 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinySubNets: An efficient and low capacity continual learning strategy
Dec 14, 2024



Continual Learning (CL) is a highly relevant setting gaining traction in recent machine learning research. Among CL works, architectural and hybrid strategies are particularly effective due to their potential to adapt the model architecture as new tasks are presented. However, many existing solutions do not efficiently exploit model sparsity, and are prone to capacity saturation due to their inefficient use of available weights, which limits the number of learnable tasks. In this paper, we propose TinySubNets (TSN), a novel architectural CL strategy that addresses the issues through the unique combination of pruning with different sparsity levels, adaptive quantization, and weight sharing. Pruning identifies a subset of weights that preserve model performance, making less relevant weights available for future tasks. Adaptive quantization allows a single weight to be separated into multiple parts which can be assigned to different tasks. Weight sharing between tasks boosts the exploitation of capacity and task similarity, allowing for the identification of a better trade-off between model accuracy and capacity. These features allow TSN to efficiently leverage the available capacity, enhance knowledge transfer, and reduce computational resource consumption. Experimental results involving common benchmark CL datasets and scenarios show that our proposed strategy achieves better results in terms of accuracy than existing state-of-the-art CL strategies. Moreover, our strategy is shown to provide a significantly improved model capacity exploitation. Code released at: https://github.com/lifelonglab/tinysubnets.
Solving Multi-Goal Robotic Tasks with Decision Transformer
Oct 08, 2024



Artificial intelligence plays a crucial role in robotics, with reinforcement learning (RL) emerging as one of the most promising approaches for robot control. However, several key challenges hinder its broader application. First, many RL methods rely on online learning, which requires either real-world hardware or advanced simulation environments--both of which can be costly, time-consuming, and impractical. Offline reinforcement learning offers a solution, enabling models to be trained without ongoing access to physical robots or simulations. A second challenge is learning multi-goal tasks, where robots must achieve multiple objectives simultaneously. This adds complexity to the training process, as the model must generalize across different goals. At the same time, transformer architectures have gained significant popularity across various domains, including reinforcement learning. Yet, no existing methods effectively combine offline training, multi-goal learning, and transformer-based architectures. In this paper, we address these challenges by introducing a novel adaptation of the decision transformer architecture for offline multi-goal reinforcement learning in robotics. Our approach integrates goal-specific information into the decision transformer, allowing it to handle complex tasks in an offline setting. To validate our method, we developed a new offline reinforcement learning dataset using the Panda robotic platform in simulation. Our extensive experiments demonstrate that the decision transformer can outperform state-of-the-art online reinforcement learning methods.
Towards efficient deep autoencoders for multivariate time series anomaly detection
Mar 04, 2024



Multivariate time series anomaly detection is a crucial problem in many industrial and research applications. Timely detection of anomalies allows, for instance, to prevent defects in manufacturing processes and failures in cyberphysical systems. Deep learning methods are preferred among others for their accuracy and robustness for the analysis of complex multivariate data. However, a key aspect is being able to extract predictions in a timely manner, to accommodate real-time requirements in different applications. In the case of deep learning models, model reduction is extremely important to achieve optimal results in real-time systems with limited time and memory constraints. In this paper, we address this issue by proposing a novel compression method for deep autoencoders that involves three key factors. First, pruning reduces the number of weights, while preventing catastrophic drops in accuracy by means of a fast search process that identifies high sparsity levels. Second, linear and non-linear quantization reduces model complexity by reducing the number of bits for every single weight. The combined contribution of these three aspects allow the model size to be reduced, by removing a subset of the weights (pruning), and decreasing their bit-width (quantization). As a result, the compressed model is faster and easier to adopt in highly constrained hardware environments. Experiments performed on popular multivariate anomaly detection benchmarks, show that our method is capable of achieving significant model compression ratio (between 80% and 95%) without a significant reduction in the anomaly detection performance.
Ada-QPacknet -- adaptive pruning with bit width reduction as an efficient continual learning method without forgetting
Aug 14, 2023



