 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSN-Affinity: Similarity-Driven Parameter Reuse for Continual Offline Reinforcement Learning
Apr 28, 2026Continual offline reinforcement learning (CORL) aims to learn a sequence of tasks from datasets collected over time while preserving performance on previously learned tasks. This setting corresponds to domains where new tasks arise over time, but adapting the model in live environment interactions is expensive, risky, or impossible. However, CORL inherits the dual difficulty of offline reinforcement learning and adapting while preventing catastrophic forgetting. Replay-based continual learning approaches remain a strong baseline but incur memory overhead and suffer from a distribution mismatch between replayed samples and newly learned policies. At the same time, architectural continual learning methods have shown strong potential in supervised learning but remain underexplored in CORL. In this work, we propose TSN-Affinity, a novel CORL method based on TinySubNetworks and Decision Transformer. The method enables task-specific parameterization and controlled knowledge sharing through a RL-aware reuse strategy that routes tasks according to action compatibility and latent similarity. We evaluate the approach on benchmarks based on Atari games and simulations of manipulation tasks with the Franka Emika Panda robotic arm, covering both discrete and continuous control. Results show strong retention from sparse SubNetworks, with routing further improving multi-task performance. Our findings suggest that similarity-guided architectural reuse is a strong and viable alternative to replay-based strategies in a CORL setting. Our code is available at: https://github.com/anonymized-for-submission123/tsn-affinity.
Rethinking the Harmonic Loss via Non-Euclidean Distance Layers
Mar 12, 2026Cross-entropy loss has long been the standard choice for training deep neural networks, yet it suffers from interpretability limitations, unbounded weight growth, and inefficiencies that can contribute to costly training dynamics. The harmonic loss is a distance-based alternative grounded in Euclidean geometry that improves interpretability and mitigates phenomena such as grokking, or delayed generalization on the test set. However, the study of harmonic loss remains narrow: only Euclidean distance is explored, and no systematic evaluation of computational efficiency or sustainability was conducted. We extend harmonic loss by systematically investigating a broad spectrum of distance metrics as replacements for the Euclidean distance. We comprehensively evaluate distance-tailored harmonic losses on both vision backbones and large language models. Our analysis is framed around a three-way evaluation of model performance, interpretability, and sustainability. On vision tasks, cosine distances provide the most favorable trade-off, consistently improving accuracy while lowering carbon emissions, whereas Bray-Curtis and Mahalanobis further enhance interpretability at varying efficiency costs. On language models, cosine-based harmonic losses improve gradient and learning stability, strengthen representation structure, and reduce emissions relative to cross-entropy and Euclidean heads. Our code is available at: https://anonymous.4open.science/r/rethinking-harmonic-loss-5BAB/.
TinySubNets: An efficient and low capacity continual learning strategy
Dec 14, 2024



Continual Learning (CL) is a highly relevant setting gaining traction in recent machine learning research. Among CL works, architectural and hybrid strategies are particularly effective due to their potential to adapt the model architecture as new tasks are presented. However, many existing solutions do not efficiently exploit model sparsity, and are prone to capacity saturation due to their inefficient use of available weights, which limits the number of learnable tasks. In this paper, we propose TinySubNets (TSN), a novel architectural CL strategy that addresses the issues through the unique combination of pruning with different sparsity levels, adaptive quantization, and weight sharing. Pruning identifies a subset of weights that preserve model performance, making less relevant weights available for future tasks. Adaptive quantization allows a single weight to be separated into multiple parts which can be assigned to different tasks. Weight sharing between tasks boosts the exploitation of capacity and task similarity, allowing for the identification of a better trade-off between model accuracy and capacity. These features allow TSN to efficiently leverage the available capacity, enhance knowledge transfer, and reduce computational resource consumption. Experimental results involving common benchmark CL datasets and scenarios show that our proposed strategy achieves better results in terms of accuracy than existing state-of-the-art CL strategies. Moreover, our strategy is shown to provide a significantly improved model capacity exploitation. Code released at: https://github.com/lifelonglab/tinysubnets.
