 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem Design for an Integrated Lifelong Reinforcement Learning Agent for Real-Time Strategy Games
Dec 08, 2022

As Artificial and Robotic Systems are increasingly deployed and relied upon for real-world applications, it is important that they exhibit the ability to continually learn and adapt in dynamically-changing environments, becoming Lifelong Learning Machines. Continual/lifelong learning (LL) involves minimizing catastrophic forgetting of old tasks while maximizing a model's capability to learn new tasks. This paper addresses the challenging lifelong reinforcement learning (L2RL) setting. Pushing the state-of-the-art forward in L2RL and making L2RL useful for practical applications requires more than developing individual L2RL algorithms; it requires making progress at the systems-level, especially research into the non-trivial problem of how to integrate multiple L2RL algorithms into a common framework. In this paper, we introduce the Lifelong Reinforcement Learning Components Framework (L2RLCF), which standardizes L2RL systems and assimilates different continual learning components (each addressing different aspects of the lifelong learning problem) into a unified system. As an instantiation of L2RLCF, we develop a standard API allowing easy integration of novel lifelong learning components. We describe a case study that demonstrates how multiple independently-developed LL components can be integrated into a single realized system. We also introduce an evaluation environment in order to measure the effect of combining various system components. Our evaluation environment employs different LL scenarios (sequences of tasks) consisting of Starcraft-2 minigames and allows for the fair, comprehensive, and quantitative comparison of different combinations of components within a challenging common evaluation environment.
Lifelong Wandering: A realistic few-shot online continual learning setting
Jun 16, 2022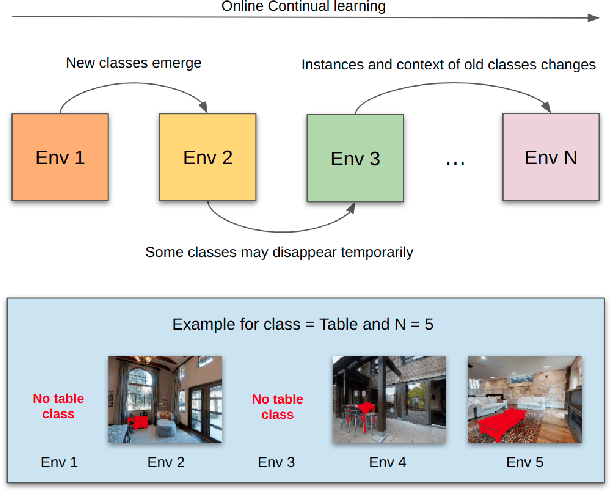
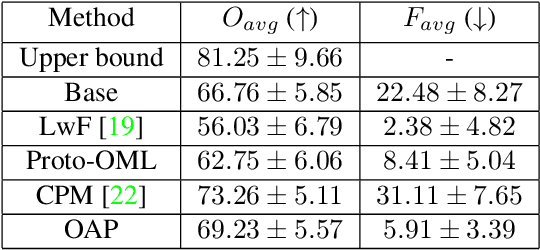
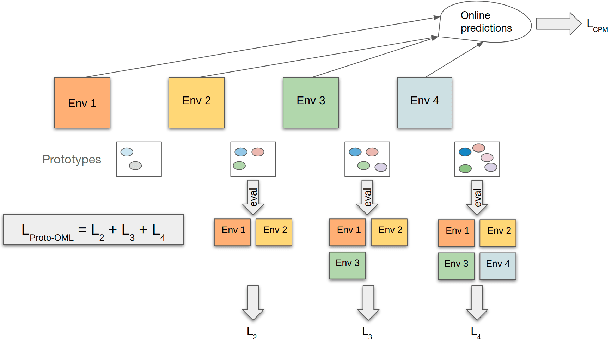
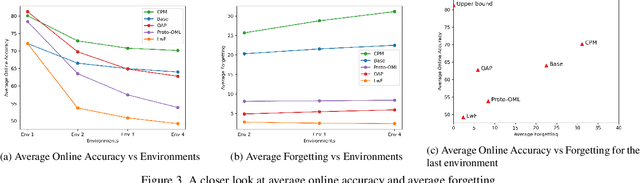
Online few-shot learning describes a setting where models are trained and evaluated on a stream of data while learning emerging classes. While prior work in this setting has achieved very promising performance on instance classification when learning from data-streams composed of a single indoor environment, we propose to extend this setting to consider object classification on a series of several indoor environments, which is likely to occur in applications such as robotics. Importantly, our setting, which we refer to as online few-shot continual learning, injects the well-studied issue of catastrophic forgetting into the few-shot online learning paradigm. In this work, we benchmark several existing methods and adapted baselines within our setting, and show there exists a trade-off between catastrophic forgetting and online performance. Our findings motivate the need for future work in this setting, which can achieve better online performance without catastrophic forgetting.