Continual Learning (CL) is a process in which there is still huge gap between human and deep learning model efficiency. Recently, many CL algorithms were designed. Most of them have many problems with learning in dynamic and complex environments. In this work new architecture based approach Ada-QPacknet is described. It incorporates the pruning for extracting the sub-network for each task. The crucial aspect in architecture based CL methods is theirs capacity. In presented method the size of the model is reduced by efficient linear and nonlinear quantisation approach. The method reduces the bit-width of the weights format. The presented results shows that hybrid 8 and 4-bit quantisation achieves similar accuracy as floating-point sub-network on a well-know CL scenarios. To our knowledge it is the first CL strategy which incorporates both compression techniques pruning and quantisation for generating task sub-networks. The presented algorithm was tested on well-known episode combinations and compared with most popular algorithms. Results show that proposed approach outperforms most of the CL strategies in task and class incremental scenarios.
Computer-Aided Cytology Diagnosis in Animals: CNN-Based Image Quality Assessment for Accurate Disease Classification
Aug 11, 2023This paper presents a computer-aided cytology diagnosis system designed for animals, focusing on image quality assessment (IQA) using Convolutional Neural Networks (CNNs). The system's building blocks are tailored to seamlessly integrate IQA, ensuring reliable performance in disease classification. We extensively investigate the CNN's ability to handle various image variations and scenarios, analyzing the impact on detecting low-quality input data. Additionally, the network's capacity to differentiate valid cellular samples from those with artifacts is evaluated. Our study employs a ResNet18 network architecture and explores the effects of input sizes and cropping strategies on model performance. The research sheds light on the significance of CNN-based IQA in computer-aided cytology diagnosis for animals, enhancing the accuracy of disease classification.
Using simulation to calibrate real data acquisition in veterinary medicine
Jul 21, 2023



This paper explores the innovative use of simulation environments to enhance data acquisition and diagnostics in veterinary medicine, focusing specifically on gait analysis in dogs. The study harnesses the power of Blender and the Blenderproc library to generate synthetic datasets that reflect diverse anatomical, environmental, and behavioral conditions. The generated data, represented in graph form and standardized for optimal analysis, is utilized to train machine learning algorithms for identifying normal and abnormal gaits. Two distinct datasets with varying degrees of camera angle granularity are created to further investigate the influence of camera perspective on model accuracy. Preliminary results suggest that this simulation-based approach holds promise for advancing veterinary diagnostics by enabling more precise data acquisition and more effective machine learning models. By integrating synthetic and real-world patient data, the study lays a robust foundation for improving overall effectiveness and efficiency in veterinary medicine.
Using super-resolution for enhancing visual perception and segmentation performance in veterinary cytology
Jun 20, 2023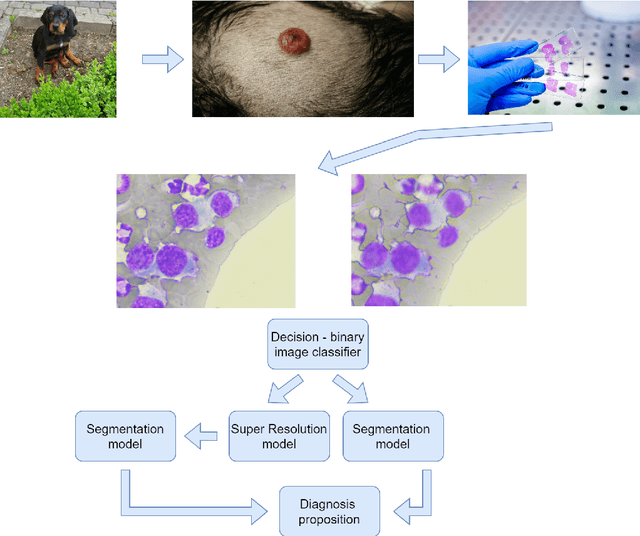
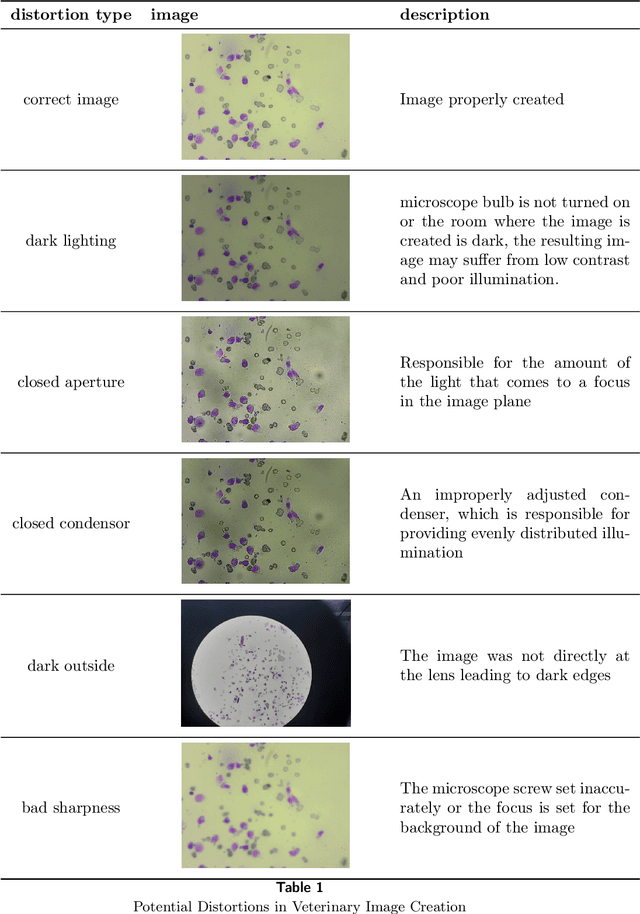
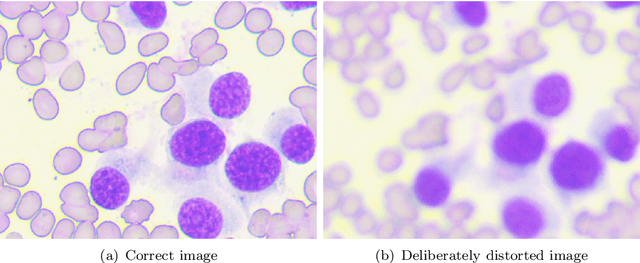
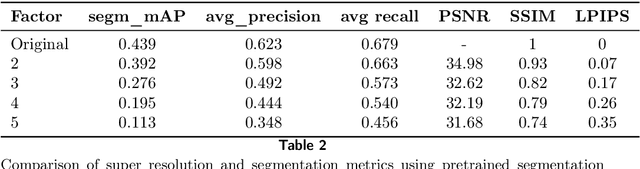
The primary objective of this research was to enhance the quality of semantic segmentation in cytology images by incorporating super-resolution (SR) architectures. An additional contribution was the development of a novel dataset aimed at improving imaging quality in the presence of inaccurate focus. Our experimental results demonstrate that the integration of SR techniques into the segmentation pipeline can lead to a significant improvement of up to 25% in the mean average precision (mAP) segmentation metric. These findings suggest that leveraging SR architectures holds great promise for advancing the state of the art in cytology image analysis.
Estimation of River Water Surface Elevation Using UAV Photogrammetry and Machine Learning
Jun 05, 2023