Solving Multi-Goal Robotic Tasks with Decision Transformer
Oct 08, 2024



Artificial intelligence plays a crucial role in robotics, with reinforcement learning (RL) emerging as one of the most promising approaches for robot control. However, several key challenges hinder its broader application. First, many RL methods rely on online learning, which requires either real-world hardware or advanced simulation environments--both of which can be costly, time-consuming, and impractical. Offline reinforcement learning offers a solution, enabling models to be trained without ongoing access to physical robots or simulations. A second challenge is learning multi-goal tasks, where robots must achieve multiple objectives simultaneously. This adds complexity to the training process, as the model must generalize across different goals. At the same time, transformer architectures have gained significant popularity across various domains, including reinforcement learning. Yet, no existing methods effectively combine offline training, multi-goal learning, and transformer-based architectures. In this paper, we address these challenges by introducing a novel adaptation of the decision transformer architecture for offline multi-goal reinforcement learning in robotics. Our approach integrates goal-specific information into the decision transformer, allowing it to handle complex tasks in an offline setting. To validate our method, we developed a new offline reinforcement learning dataset using the Panda robotic platform in simulation. Our extensive experiments demonstrate that the decision transformer can outperform state-of-the-art online reinforcement learning methods.
Towards efficient deep autoencoders for multivariate time series anomaly detection
Mar 04, 2024



Multivariate time series anomaly detection is a crucial problem in many industrial and research applications. Timely detection of anomalies allows, for instance, to prevent defects in manufacturing processes and failures in cyberphysical systems. Deep learning methods are preferred among others for their accuracy and robustness for the analysis of complex multivariate data. However, a key aspect is being able to extract predictions in a timely manner, to accommodate real-time requirements in different applications. In the case of deep learning models, model reduction is extremely important to achieve optimal results in real-time systems with limited time and memory constraints. In this paper, we address this issue by proposing a novel compression method for deep autoencoders that involves three key factors. First, pruning reduces the number of weights, while preventing catastrophic drops in accuracy by means of a fast search process that identifies high sparsity levels. Second, linear and non-linear quantization reduces model complexity by reducing the number of bits for every single weight. The combined contribution of these three aspects allow the model size to be reduced, by removing a subset of the weights (pruning), and decreasing their bit-width (quantization). As a result, the compressed model is faster and easier to adopt in highly constrained hardware environments. Experiments performed on popular multivariate anomaly detection benchmarks, show that our method is capable of achieving significant model compression ratio (between 80% and 95%) without a significant reduction in the anomaly detection performance.
Ada-QPacknet -- adaptive pruning with bit width reduction as an efficient continual learning method without forgetting
Aug 14, 2023



Continual Learning (CL) is a process in which there is still huge gap between human and deep learning model efficiency. Recently, many CL algorithms were designed. Most of them have many problems with learning in dynamic and complex environments. In this work new architecture based approach Ada-QPacknet is described. It incorporates the pruning for extracting the sub-network for each task. The crucial aspect in architecture based CL methods is theirs capacity. In presented method the size of the model is reduced by efficient linear and nonlinear quantisation approach. The method reduces the bit-width of the weights format. The presented results shows that hybrid 8 and 4-bit quantisation achieves similar accuracy as floating-point sub-network on a well-know CL scenarios. To our knowledge it is the first CL strategy which incorporates both compression techniques pruning and quantisation for generating task sub-networks. The presented algorithm was tested on well-known episode combinations and compared with most popular algorithms. Results show that proposed approach outperforms most of the CL strategies in task and class incremental scenarios.
