 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinySubNets: An efficient and low capacity continual learning strategy
Dec 14, 2024



Continual Learning (CL) is a highly relevant setting gaining traction in recent machine learning research. Among CL works, architectural and hybrid strategies are particularly effective due to their potential to adapt the model architecture as new tasks are presented. However, many existing solutions do not efficiently exploit model sparsity, and are prone to capacity saturation due to their inefficient use of available weights, which limits the number of learnable tasks. In this paper, we propose TinySubNets (TSN), a novel architectural CL strategy that addresses the issues through the unique combination of pruning with different sparsity levels, adaptive quantization, and weight sharing. Pruning identifies a subset of weights that preserve model performance, making less relevant weights available for future tasks. Adaptive quantization allows a single weight to be separated into multiple parts which can be assigned to different tasks. Weight sharing between tasks boosts the exploitation of capacity and task similarity, allowing for the identification of a better trade-off between model accuracy and capacity. These features allow TSN to efficiently leverage the available capacity, enhance knowledge transfer, and reduce computational resource consumption. Experimental results involving common benchmark CL datasets and scenarios show that our proposed strategy achieves better results in terms of accuracy than existing state-of-the-art CL strategies. Moreover, our strategy is shown to provide a significantly improved model capacity exploitation. Code released at: https://github.com/lifelonglab/tinysubnets.
Solving Multi-Goal Robotic Tasks with Decision Transformer
Oct 08, 2024



Artificial intelligence plays a crucial role in robotics, with reinforcement learning (RL) emerging as one of the most promising approaches for robot control. However, several key challenges hinder its broader application. First, many RL methods rely on online learning, which requires either real-world hardware or advanced simulation environments--both of which can be costly, time-consuming, and impractical. Offline reinforcement learning offers a solution, enabling models to be trained without ongoing access to physical robots or simulations. A second challenge is learning multi-goal tasks, where robots must achieve multiple objectives simultaneously. This adds complexity to the training process, as the model must generalize across different goals. At the same time, transformer architectures have gained significant popularity across various domains, including reinforcement learning. Yet, no existing methods effectively combine offline training, multi-goal learning, and transformer-based architectures. In this paper, we address these challenges by introducing a novel adaptation of the decision transformer architecture for offline multi-goal reinforcement learning in robotics. Our approach integrates goal-specific information into the decision transformer, allowing it to handle complex tasks in an offline setting. To validate our method, we developed a new offline reinforcement learning dataset using the Panda robotic platform in simulation. Our extensive experiments demonstrate that the decision transformer can outperform state-of-the-art online reinforcement learning methods.
Towards efficient deep autoencoders for multivariate time series anomaly detection
Mar 04, 2024



Multivariate time series anomaly detection is a crucial problem in many industrial and research applications. Timely detection of anomalies allows, for instance, to prevent defects in manufacturing processes and failures in cyberphysical systems. Deep learning methods are preferred among others for their accuracy and robustness for the analysis of complex multivariate data. However, a key aspect is being able to extract predictions in a timely manner, to accommodate real-time requirements in different applications. In the case of deep learning models, model reduction is extremely important to achieve optimal results in real-time systems with limited time and memory constraints. In this paper, we address this issue by proposing a novel compression method for deep autoencoders that involves three key factors. First, pruning reduces the number of weights, while preventing catastrophic drops in accuracy by means of a fast search process that identifies high sparsity levels. Second, linear and non-linear quantization reduces model complexity by reducing the number of bits for every single weight. The combined contribution of these three aspects allow the model size to be reduced, by removing a subset of the weights (pruning), and decreasing their bit-width (quantization). As a result, the compressed model is faster and easier to adopt in highly constrained hardware environments. Experiments performed on popular multivariate anomaly detection benchmarks, show that our method is capable of achieving significant model compression ratio (between 80% and 95%) without a significant reduction in the anomaly detection performance.
Ada-QPacknet -- adaptive pruning with bit width reduction as an efficient continual learning method without forgetting
Aug 14, 2023



