 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicrosoft Cloud-based Digitization Workflow with Rich Metadata Acquisition for Cultural Heritage Objects
Jul 09, 2024In response to several cultural heritage initiatives at the Jagiellonian University, we have developed a new digitization workflow in collaboration with the Jagiellonian Library (JL). The solution is based on easy-to-access technological solutions -- Microsoft 365 cloud with MS Excel files as metadata acquisition interfaces, Office Script for validation, and MS Sharepoint for storage -- that allows metadata acquisition by domain experts (philologists, historians, philosophers, librarians, archivists, curators, etc.) regardless of their experience with information systems. The ultimate goal is to create a knowledge graph that describes the analyzed holdings, linked to general knowledge bases, as well as to other cultural heritage collections, so careful attention is paid to the high accuracy of metadata and proper links to external sources. The workflow has already been evaluated in two pilots in the DiHeLib project focused on digitizing the so-called "Berlin Collection" and in two workshops with international guests, which allowed for its refinement and confirmation of its correctness and usability for JL. As the proposed workflow does not interfere with existing systems or domain guidelines regarding digitization and basic metadata collection in a given institution (e.g., file type, image quality, use of Dublin Core/MARC-21), but extends them in order to enable rich metadata collection, not previously possible, we believe that it could be of interest to all GLAMs (galleries, libraries, archives, and museums).
Efficient argument classification with compact language models and ChatGPT-4 refinements
Mar 20, 2024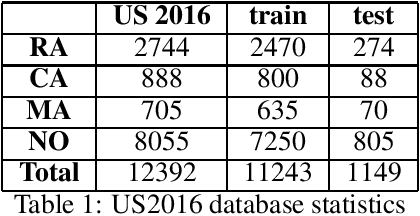


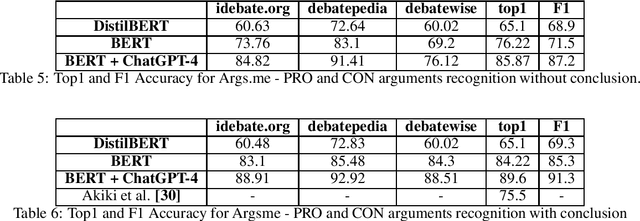
Argument mining (AM) is defined as the task of automatically identifying and extracting argumentative components (e.g. premises, claims, etc.) and detecting the existing relations among them (i.e., support, attack, no relations). Deep learning models enable us to analyze arguments more efficiently than traditional methods and extract their semantics. This paper presents comparative studies between a few deep learning-based models in argument mining. The work concentrates on argument classification. The research was done on a wide spectrum of datasets (Args.me, UKP, US2016). The main novelty of this paper is the ensemble model which is based on BERT architecture and ChatGPT-4 as fine tuning model. The presented results show that BERT+ChatGPT-4 outperforms the rest of the models including other Transformer-based and LSTM-based models. The observed improvement is, in most cases, greater than 10The presented analysis can provide crucial insights into how the models for argument classification should be further improved. Additionally, it can help develop a prompt-based algorithm to eliminate argument classification errors.