 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Differentiating Between Failures and Domain Shifts in Industrial Data Streams
Mar 09, 2026Anomaly and failure detection methods are crucial in identifying deviations from normal system operational conditions, which allows for actions to be taken in advance, usually preventing more serious damages. Long-lasting deviations indicate failures, while sudden, isolated changes in the data indicate anomalies. However, in many practical applications, changes in the data do not always represent abnormal system states. Such changes may be recognized incorrectly as failures, while being a normal evolution of the system, e.g. referring to characteristics of starting the processing of a new product, i.e. realizing a domain shift. Therefore, distinguishing between failures and such ''healthy'' changes in data distribution is critical to ensure the practical robustness of the system. In this paper, we propose a method that not only detects changes in the data distribution and anomalies but also allows us to distinguish between failures and normal domain shifts inherent to a given process. The proposed method consists of a modified Page-Hinkley changepoint detector for identification of the domain shift and possible failures and supervised domain-adaptation-based algorithms for fast, online anomaly detection. These two are coupled with an explainable artificial intelligence (XAI) component that aims at helping the human operator to finally differentiate between domain shifts and failures. The method is illustrated by an experiment on a data stream from the steel factory.
Financial Management System for SMEs: Real-World Deployment of Accounts Receivable and Cash Flow Prediction
Nov 05, 2025Small and Medium Enterprises (SMEs), particularly freelancers and early-stage businesses, face unique financial management challenges due to limited resources, small customer bases, and constrained data availability. This paper presents the development and deployment of an integrated financial prediction system that combines accounts receivable prediction and cash flow forecasting specifically designed for SME operational constraints. Our system addresses the gap between enterprise-focused financial tools and the practical needs of freelancers and small businesses. The solution integrates two key components: a binary classification model for predicting invoice payment delays, and a multi-module cash flow forecasting model that handles incomplete and limited historical data. A prototype system has been implemented and deployed as a web application with integration into Cluee's platform, a startup providing financial management tools for freelancers, demonstrating practical feasibility for real-world SME financial management.
User-centric evaluation of explainability of AI with and for humans: a comprehensive empirical study
Oct 21, 2024

This study is located in the Human-Centered Artificial Intelligence (HCAI) and focuses on the results of a user-centered assessment of commonly used eXplainable Artificial Intelligence (XAI) algorithms, specifically investigating how humans understand and interact with the explanations provided by these algorithms. To achieve this, we employed a multi-disciplinary approach that included state-of-the-art research methods from social sciences to measure the comprehensibility of explanations generated by a state-of-the-art lachine learning model, specifically the Gradient Boosting Classifier (XGBClassifier). We conducted an extensive empirical user study involving interviews with 39 participants from three different groups, each with varying expertise in data science, data visualization, and domain-specific knowledge related to the dataset used for training the machine learning model. Participants were asked a series of questions to assess their understanding of the model's explanations. To ensure replicability, we built the model using a publicly available dataset from the UC Irvine Machine Learning Repository, focusing on edible and non-edible mushrooms. Our findings reveal limitations in existing XAI methods and confirm the need for new design principles and evaluation techniques that address the specific information needs and user perspectives of different classes of AI stakeholders. We believe that the results of our research and the cross-disciplinary methodology we developed can be successfully adapted to various data types and user profiles, thus promoting dialogue and address opportunities in HCAI research. To support this, we are making the data resulting from our study publicly available.
Local Universal Rule-based Explanations
Oct 23, 2023



Explainable artificial intelligence (XAI) is one of the most intensively developed are of AI in recent years. It is also one of the most fragmented one with multiple methods that focus on different aspects of explanations. This makes difficult to obtain the full spectrum of explanation at once in a compact and consistent way. To address this issue, we present Local Universal Explainer (LUX) that is a rule-based explainer which can generate factual, counterfactual and visual explanations. It is based on a modified version of decision tree algorithms that allows for oblique splits and integration with feature importance XAI methods such as SHAP or LIME. It does not use data generation in opposite to other algorithms, but is focused on selecting local concepts in a form of high-density clusters of real data that have the highest impact on forming the decision boundary of the explained model. We tested our method on real and synthetic datasets and compared it with state-of-the-art rule-based explainers such as LORE, EXPLAN and Anchor. Our method outperforms currently existing approaches in terms of simplicity, global fidelity and representativeness.
