 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIconographic Classification and Content-Based Recommendation for Digitized Artworks
Feb 23, 2026We present a proof-of-concept system that automates iconographic classification and content-based recommendation of digitized artworks using the Iconclass vocabulary and selected artificial intelligence methods. The prototype implements a four-stage workflow for classification and recommendation, which integrates YOLOv8 object detection with algorithmic mappings to Iconclass codes, rule-based inference for abstract meanings, and three complementary recommenders (hierarchical proximity, IDF-weighted overlap, and Jaccard similarity). Although more engineering is still needed, the evaluation demonstrates the potential of this solution: Iconclass-aware computer vision and recommendation methods can accelerate cataloging and enhance navigation in large heritage repositories. The key insight is to let computer vision propose visible elements and to use symbolic structures (Iconclass hierarchy) to reach meaning.
A Three-stage Neuro-symbolic Recommendation Pipeline for Cultural Heritage Knowledge Graphs
Feb 23, 2026The growing volume of digital cultural heritage resources highlights the need for advanced recommendation methods capable of interpreting semantic relationships between heterogeneous data entities. This paper presents a complete methodology for implementing a hybrid recommendation pipeline integrating knowledge-graph embeddings, approximate nearest-neighbour search, and SPARQL-driven semantic filtering. The work is evaluated on the JUHMP (Jagiellonian University Heritage Metadata Portal) knowledge graph developed within the CHExRISH project, which at the time of experimentation contained ${\approx}3.2$M RDF triples describing people, events, objects, and historical relations affiliated with the Jagiellonian University (Kraków, PL). We evaluate four embedding families (TransE, ComplEx, ConvE, CompGCN) and perform hyperparameter selection for ComplEx and HNSW. Then, we present and evaluate the final three-stage neuro-symbolic recommender. Despite sparse and heterogeneous metadata, the approach produces useful and explainable recommendations, which were also proven with expert evaluation.
Position Paper: Metadata Enrichment Model: Integrating Neural Networks and Semantic Knowledge Graphs for Cultural Heritage Applications
May 29, 2025The digitization of cultural heritage collections has opened new directions for research, yet the lack of enriched metadata poses a substantial challenge to accessibility, interoperability, and cross-institutional collaboration. In several past years neural networks models such as YOLOv11 and Detectron2 have revolutionized visual data analysis, but their application to domain-specific cultural artifacts - such as manuscripts and incunabula - remains limited by the absence of methodologies that address structural feature extraction and semantic interoperability. In this position paper, we argue, that the integration of neural networks with semantic technologies represents a paradigm shift in cultural heritage digitization processes. We present the Metadata Enrichment Model (MEM), a conceptual framework designed to enrich metadata for digitized collections by combining fine-tuned computer vision models, large language models (LLMs) and structured knowledge graphs. The Multilayer Vision Mechanism (MVM) appears as the key innovation of MEM. This iterative process improves visual analysis by dynamically detecting nested features, such as text within seals or images within stamps. To expose MEM's potential, we apply it to a dataset of digitized incunabula from the Jagiellonian Digital Library and release a manually annotated dataset of 105 manuscript pages. We examine the practical challenges of MEM's usage in real-world GLAM institutions, including the need for domain-specific fine-tuning, the adjustment of enriched metadata with Linked Data standards and computational costs. We present MEM as a flexible and extensible methodology. This paper contributes to the discussion on how artificial intelligence and semantic web technologies can advance cultural heritage research, and also use these technologies in practice.
Advancing Manuscript Metadata: Work in Progress at the Jagiellonian University
Jul 09, 2024As part of ongoing research projects, three Jagiellonian University units -- the Jagiellonian University Museum, the Jagiellonian University Archives, and the Jagiellonian Library -- are collaborating to digitize cultural heritage documents, describe them in detail, and then integrate these descriptions into a linked data cloud. Achieving this goal requires, as a first step, the development of a metadata model that, on the one hand, complies with existing standards, on the other hand, allows interoperability with other systems, and on the third, captures all the elements of description established by the curators of the collections. In this paper, we present a report on the current status of the work, in which we outline the most important requirements for the data model under development and then make a detailed comparison with the two standards that are the most relevant from the point of view of collections: Europeana Data Model used in Europeana and Encoded Archival Description used in Kalliope.