AD-NEV: A Scalable Multi-level Neuroevolution Framework for Multivariate Anomaly Detection
May 25, 2023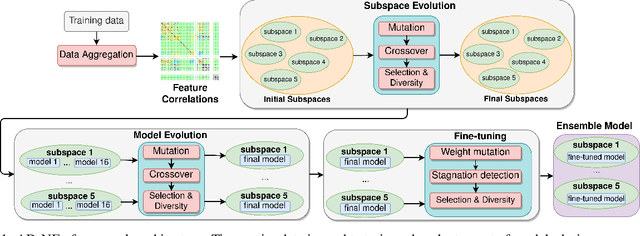
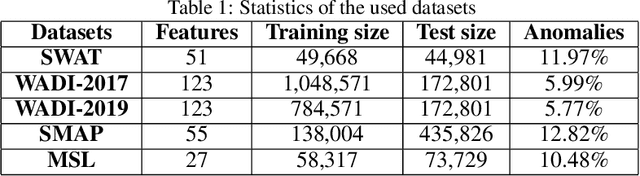
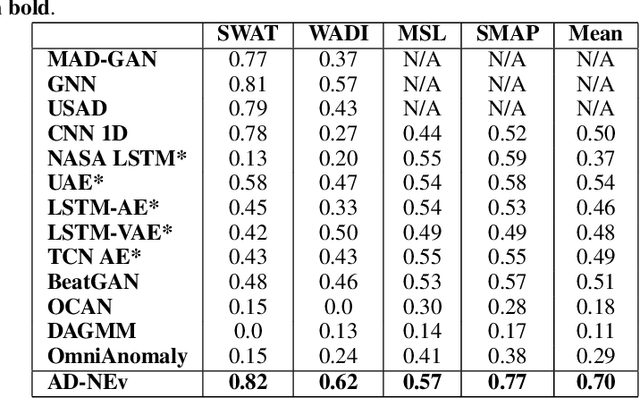
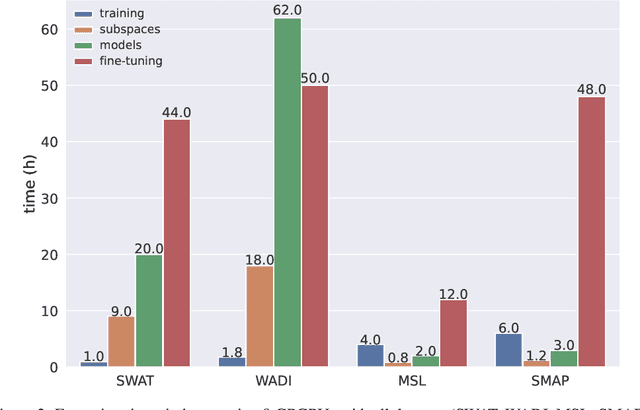
Anomaly detection tools and methods present a key capability in modern cyberphysical and failure prediction systems. Despite the fast-paced development in deep learning architectures for anomaly detection, model optimization for a given dataset is a cumbersome and time consuming process. Neuroevolution could be an effective and efficient solution to this problem, as a fully automated search method for learning optimal neural networks, supporting both gradient and non-gradient fine tuning. However, existing methods mostly focus on optimizing model architectures without taking into account feature subspaces and model weights. In this work, we propose Anomaly Detection Neuroevolution (AD-NEv) - a scalable multi-level optimized neuroevolution framework for multivariate time series anomaly detection. The method represents a novel approach to synergically: i) optimize feature subspaces for an ensemble model based on the bagging technique; ii) optimize the model architecture of single anomaly detection models; iii) perform non-gradient fine-tuning of network weights. An extensive experimental evaluation on widely adopted multivariate anomaly detection benchmark datasets shows that the models extracted by AD-NEv outperform well-known deep learning architectures for anomaly detection. Moreover, results show that AD-NEv can perform the whole process efficiently, presenting high scalability when multiple GPUs are available.