Unmanned aerial vehicle (UAV) photogrammetry allows for the creation of orthophotos and digital surface models (DSMs) of a terrain. However, DSMs of water bodies mapped with this technique reveal water surface distortions, preventing the use of photogrammetric data for accurate determination of water surface elevation (WSE). Firstly, we propose a new solution in which a convolutional neural network (CNN) is used as a WSE estimator from photogrammetric DSMs and orthophotos. Second, we improved the previously known "water-edge" method by filtering the outliers using a forward-backwards exponential weighted moving average. Further improvement in these two methods was achieved by performing a linear regression of the WSE values against chainage. The solutions estimate the uncertainty of the predictions. This is the first approach in which DL was used for this task. A brand new machine learning data set has been created. It was collected on a small lowland river in winter and summer conditions. It consists of 322 samples, each corresponding to a 10 by 10 meter area of the river channel and adjacent land. Each data set sample contains orthophoto and DSM arrays as input, along with a single ground-truth WSE value as output. The data set was supplemented with data collected by other researchers that compared the state-of-the-art methods for determining WSE using an UAV. The results of the DL solution were verified using k-fold cross-validation method. This provided an in-depth examination of the model's ability to perform on previously unseen data. The WSE RMSEs differ for each k-fold cross-validation subset and range from 1.7 cm up to 17.2 cm. The RMSE results of the improved "water-edge" method are at least six times lower than the RMSE results achieved by the conventional "water-edge" method. The results obtained by new methods are predominantly outperforming existing ones.
Segmentation of the veterinary cytological images for fast neoplastic tumors diagnosis
May 07, 2023



This paper shows the machine learning system which performs instance segmentation of cytological images in veterinary medicine. Eleven cell types were used directly and indirectly in the experiments, including damaged and unrecognized categories. The deep learning models employed in the system achieve a high score of average precision and recall metrics, i.e. 0.94 and 0.8 respectively, for the selected three types of tumors. This variety of label types allowed us to draw a meaningful conclusion that there are relatively few mistakes for tumor cell types. Additionally, the model learned tumor cell features well enough to avoid misclassification mistakes of one tumor type into another. The experiments also revealed that the quality of the results improves with the dataset size (excluding the damaged cells). It is worth noting that all the experiments were done using a custom dedicated dataset provided by the cooperating vet doctors.
Chosen methods of improving object recognition of small objects with weak recognizable features
Aug 29, 2022



Many object detection models struggle with several problematic aspects of small object detection including the low number of samples, lack of diversity and low features representation. Taking into account that GANs belong to generative models class, their initial objective is to learn to mimic any data distribution. Using the proper GAN model would enable augmenting low precision data increasing their amount and diversity. This solution could potentially result in improved object detection results. Additionally, incorporating GAN-based architecture inside deep learning model can increase accuracy of small objects recognition. In this work the GAN-based method with augmentation is presented to improve small object detection on VOC Pascal dataset. The method is compared with different popular augmentation strategies like object rotations, shifts etc. The experiments are based on FasterRCNN model.