A Closer Look at Knowledge Distillation with Features, Logits, and Gradients
Mar 18, 2022
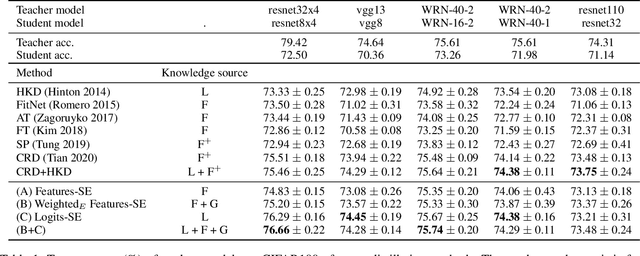
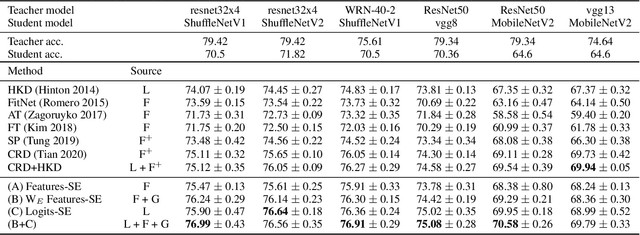
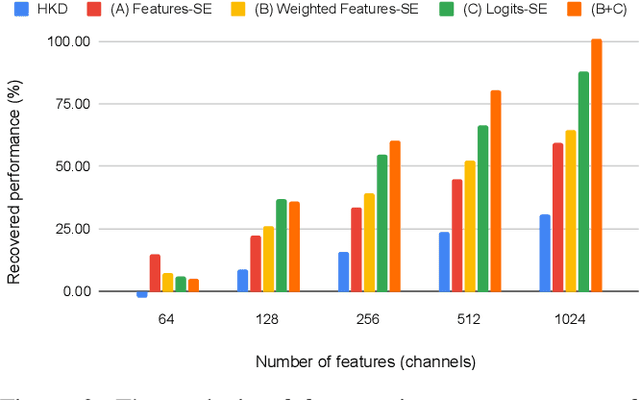
Knowledge distillation (KD) is a substantial strategy for transferring learned knowledge from one neural network model to another. A vast number of methods have been developed for this strategy. While most method designs a more efficient way to facilitate knowledge transfer, less attention has been put on comparing the effect of knowledge sources such as features, logits, and gradients. This work provides a new perspective to motivate a set of knowledge distillation strategies by approximating the classical KL-divergence criteria with different knowledge sources, making a systematic comparison possible in model compression and incremental learning. Our analysis indicates that logits are generally a more efficient knowledge source and suggests that having sufficient feature dimensions is crucial for the model design, providing a practical guideline for effective KD-based transfer learning.
Always Be Dreaming: A New Approach for Data-Free Class-Incremental Learning
Jun 17, 2021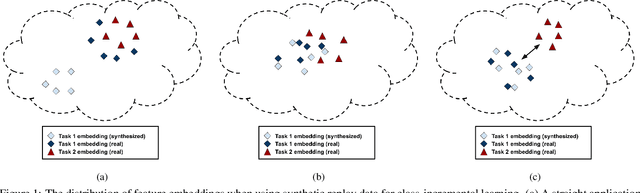
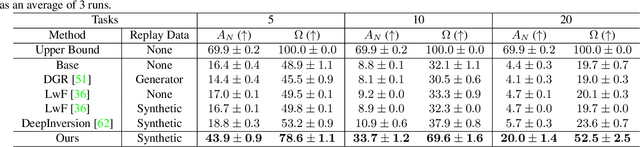
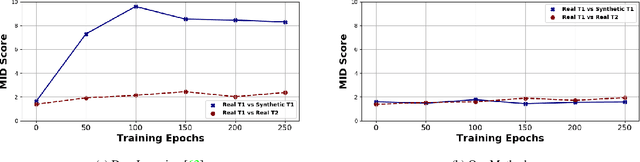

Modern computer vision applications suffer from catastrophic forgetting when incrementally learning new concepts over time. The most successful approaches to alleviate this forgetting require extensive replay of previously seen data, which is problematic when memory constraints or data legality concerns exist. In this work, we consider the high-impact problem of Data-Free Class-Incremental Learning (DFCIL), where an incremental learning agent must learn new concepts over time without storing generators or training data from past tasks. One approach for DFCIL is to replay synthetic images produced by inverting a frozen copy of the learner's classification model, but we show this approach fails for common class-incremental benchmarks when using standard distillation strategies. We diagnose the cause of this failure and propose a novel incremental distillation strategy for DFCIL, contributing a modified cross-entropy training and importance-weighted feature distillation, and show that our method results in up to a 25.1% increase in final task accuracy (absolute difference) compared to SOTA DFCIL methods for common class-incremental benchmarks. Our method even outperforms several standard replay based methods which store a coreset of images.
