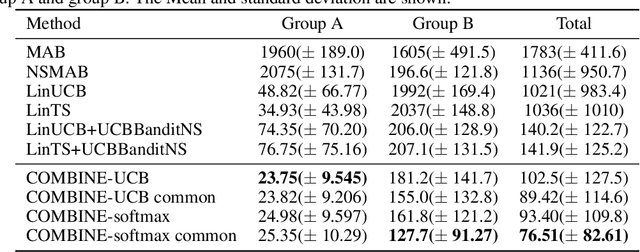
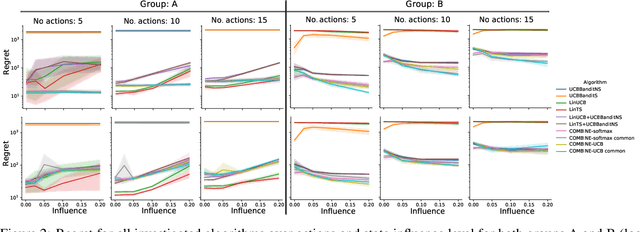
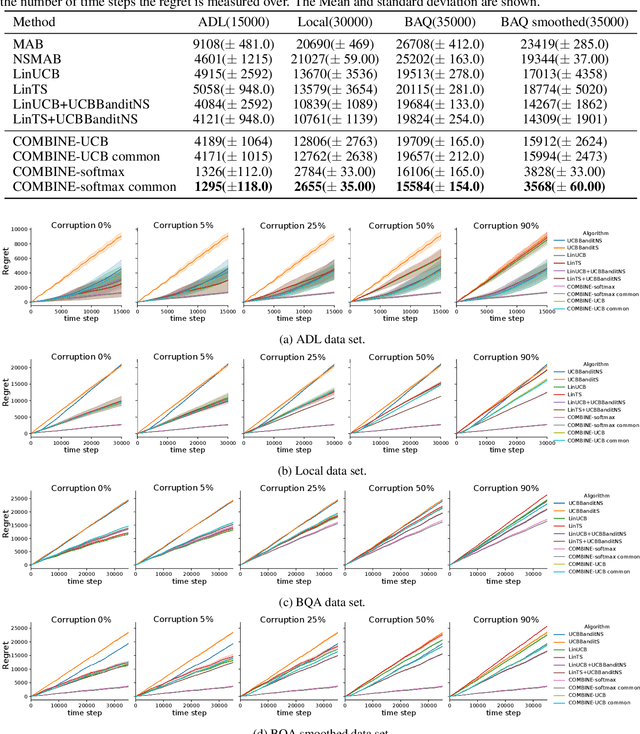
We consider a variant of the novel contextual bandit problem with corrupted context, which we call the contextual bandit problem with corrupted context and action correlation, where actions exhibit a relationship structure that can be exploited to guide the exploration of viable next decisions. Our setting is primarily motivated by adaptive mobile health interventions and related applications, where users might transitions through different stages requiring more targeted action selection approaches. In such settings, keeping user engagement is paramount for the success of interventions and therefore it is vital to provide relevant recommendations in a timely manner. The context provided by users might not always be informative at every decision point and standard contextual approaches to action selection will incur high regret. We propose a meta-algorithm using a referee that dynamically combines the policies of a contextual bandit and multi-armed bandit, similar to previous work, as wells as a simple correlation mechanism that captures action to action transition probabilities allowing for more efficient exploration of time-correlated actions. We evaluate empirically the performance of said algorithm on a simulation where the sequence of best actions is determined by a hidden state that evolves in a Markovian manner. We show that the proposed meta-algorithm improves upon regret in situations where the performance of both policies varies such that one is strictly superior to the other for a given time period. To demonstrate that our setting has relevant practical applicability, we evaluate our method on several real world data sets, clearly showing better empirical performance compared to a set of simple algorithms.
Establishing strong imputation performance of a denoising autoencoder in a wide range of missing data problems
Apr 06, 2020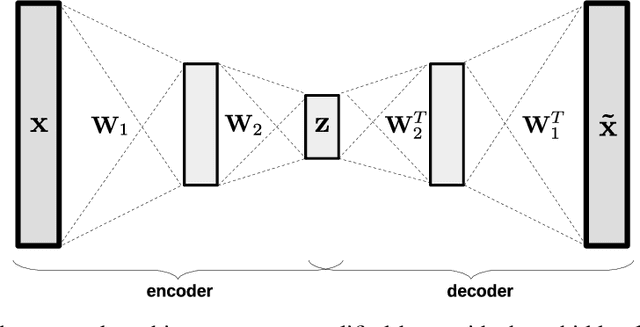
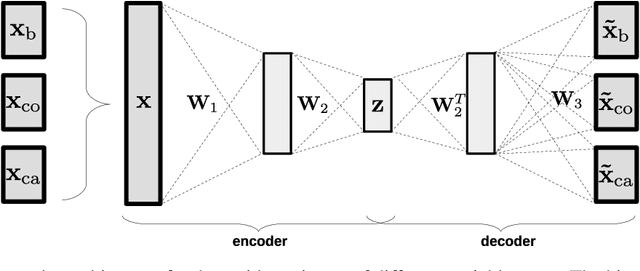
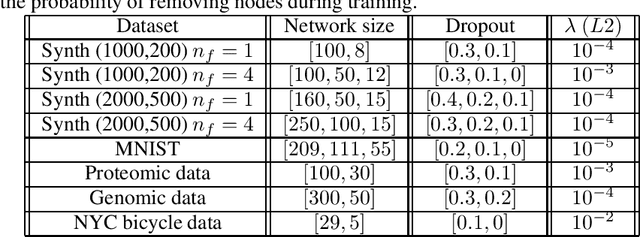
Dealing with missing data in data analysis is inevitable. Although powerful imputation methods that address this problem exist, there is still much room for improvement. In this study, we examined single imputation based on deep autoencoders, motivated by the apparent success of deep learning to efficiently extract useful dataset features. We have developed a consistent framework for both training and imputation. Moreover, we benchmarked the results against state-of-the-art imputation methods on different data sizes and characteristics. The work was not limited to the one-type variable dataset; we also imputed missing data with multi-type variables, e.g., a combination of binary, categorical, and continuous attributes. To evaluate the imputation methods, we randomly corrupted the complete data, with varying degrees of corruption, and then compared the imputed and original values. In all experiments, the developed autoencoder obtained the smallest error for all ranges of initial data corruption.
Variational auto-encoders with Student's t-prior
Apr 06, 2020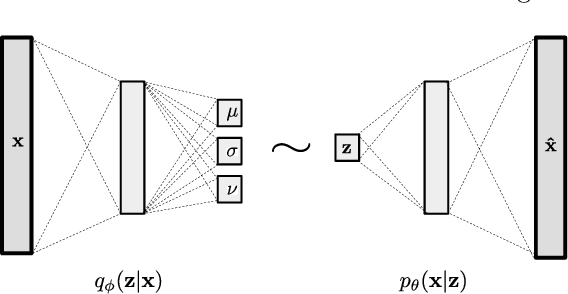

