 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Harmonic Loss via Non-Euclidean Distance Layers
Mar 12, 2026Cross-entropy loss has long been the standard choice for training deep neural networks, yet it suffers from interpretability limitations, unbounded weight growth, and inefficiencies that can contribute to costly training dynamics. The harmonic loss is a distance-based alternative grounded in Euclidean geometry that improves interpretability and mitigates phenomena such as grokking, or delayed generalization on the test set. However, the study of harmonic loss remains narrow: only Euclidean distance is explored, and no systematic evaluation of computational efficiency or sustainability was conducted. We extend harmonic loss by systematically investigating a broad spectrum of distance metrics as replacements for the Euclidean distance. We comprehensively evaluate distance-tailored harmonic losses on both vision backbones and large language models. Our analysis is framed around a three-way evaluation of model performance, interpretability, and sustainability. On vision tasks, cosine distances provide the most favorable trade-off, consistently improving accuracy while lowering carbon emissions, whereas Bray-Curtis and Mahalanobis further enhance interpretability at varying efficiency costs. On language models, cosine-based harmonic losses improve gradient and learning stability, strengthen representation structure, and reduce emissions relative to cross-entropy and Euclidean heads. Our code is available at: https://anonymous.4open.science/r/rethinking-harmonic-loss-5BAB/.
Efficient argument classification with compact language models and ChatGPT-4 refinements
Mar 20, 2024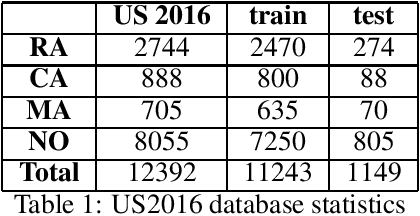


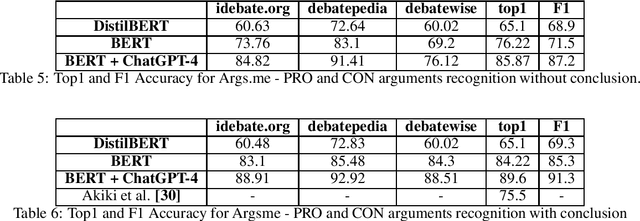
Argument mining (AM) is defined as the task of automatically identifying and extracting argumentative components (e.g. premises, claims, etc.) and detecting the existing relations among them (i.e., support, attack, no relations). Deep learning models enable us to analyze arguments more efficiently than traditional methods and extract their semantics. This paper presents comparative studies between a few deep learning-based models in argument mining. The work concentrates on argument classification. The research was done on a wide spectrum of datasets (Args.me, UKP, US2016). The main novelty of this paper is the ensemble model which is based on BERT architecture and ChatGPT-4 as fine tuning model. The presented results show that BERT+ChatGPT-4 outperforms the rest of the models including other Transformer-based and LSTM-based models. The observed improvement is, in most cases, greater than 10The presented analysis can provide crucial insights into how the models for argument classification should be further improved. Additionally, it can help develop a prompt-based algorithm to eliminate argument classification errors.