From MNIST to ImageNet and Back: Benchmarking Continual Curriculum Learning
Mar 16, 2023Continual learning (CL) is one of the most promising trends in recent machine learning research. Its goal is to go beyond classical assumptions in machine learning and develop models and learning strategies that present high robustness in dynamic environments. The landscape of CL research is fragmented into several learning evaluation protocols, comprising different learning tasks, datasets, and evaluation metrics. Additionally, the benchmarks adopted so far are still distant from the complexity of real-world scenarios, and are usually tailored to highlight capabilities specific to certain strategies. In such a landscape, it is hard to objectively assess strategies. In this work, we fill this gap for CL on image data by introducing two novel CL benchmarks that involve multiple heterogeneous tasks from six image datasets, with varying levels of complexity and quality. Our aim is to fairly evaluate current state-of-the-art CL strategies on a common ground that is closer to complex real-world scenarios. We additionally structure our benchmarks so that tasks are presented in increasing and decreasing order of complexity -- according to a curriculum -- in order to evaluate if current CL models are able to exploit structure across tasks. We devote particular emphasis to providing the CL community with a rigorous and reproducible evaluation protocol for measuring the ability of a model to generalize and not to forget while learning. Furthermore, we provide an extensive experimental evaluation showing that popular CL strategies, when challenged with our benchmarks, yield sub-par performance, high levels of forgetting, and present a limited ability to effectively leverage curriculum task ordering. We believe that these results highlight the need for rigorous comparisons in future CL works as well as pave the way to design new CL strategies that are able to deal with more complex scenarios.
Lifelong Learning for Anomaly Detection: New Challenges, Perspectives, and Insights
Mar 14, 2023



Anomaly detection is of paramount importance in many real-world domains, characterized by evolving behavior. Lifelong learning represents an emerging trend, answering the need for machine learning models that continuously adapt to new challenges in dynamic environments while retaining past knowledge. However, limited efforts are dedicated to building foundations for lifelong anomaly detection, which provides intrinsically different challenges compared to the more widely explored classification setting. In this paper, we face this issue by exploring, motivating, and discussing lifelong anomaly detection, trying to build foundations for its wider adoption. First, we explain why lifelong anomaly detection is relevant, defining challenges and opportunities to design anomaly detection methods that deal with lifelong learning complexities. Second, we characterize learning settings and a scenario generation procedure that enables researchers to experiment with lifelong anomaly detection using existing datasets. Third, we perform experiments with popular anomaly detection methods on proposed lifelong scenarios, emphasizing the gap in performance that could be gained with the adoption of lifelong learning. Overall, we conclude that the adoption of lifelong anomaly detection is important to design more robust models that provide a comprehensive view of the environment, as well as simultaneous adaptation and knowledge retention.
System Design for an Integrated Lifelong Reinforcement Learning Agent for Real-Time Strategy Games
Dec 08, 2022

As Artificial and Robotic Systems are increasingly deployed and relied upon for real-world applications, it is important that they exhibit the ability to continually learn and adapt in dynamically-changing environments, becoming Lifelong Learning Machines. Continual/lifelong learning (LL) involves minimizing catastrophic forgetting of old tasks while maximizing a model's capability to learn new tasks. This paper addresses the challenging lifelong reinforcement learning (L2RL) setting. Pushing the state-of-the-art forward in L2RL and making L2RL useful for practical applications requires more than developing individual L2RL algorithms; it requires making progress at the systems-level, especially research into the non-trivial problem of how to integrate multiple L2RL algorithms into a common framework. In this paper, we introduce the Lifelong Reinforcement Learning Components Framework (L2RLCF), which standardizes L2RL systems and assimilates different continual learning components (each addressing different aspects of the lifelong learning problem) into a unified system. As an instantiation of L2RLCF, we develop a standard API allowing easy integration of novel lifelong learning components. We describe a case study that demonstrates how multiple independently-developed LL components can be integrated into a single realized system. We also introduce an evaluation environment in order to measure the effect of combining various system components. Our evaluation environment employs different LL scenarios (sequences of tasks) consisting of Starcraft-2 minigames and allows for the fair, comprehensive, and quantitative comparison of different combinations of components within a challenging common evaluation environment.