 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing strong imputation performance of a denoising autoencoder in a wide range of missing data problems
Apr 06, 2020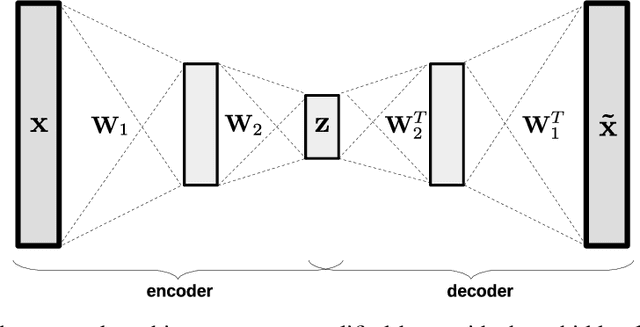
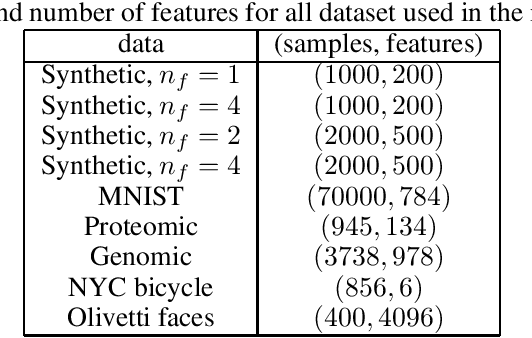
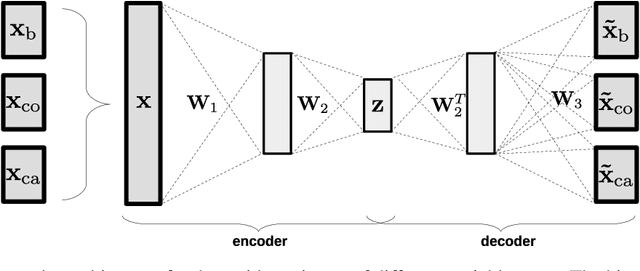
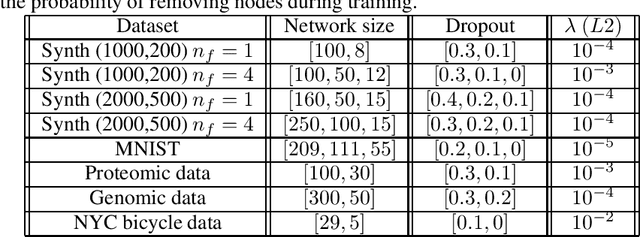
Dealing with missing data in data analysis is inevitable. Although powerful imputation methods that address this problem exist, there is still much room for improvement. In this study, we examined single imputation based on deep autoencoders, motivated by the apparent success of deep learning to efficiently extract useful dataset features. We have developed a consistent framework for both training and imputation. Moreover, we benchmarked the results against state-of-the-art imputation methods on different data sizes and characteristics. The work was not limited to the one-type variable dataset; we also imputed missing data with multi-type variables, e.g., a combination of binary, categorical, and continuous attributes. To evaluate the imputation methods, we randomly corrupted the complete data, with varying degrees of corruption, and then compared the imputed and original values. In all experiments, the developed autoencoder obtained the smallest error for all ranges of initial data corruption.