AD-NEV: A Scalable Multi-level Neuroevolution Framework for Multivariate Anomaly Detection
May 25, 2023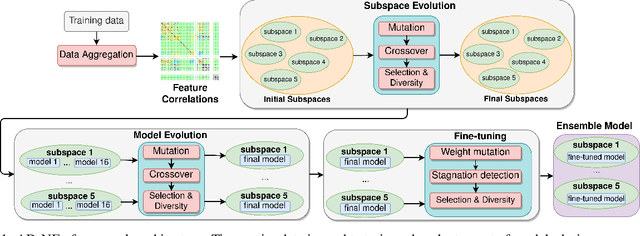
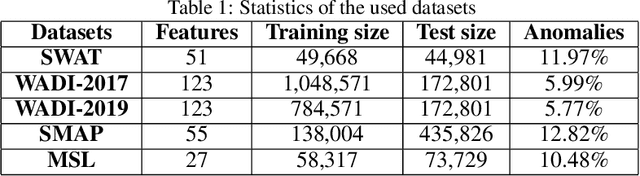
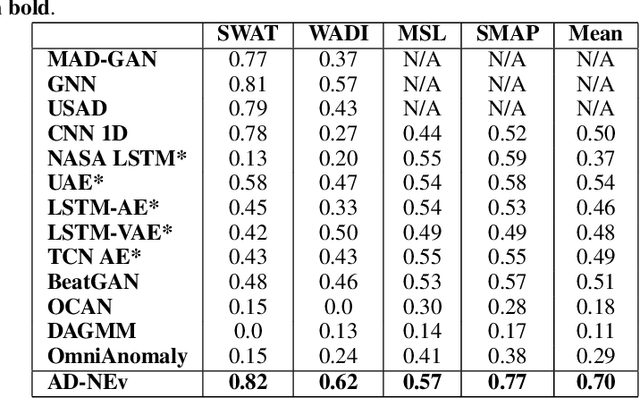
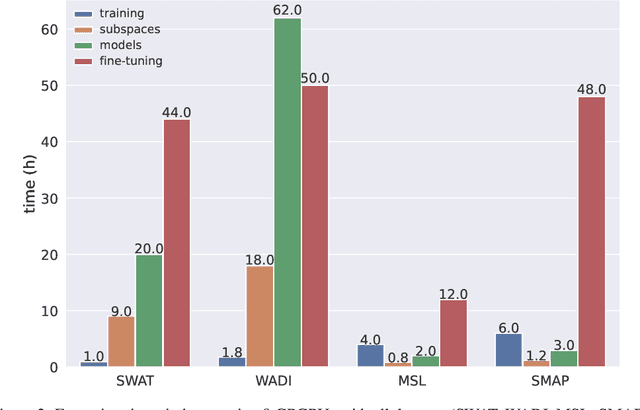
Anomaly detection tools and methods present a key capability in modern cyberphysical and failure prediction systems. Despite the fast-paced development in deep learning architectures for anomaly detection, model optimization for a given dataset is a cumbersome and time consuming process. Neuroevolution could be an effective and efficient solution to this problem, as a fully automated search method for learning optimal neural networks, supporting both gradient and non-gradient fine tuning. However, existing methods mostly focus on optimizing model architectures without taking into account feature subspaces and model weights. In this work, we propose Anomaly Detection Neuroevolution (AD-NEv) - a scalable multi-level optimized neuroevolution framework for multivariate time series anomaly detection. The method represents a novel approach to synergically: i) optimize feature subspaces for an ensemble model based on the bagging technique; ii) optimize the model architecture of single anomaly detection models; iii) perform non-gradient fine-tuning of network weights. An extensive experimental evaluation on widely adopted multivariate anomaly detection benchmark datasets shows that the models extracted by AD-NEv outperform well-known deep learning architectures for anomaly detection. Moreover, results show that AD-NEv can perform the whole process efficiently, presenting high scalability when multiple GPUs are available.
From MNIST to ImageNet and Back: Benchmarking Continual Curriculum Learning
Mar 16, 2023Continual learning (CL) is one of the most promising trends in recent machine learning research. Its goal is to go beyond classical assumptions in machine learning and develop models and learning strategies that present high robustness in dynamic environments. The landscape of CL research is fragmented into several learning evaluation protocols, comprising different learning tasks, datasets, and evaluation metrics. Additionally, the benchmarks adopted so far are still distant from the complexity of real-world scenarios, and are usually tailored to highlight capabilities specific to certain strategies. In such a landscape, it is hard to objectively assess strategies. In this work, we fill this gap for CL on image data by introducing two novel CL benchmarks that involve multiple heterogeneous tasks from six image datasets, with varying levels of complexity and quality. Our aim is to fairly evaluate current state-of-the-art CL strategies on a common ground that is closer to complex real-world scenarios. We additionally structure our benchmarks so that tasks are presented in increasing and decreasing order of complexity -- according to a curriculum -- in order to evaluate if current CL models are able to exploit structure across tasks. We devote particular emphasis to providing the CL community with a rigorous and reproducible evaluation protocol for measuring the ability of a model to generalize and not to forget while learning. Furthermore, we provide an extensive experimental evaluation showing that popular CL strategies, when challenged with our benchmarks, yield sub-par performance, high levels of forgetting, and present a limited ability to effectively leverage curriculum task ordering. We believe that these results highlight the need for rigorous comparisons in future CL works as well as pave the way to design new CL strategies that are able to deal with more complex scenarios.