Microsoft Cloud-based Digitization Workflow with Rich Metadata Acquisition for Cultural Heritage Objects
Jul 09, 2024In response to several cultural heritage initiatives at the Jagiellonian University, we have developed a new digitization workflow in collaboration with the Jagiellonian Library (JL). The solution is based on easy-to-access technological solutions -- Microsoft 365 cloud with MS Excel files as metadata acquisition interfaces, Office Script for validation, and MS Sharepoint for storage -- that allows metadata acquisition by domain experts (philologists, historians, philosophers, librarians, archivists, curators, etc.) regardless of their experience with information systems. The ultimate goal is to create a knowledge graph that describes the analyzed holdings, linked to general knowledge bases, as well as to other cultural heritage collections, so careful attention is paid to the high accuracy of metadata and proper links to external sources. The workflow has already been evaluated in two pilots in the DiHeLib project focused on digitizing the so-called "Berlin Collection" and in two workshops with international guests, which allowed for its refinement and confirmation of its correctness and usability for JL. As the proposed workflow does not interfere with existing systems or domain guidelines regarding digitization and basic metadata collection in a given institution (e.g., file type, image quality, use of Dublin Core/MARC-21), but extends them in order to enable rich metadata collection, not previously possible, we believe that it could be of interest to all GLAMs (galleries, libraries, archives, and museums).
Evaluation and Comparison of Emotionally Evocative Image Augmentation Methods
Jun 23, 2024Experiments in affective computing are based on stimulus datasets that, in the process of standardization, receive metadata describing which emotions each stimulus evokes. In this paper, we explore an approach to creating stimulus datasets for affective computing using generative adversarial networks (GANs). Traditional dataset preparation methods are costly and time consuming, prompting our investigation of alternatives. We conducted experiments with various GAN architectures, including Deep Convolutional GAN, Conditional GAN, Auxiliary Classifier GAN, Progressive Augmentation GAN, and Wasserstein GAN, alongside data augmentation and transfer learning techniques. Our findings highlight promising advances in the generation of emotionally evocative synthetic images, suggesting significant potential for future research and improvements in this domain.
The BIRAFFE2 Experiment. Study in Bio-Reactions and Faces for Emotion-based Personalization for AI Systems
Jul 29, 2020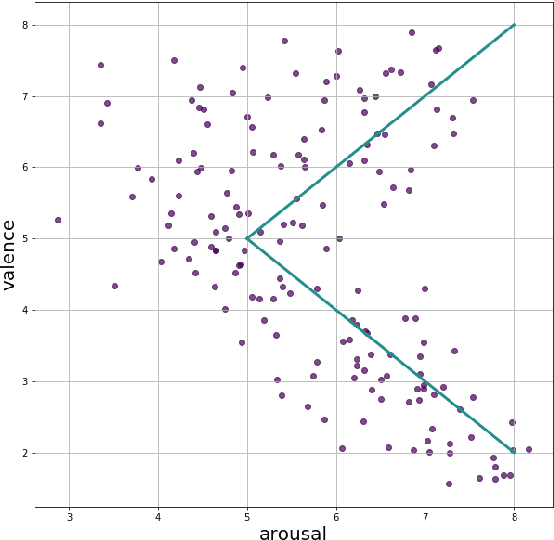
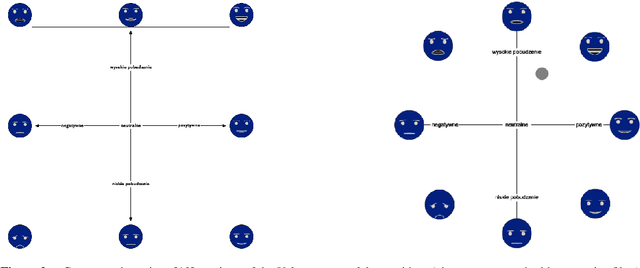


The paper describes BIRAFFE2 data set, which is a result of an affective computing experiment conducted between 2019 and 2020, that aimed to develop computer models for classification and recognition of emotion. Such work is important to develop new methods of natural Human-AI interaction. As we believe that models of emotion should be personalized by design, we present an unified paradigm allowing to capture emotional responses of different persons, taking individual personality differences into account. We combine classical psychological paradigms of emotional response collection with the newer approach, based on the observation of the computer game player. By capturing ones psycho-physiological reactions (ECG, EDA signal recording), mimic expressions (facial emotion recognition), subjective valence-arousal balance ratings (widget ratings) and gameplay progression (accelerometer and screencast recording), we provide a framework that can be easily used and developed for the purpose of the machine learning methods.