 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Forecast Accuracy and Inventory KPIs: A Simulation-Based Software Framework
Jan 29, 2026Efficient management of spare parts inventory is crucial in the automotive aftermarket, where demand is highly intermittent and uncertainty drives substantial cost and service risks. Forecasting is therefore central, but the quality of a forecasting model should be judged not by statistical accuracy (e.g., MAE, RMSE, IAE) but rather by its impact on key operational performance indicators (KPIs), such as total cost and service level. Yet most existing work evaluates models exclusively using accuracy metrics, and the relationship between these metrics and operational KPIs remains poorly understood. To address this gap, we propose a decision-centric simulation software framework that enables systematic evaluation of forecasting model in realistic inventory management setting. The framework comprises: (i) a synthetic demand generator tailored to spare-parts demand characteristics, (ii) a flexible forecasting module that can host arbitrary predictive models, and (iii) an inventory control simulator that consumes the forecasts and computes operational KPIs. This closed-loop setup enables researchers to evaluate models not only in terms of statistical error but also in terms of their downstream implications for inventory decisions. Using a wide range of simulation scenarios, we show that improvements in conventional accuracy metrics do not necessarily translate into better operational performance, and that models with similar statistical error profiles can induce markedly different cost-service trade-offs. We analyze these discrepancies to characterize how specific aspects of forecast performance affect inventory outcomes and derive guidance for model selection. Overall, the framework operationalizes the link between demand forecasting and inventory management, shifting evaluation from purely predictive accuracy toward operational relevance in the automotive aftermarket and related domains.
CoxSE: Exploring the Potential of Self-Explaining Neural Networks with Cox Proportional Hazards Model for Survival Analysis
Jul 18, 2024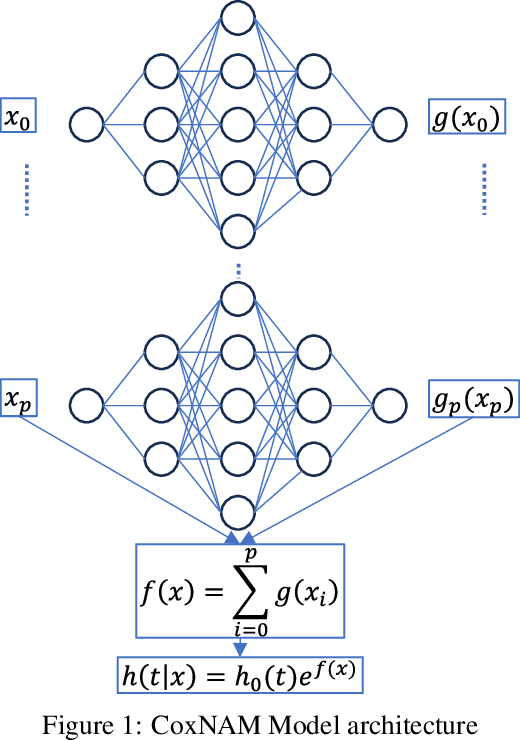



The Cox Proportional Hazards (CPH) model has long been the preferred survival model for its explainability. However, to increase its predictive power beyond its linear log-risk, it was extended to utilize deep neural networks sacrificing its explainability. In this work, we explore the potential of self-explaining neural networks (SENN) for survival analysis. we propose a new locally explainable Cox proportional hazards model, named CoxSE, by estimating a locally-linear log-hazard function using the SENN. We also propose a modification to the Neural additive (NAM) models hybrid with SENN, named CoxSENAM, which enables the control of the stability and consistency of the generated explanations. Several experiments using synthetic and real datasets have been performed comparing with a NAM-based model, DeepSurv model explained with SHAP, and a linear CPH model. The results show that, unlike the NAM-based model, the SENN-based model can provide more stable and consistent explanations while maintaining the same expressiveness power of the black-box model. The results also show that, due to their structural design, NAM-based models demonstrated better robustness to non-informative features. Among these models, the hybrid model exhibited the best robustness.
Explainable Predictive Maintenance
Jun 08, 2023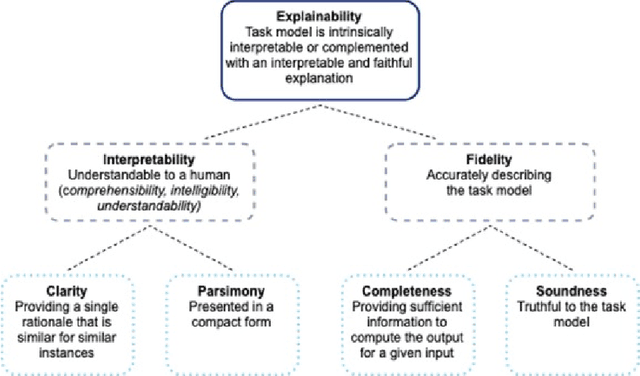

