 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCase ID detection based on time series data -- the mining use case
Oct 31, 2024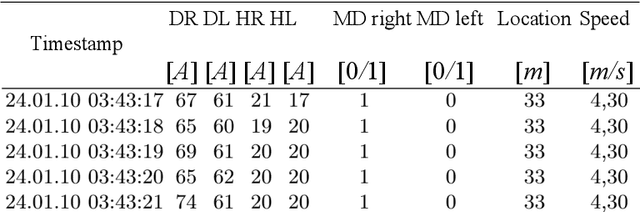
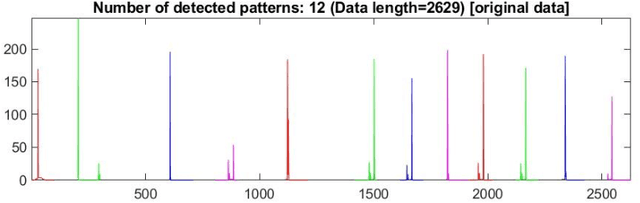
Process mining gains increasing popularity in business process analysis, also in heavy industry. It requires a specific data format called an event log, with the basic structure including a case identifier (case ID), activity (event) name, and timestamp. In the case of industrial processes, data is very often provided by a monitoring system as time series of low level sensor readings. This data cannot be directly used for process mining since there is no explicit marking of activities in the event log, and sometimes, case ID is not provided. We propose a novel rule-based algorithm for identification patterns, based on the identification of significant changes in short-term mean values of selected variable to detect case ID. We present our solution on the mining use case. We compare computed results (identified patterns) with expert labels of the same dataset. Experiments show that the developed algorithm in the most of the cases correctly detects IDs in datasets with and without outliers reaching F1 score values: 96.8% and 97% respectively. We also evaluate our algorithm on dataset from manufacturing domain reaching value 92.6% for F1 score.
KnAC: an approach for enhancing cluster analysis with background knowledge and explanations
Dec 16, 2021
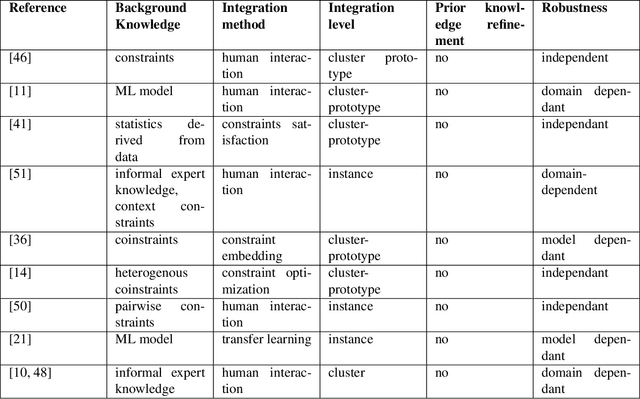
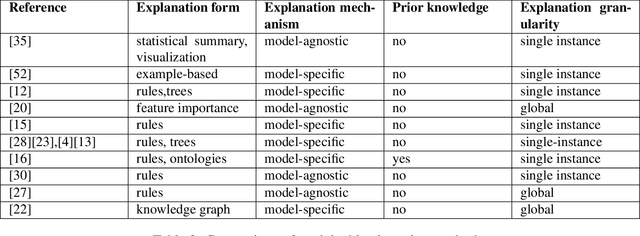
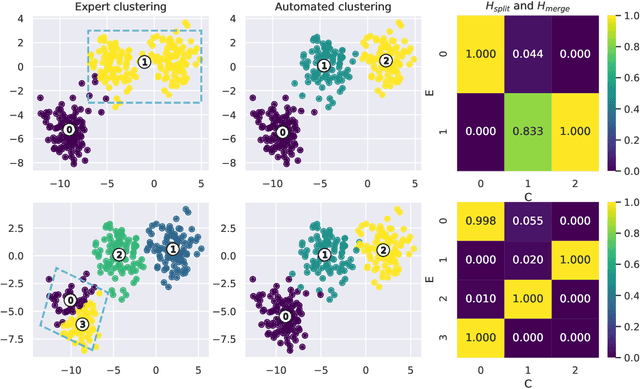
Pattern discovery in multidimensional data sets has been a subject of research since decades. There exists a wide spectrum of clustering algorithms that can be used for that purpose. However, their practical applications share in common the post-clustering phase, which concerns expert-based interpretation and analysis of the obtained results. We argue that this can be a bottleneck of the process, especially in the cases where domain knowledge exists prior to clustering. Such a situation requires not only a proper analysis of automatically discovered clusters, but also a conformance checking with existing knowledge. In this work, we present Knowledge Augmented Clustering (KnAC), which main goal is to confront expert-based labelling with automated clustering for the sake of updating and refining the former. Our solution does not depend on any ready clustering algorithm, nor introduce one. Instead KnAC can serve as an augmentation of an arbitrary clustering algorithm, making the approach robust and model-agnostic. We demonstrate the feasibility of our method on artificially, reproducible examples and on a real life use case scenario.