On the Adversarial Robustness of Quantized Neural Networks
May 01, 2021
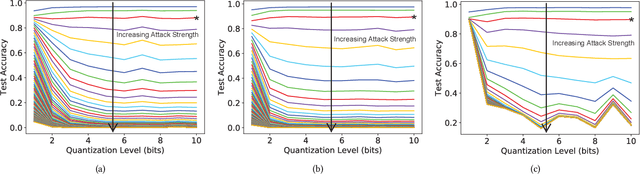
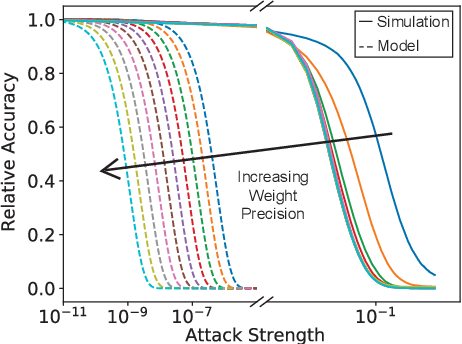
Reducing the size of neural network models is a critical step in moving AI from a cloud-centric to an edge-centric (i.e. on-device) compute paradigm. This shift from cloud to edge is motivated by a number of factors including reduced latency, improved security, and higher flexibility of AI algorithms across several application domains (e.g. transportation, healthcare, defense, etc.). However, it is currently unclear how model compression techniques may affect the robustness of AI algorithms against adversarial attacks. This paper explores the effect of quantization, one of the most common compression techniques, on the adversarial robustness of neural networks. Specifically, we investigate and model the accuracy of quantized neural networks on adversarially-perturbed images. Results indicate that for simple gradient-based attacks, quantization can either improve or degrade adversarial robustness depending on the attack strength.
Memory-Efficient Semi-Supervised Continual Learning: The World is its Own Replay Buffer
Jan 23, 2021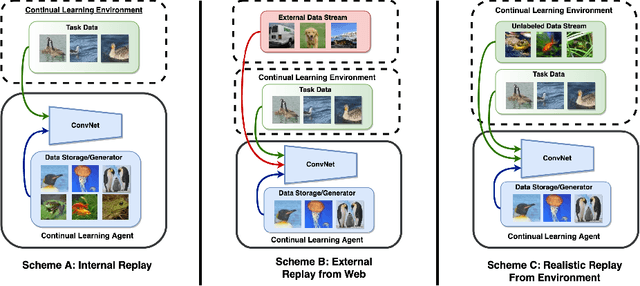
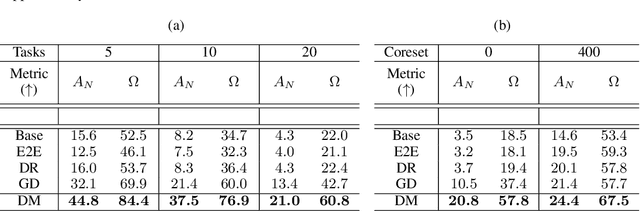
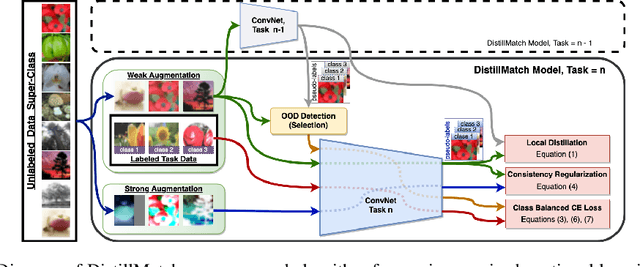
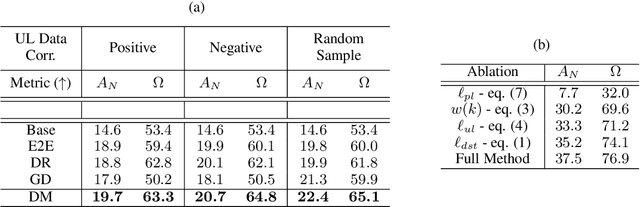
Rehearsal is a critical component for class-incremental continual learning, yet it requires a substantial memory budget. Our work investigates whether we can significantly reduce this memory budget by leveraging unlabeled data from an agent's environment in a realistic and challenging continual learning paradigm. Specifically, we explore and formalize a novel semi-supervised continual learning (SSCL) setting, where labeled data is scarce yet non-i.i.d. unlabeled data from the agent's environment is plentiful. Importantly, data distributions in the SSCL setting are realistic and therefore reflect object class correlations between, and among, the labeled and unlabeled data distributions. We show that a strategy built on pseudo-labeling, consistency regularization, Out-of-Distribution (OoD) detection, and knowledge distillation reduces forgetting in this setting. Our approach, DistillMatch, increases performance over the state-of-the-art by no less than 8.7% average task accuracy and up to a 54.5% increase in average task accuracy in SSCL CIFAR-100 experiments. Moreover, we demonstrate that DistillMatch can save up to 0.23 stored images per processed unlabeled image compared to the next best method which only saves 0.08. Our results suggest that focusing on realistic correlated distributions is a significantly new perspective, which accentuates the importance of leveraging the world's structure as a continual learning strategy.