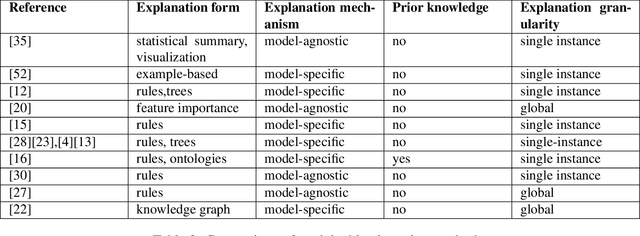
Explainable Predictive Maintenance
Jun 08, 2023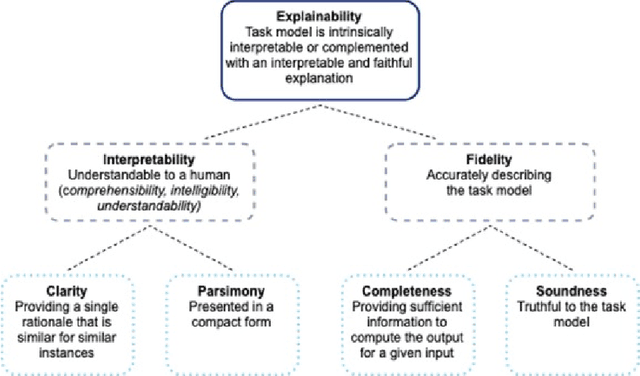

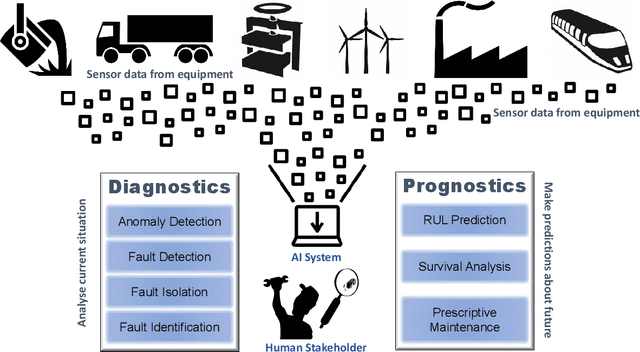
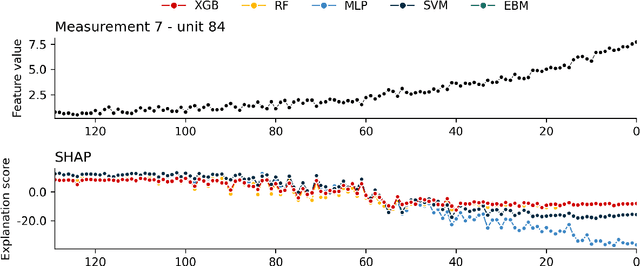
Explainable Artificial Intelligence (XAI) fills the role of a critical interface fostering interactions between sophisticated intelligent systems and diverse individuals, including data scientists, domain experts, end-users, and more. It aids in deciphering the intricate internal mechanisms of ``black box'' Machine Learning (ML), rendering the reasons behind their decisions more understandable. However, current research in XAI primarily focuses on two aspects; ways to facilitate user trust, or to debug and refine the ML model. The majority of it falls short of recognising the diverse types of explanations needed in broader contexts, as different users and varied application areas necessitate solutions tailored to their specific needs. One such domain is Predictive Maintenance (PdM), an exploding area of research under the Industry 4.0 \& 5.0 umbrella. This position paper highlights the gap between existing XAI methodologies and the specific requirements for explanations within industrial applications, particularly the Predictive Maintenance field. Despite explainability's crucial role, this subject remains a relatively under-explored area, making this paper a pioneering attempt to bring relevant challenges to the research community's attention. We provide an overview of predictive maintenance tasks and accentuate the need and varying purposes for corresponding explanations. We then list and describe XAI techniques commonly employed in the literature, discussing their suitability for PdM tasks. Finally, to make the ideas and claims more concrete, we demonstrate XAI applied in four specific industrial use cases: commercial vehicles, metro trains, steel plants, and wind farms, spotlighting areas requiring further research.