Continual Learning (CL) is a process in which there is still huge gap between human and deep learning model efficiency. Recently, many CL algorithms were designed. Most of them have many problems with learning in dynamic and complex environments. In this work new architecture based approach Ada-QPacknet is described. It incorporates the pruning for extracting the sub-network for each task. The crucial aspect in architecture based CL methods is theirs capacity. In presented method the size of the model is reduced by efficient linear and nonlinear quantisation approach. The method reduces the bit-width of the weights format. The presented results shows that hybrid 8 and 4-bit quantisation achieves similar accuracy as floating-point sub-network on a well-know CL scenarios. To our knowledge it is the first CL strategy which incorporates both compression techniques pruning and quantisation for generating task sub-networks. The presented algorithm was tested on well-known episode combinations and compared with most popular algorithms. Results show that proposed approach outperforms most of the CL strategies in task and class incremental scenarios.
Speedup deep learning models on GPU by taking advantage of efficient unstructured pruning and bit-width reduction
Dec 28, 2021

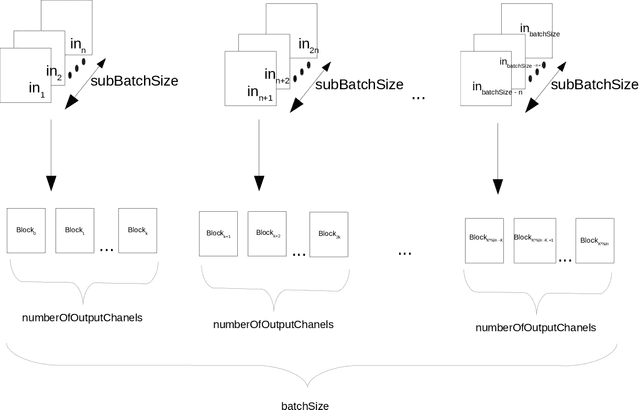
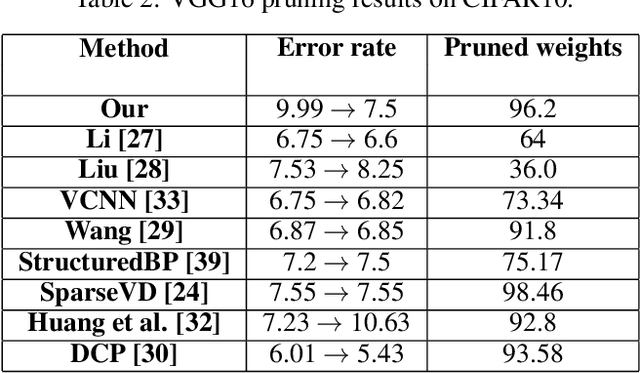
This work is focused on the pruning of some convolutional neural networks (CNNs) and improving theirs efficiency on graphic processing units (GPU) by using a direct sparse algorithm. The Nvidia deep neural network (cuDnn) library is the most effective implementations of deep learning (DL) algorithms for GPUs. GPUs are the most commonly used accelerators for deep learning computations. One of the most common techniques for improving the efficiency of CNN models is weight pruning and quantization. There are two main types of pruning: structural and non-structural. The first enables much easier acceleration on many type of accelerators, but with this type it is difficult to achieve a sparsity level and accuracy as high as that obtained with the second type. Non-structural pruning with retraining can generate a weight tensors up to 90% or more of sparsity in some deep CNN models. In this article the pruning algorithm is presented which makes it possible to achieve high sparsity levels without accuracy drop. In the next stage the linear and non-linear quantization is adapted for further time and footprint reduction. This paper is an extended of previously published paper concerning effective pruning techniques and present real models pruned with high sparsities and reduced precision which can achieve better performance than the CuDnn library.