Context based lemmatizer for Polish language
Jul 23, 2022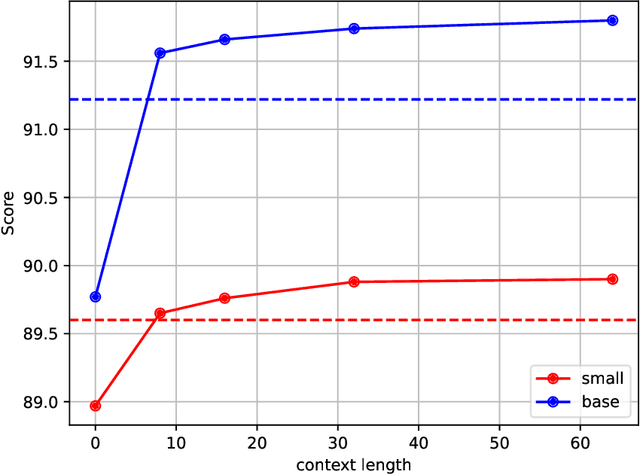
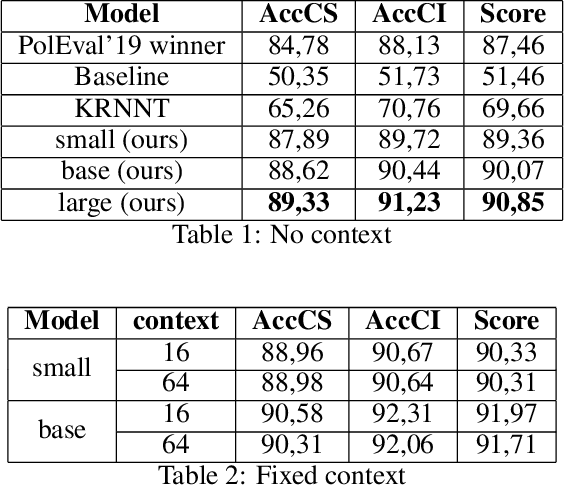
Lemmatization is the process of grouping together the inflected forms of a word so they can be analysed as a single item, identified by the word's lemma, or dictionary form. In computational linguistics, lemmatisation is the algorithmic process of determining the lemma of a word based on its intended meaning. Unlike stemming, lemmatisation depends on correctly identifying the intended part of speech and meaning of a word in a sentence, as well as within the larger context surrounding that sentence. As a result, developing efficient lemmatisation algorithm is the complex task. In recent years it can be observed that deep learning models used for this task outperform other methods including machine learning algorithms. In this paper the polish lemmatizer based on Google T5 model is presented. The training was run with different context lengths. The model achieves the best results for polish language lemmatisation process.