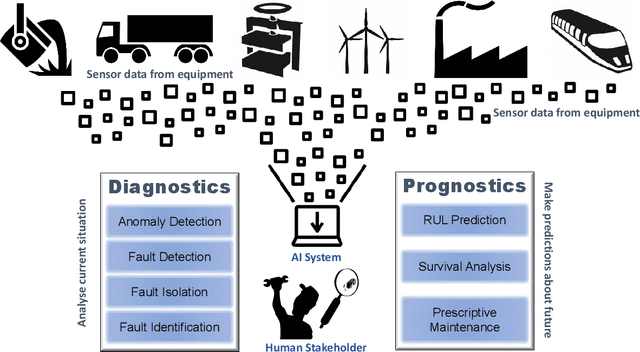
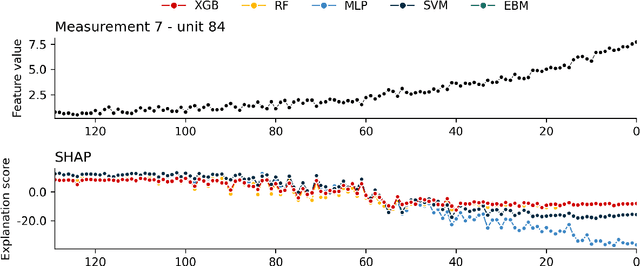
Explainable Artificial Intelligence (XAI) fills the role of a critical interface fostering interactions between sophisticated intelligent systems and diverse individuals, including data scientists, domain experts, end-users, and more. It aids in deciphering the intricate internal mechanisms of ``black box'' Machine Learning (ML), rendering the reasons behind their decisions more understandable. However, current research in XAI primarily focuses on two aspects; ways to facilitate user trust, or to debug and refine the ML model. The majority of it falls short of recognising the diverse types of explanations needed in broader contexts, as different users and varied application areas necessitate solutions tailored to their specific needs. One such domain is Predictive Maintenance (PdM), an exploding area of research under the Industry 4.0 \& 5.0 umbrella. This position paper highlights the gap between existing XAI methodologies and the specific requirements for explanations within industrial applications, particularly the Predictive Maintenance field. Despite explainability's crucial role, this subject remains a relatively under-explored area, making this paper a pioneering attempt to bring relevant challenges to the research community's attention. We provide an overview of predictive maintenance tasks and accentuate the need and varying purposes for corresponding explanations. We then list and describe XAI techniques commonly employed in the literature, discussing their suitability for PdM tasks. Finally, to make the ideas and claims more concrete, we demonstrate XAI applied in four specific industrial use cases: commercial vehicles, metro trains, steel plants, and wind farms, spotlighting areas requiring further research.
The Concordance Index decomposition: a measure for a deeper understanding of survival prediction models
Mar 02, 2022
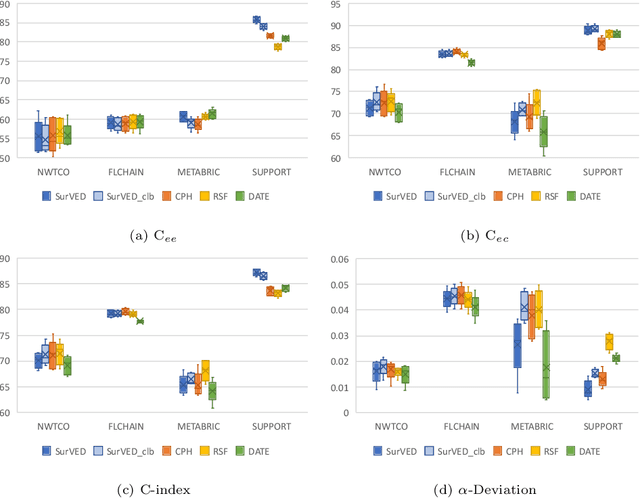
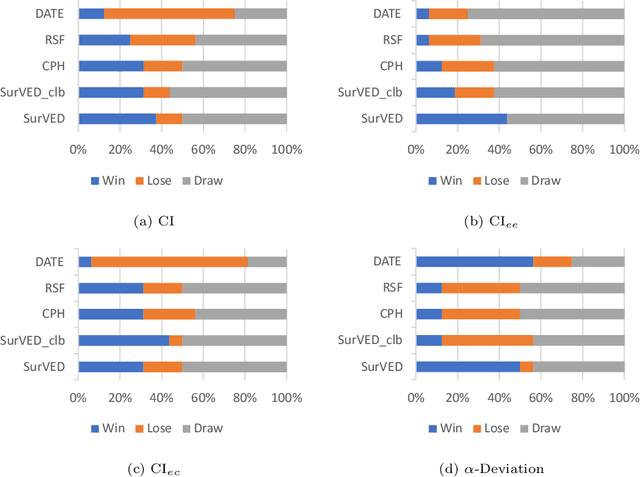

The Concordance Index (C-index) is a commonly used metric in Survival Analysis to evaluate how good a prediction model is. This paper proposes a decomposition of the C-Index into a weighted harmonic mean of two quantities: one for ranking observed events versus other observed events, and the other for ranking observed events versus censored cases. This decomposition allows a more fine-grained analysis of the pros and cons of survival prediction methods. The utility of the decomposition is demonstrated using three benchmark survival analysis models (Cox Proportional Hazard, Random Survival Forest, and Deep Adversarial Time-to-Event Network) together with a new variational generative neural-network-based method (SurVED), which is also proposed in this paper. The demonstration is done on four publicly available datasets with varying censoring levels. The analysis with the C-index decomposition shows that all methods essentially perform equally well when the censoring level is high because of the dominance of the term measuring the ranking of events versus censored cases. In contrast, some methods deteriorate when the censoring level decreases because they do not rank the events versus other events well.