Unsupervised Continual Learning and Self-Taught Associative Memory Hierarchies
Apr 03, 2019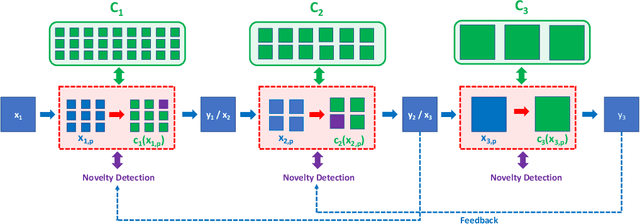

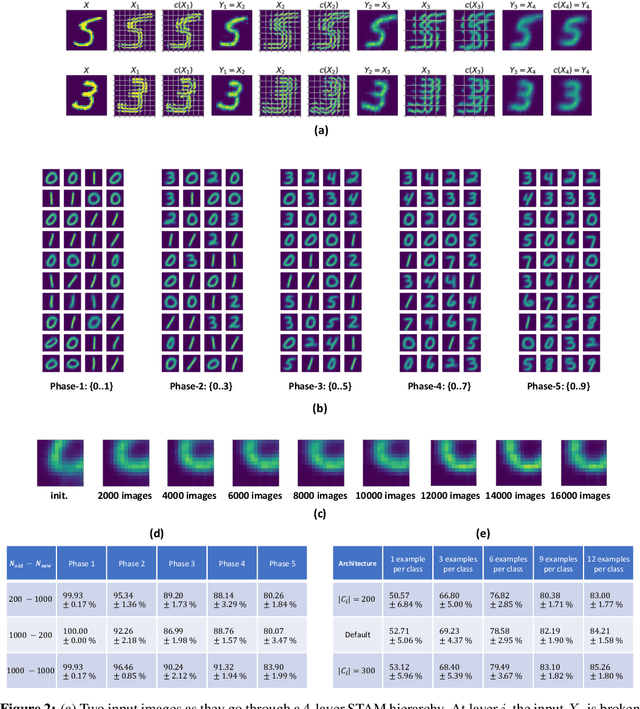
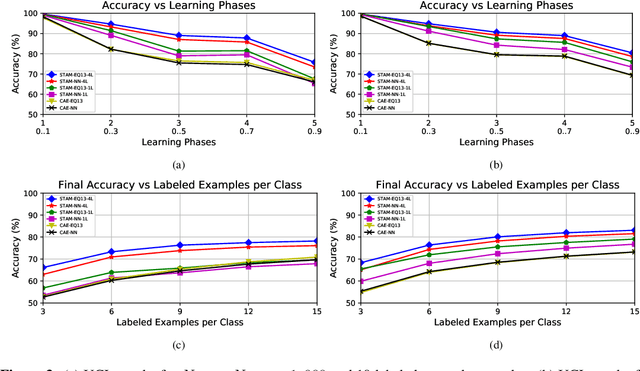
We first pose the Unsupervised Continual Learning (UCL) problem: learning salient representations from a non-stationary stream of unlabeled data in which the number of object classes varies with time. Given limited labeled data just before inference, those representations can also be associated with specific object types to perform classification. To solve the UCL problem, we propose an architecture that involves a single module, called Self-Taught Associative Memory (STAM), which loosely models the function of a cortical column in the mammalian brain. Hierarchies of STAM modules learn based on a combination of Hebbian learning, online clustering, detection of novel patterns, forgetting outliers, and top-down predictions. We illustrate the operation of STAMs in the context of learning handwritten digits in a continual manner with only 3-12 labeled examples per class. STAMs suggest a promising direction to solve the UCL problem without catastrophic forgetting.