Retrain or not retrain? -- efficient pruning methods of deep CNN networks
Feb 12, 2020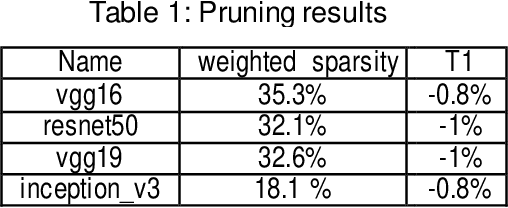
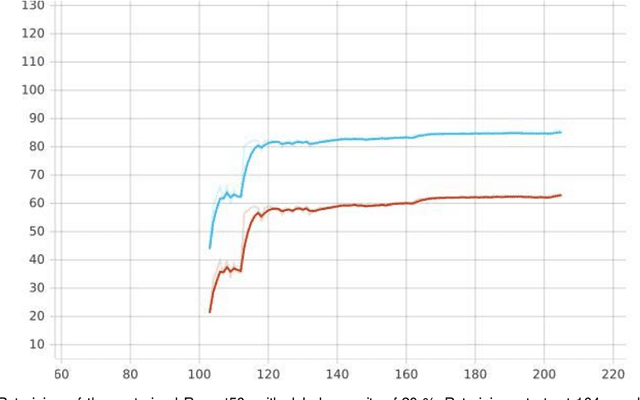
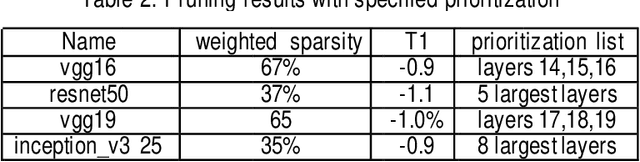
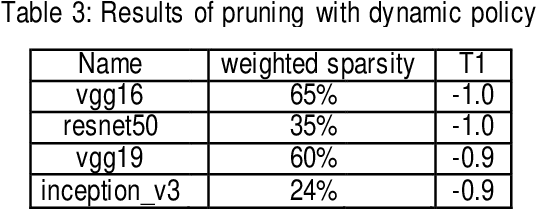
Convolutional neural networks (CNN) play a major role in image processing tasks like image classification, object detection, semantic segmentation. Very often CNN networks have from several to hundred stacked layers with several megabytes of weights. One of the possible methods to reduce complexity and memory footprint is pruning. Pruning is a process of removing weights which connect neurons from two adjacent layers in the network. The process of finding near optimal solution with specified drop in accuracy can be more sophisticated when DL model has higher number of convolutional layers. In the paper few approaches based on retraining and no retraining are described and compared together.
Ensemble approach for natural language question answering problem
Aug 28, 2019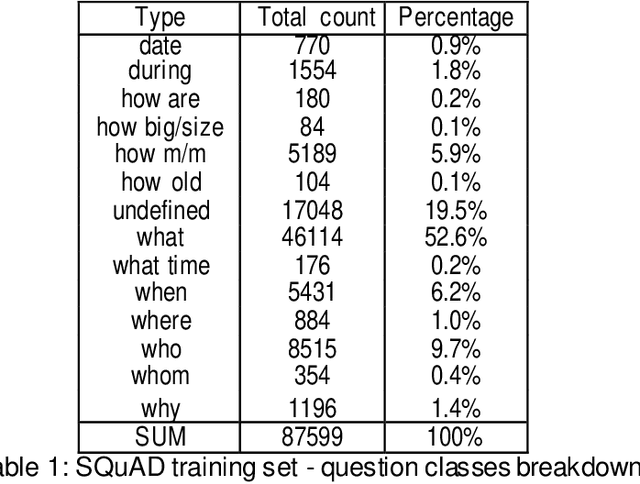
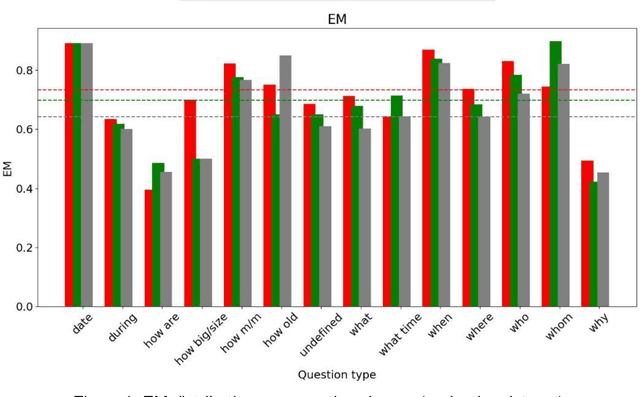
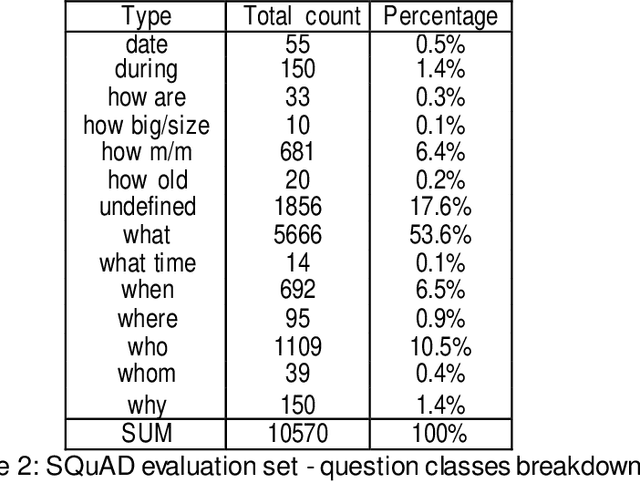
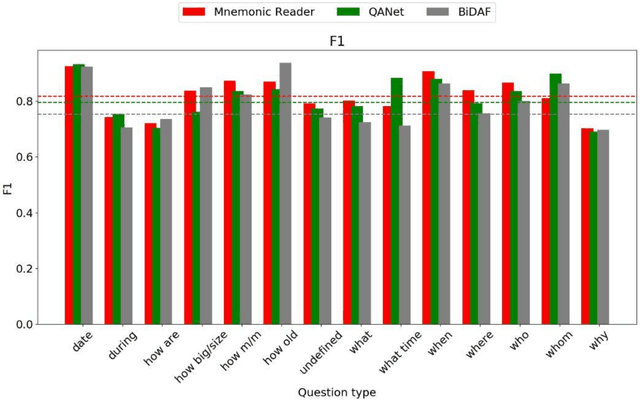