Ensemble neuroevolution based approach for multivariate time series anomaly detection
Aug 08, 2021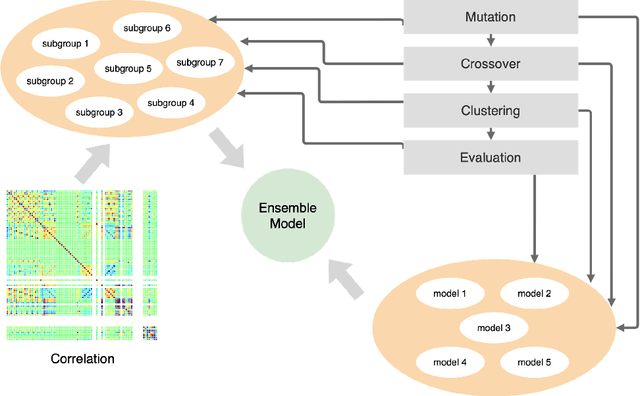
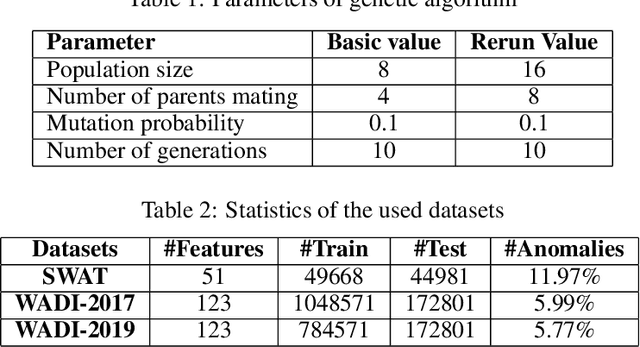
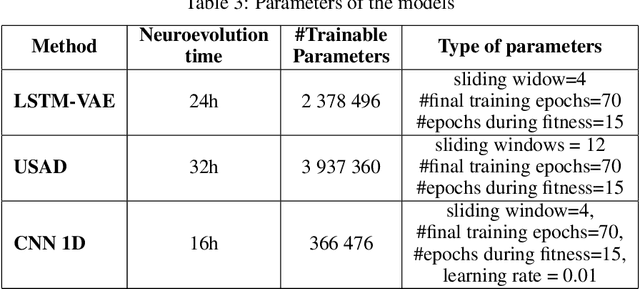
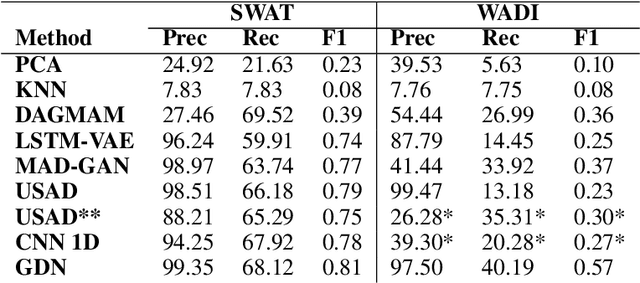
Multivariate time series anomaly detection is a very common problem in the field of failure prevention. Fast prevention means lower repair costs and losses. The amount of sensors in novel industry systems makes the anomaly detection process quite difficult for humans. Algorithms which automates the process of detecting anomalies are crucial in modern failure-prevention systems. Therefore, many machine and deep learning models have been designed to address this problem. Mostly, they are autoencoder-based architectures with some generative adversarial elements. In this work, a framework is shown which incorporates neuroevolution methods to boost the anomaly-detection scores of new and already known models. The presented approach adapts evolution strategies for evolving ensemble model, in which every single model works on a subgroup of data sensors. The next goal of neuroevolution is to optimise architecture and hyperparameters like window size, the number of layers, layer depths, etc. The proposed framework shows that it is possible to boost most of the anomaly detection deep learning models in a reasonable time and a fully automated mode. The tests were run on SWAT and WADI datasets. To our knowledge, this is the first approach in which an ensemble deep learning anomaly detection model is built in a fully automatic way using a neuroevolution strategy.
Training with reduced precision of a support vector machine model for text classification
Jul 17, 2020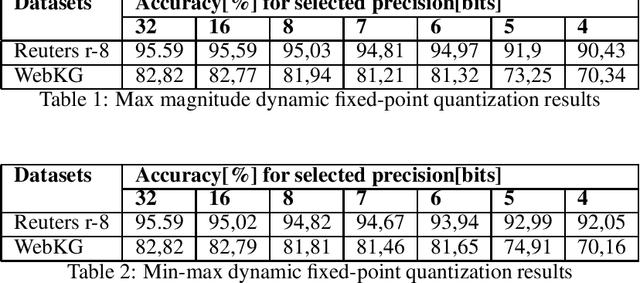
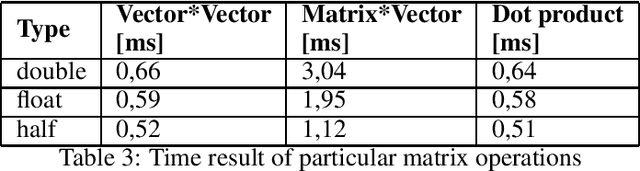
This paper presents the impact of using quantization on the efficiency of multi-class text classification in the training process of a support vector machine (SVM). This work is focused on comparing the efficiency of SVM model trained using reduced precision with its original form. The main advantage of using quantization is decrease in computation time and in memory footprint on the dedicated hardware platform which supports low precision computation like GPU (16-bit) or FPGA (any bit-width). The paper presents the impact of a precision reduction of the SVM training process on text classification accuracy. The implementation of the CPU was performed using the OpenMP library. Additionally, the results of the implementation of the GPU using double, single and half precision are presented.