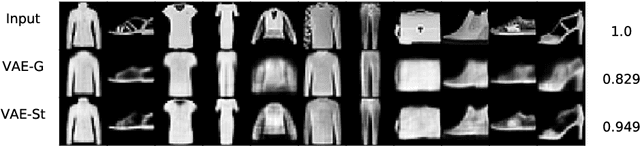

We propose a new structure for the variational auto-encoders (VAEs) prior, with the weakly informative multivariate Student's t-distribution. In the proposed model all distribution parameters are trained, thereby allowing for a more robust approximation of the underlying data distribution. We used Fashion-MNIST data in two experiments to compare the proposed VAEs with the standard Gaussian priors. Both experiments showed a better reconstruction of the images with VAEs using Student's t-prior distribution.
An Efficient Mean Field Approach to the Set Covering Problem
Feb 12, 1999
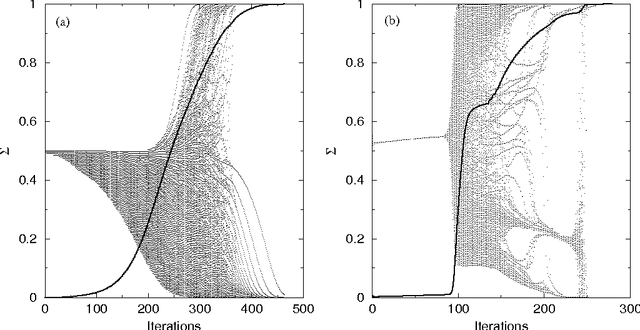

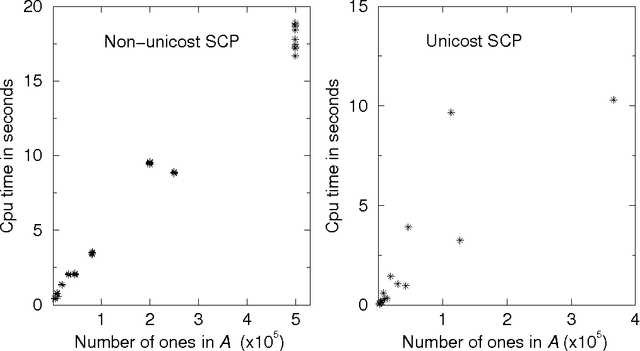
A mean field feedback artificial neural network algorithm is developed and explored for the set covering problem. A convenient encoding of the inequality constraints is achieved by means of a multilinear penalty function. An approximate energy minimum is obtained by iterating a set of mean field equations, in combination with annealing. The approach is numerically tested against a set of publicly available test problems with sizes ranging up to 5x10^3 rows and 10^6 columns. When comparing the performance with exact results for sizes where these are available, the approach yields results within a few percent from the optimal solutions. Comparisons with other approximate methods also come out well, in particular given the very low CPU consumption required -- typically a few seconds. Arbitrary problems can be processed using the algorithm via a public domain server.