Machine comprehension, answering a question depending on a given context paragraph is a typical task of Natural Language Understanding. It requires to model complex dependencies existing between the question and the context paragraph. There are many neural network models attempting to solve the problem of question answering. The best models have been selected, studied and compared with each other. All the selected models are based on the neural attention mechanism concept. Additionally, studies on a SQUAD dataset were performed. The subsets of queries were extracted and then each model was analyzed how it deals with specific group of queries. Based on these three model ensemble model was created and tested on SQUAD dataset. It outperforms the best Mnemonic Reader model.
Method for Hybrid Precision Convolutional Neural Network Representation
Jul 24, 2018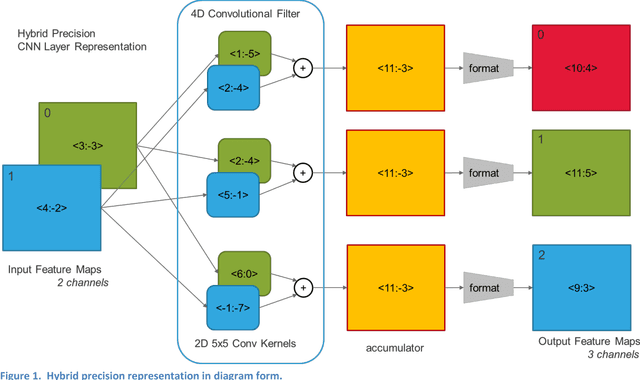
This invention addresses fixed-point representations of convolutional neural networks (CNN) in integrated circuits. When quantizing a CNN for a practical implementation there is a trade-off between the precision used for operations between coefficients and data and the accuracy of the system. A homogenous representation may not be sufficient to achieve the best level of performance at a reasonable cost in implementation complexity or power consumption. Parsimonious ways of representing data and coefficients are needed to improve power efficiency and throughput while maintaining accuracy of a CNN.