KnAC: an approach for enhancing cluster analysis with background knowledge and explanations
Dec 16, 2021
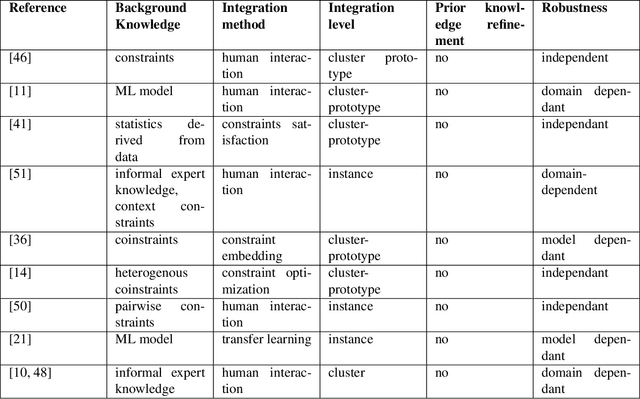
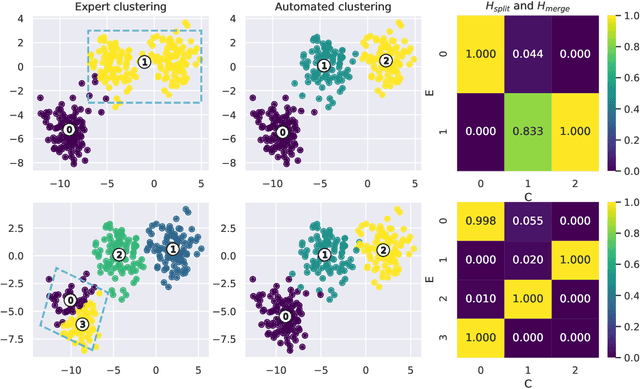
Pattern discovery in multidimensional data sets has been a subject of research since decades. There exists a wide spectrum of clustering algorithms that can be used for that purpose. However, their practical applications share in common the post-clustering phase, which concerns expert-based interpretation and analysis of the obtained results. We argue that this can be a bottleneck of the process, especially in the cases where domain knowledge exists prior to clustering. Such a situation requires not only a proper analysis of automatically discovered clusters, but also a conformance checking with existing knowledge. In this work, we present Knowledge Augmented Clustering (KnAC), which main goal is to confront expert-based labelling with automated clustering for the sake of updating and refining the former. Our solution does not depend on any ready clustering algorithm, nor introduce one. Instead KnAC can serve as an augmentation of an arbitrary clustering algorithm, making the approach robust and model-agnostic. We demonstrate the feasibility of our method on artificially, reproducible examples and on a real life use case scenario.
The BIRAFFE2 Experiment. Study in Bio-Reactions and Faces for Emotion-based Personalization for AI Systems
Jul 29, 2020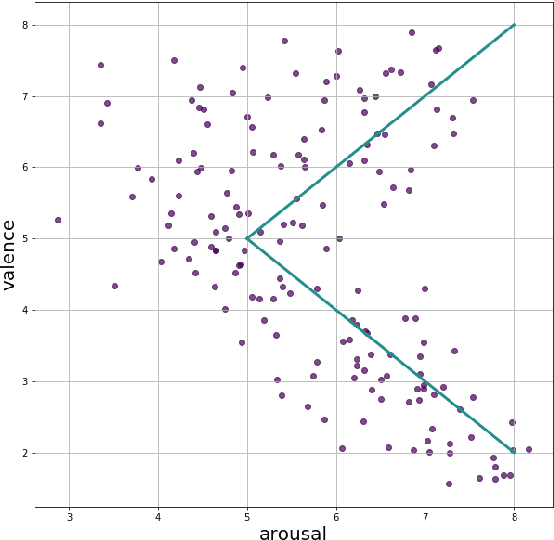


The paper describes BIRAFFE2 data set, which is a result of an affective computing experiment conducted between 2019 and 2020, that aimed to develop computer models for classification and recognition of emotion. Such work is important to develop new methods of natural Human-AI interaction. As we believe that models of emotion should be personalized by design, we present an unified paradigm allowing to capture emotional responses of different persons, taking individual personality differences into account. We combine classical psychological paradigms of emotional response collection with the newer approach, based on the observation of the computer game player. By capturing ones psycho-physiological reactions (ECG, EDA signal recording), mimic expressions (facial emotion recognition), subjective valence-arousal balance ratings (widget ratings) and gameplay progression (accelerometer and screencast recording), we provide a framework that can be easily used and developed for the purpose of the machine learning methods.