 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at Knowledge Distillation with Features, Logits, and Gradients
Paper and Code

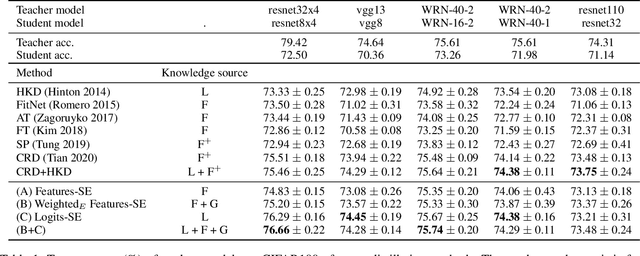
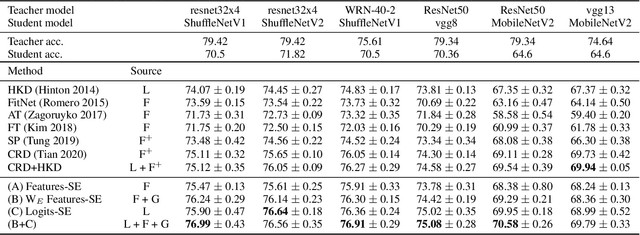
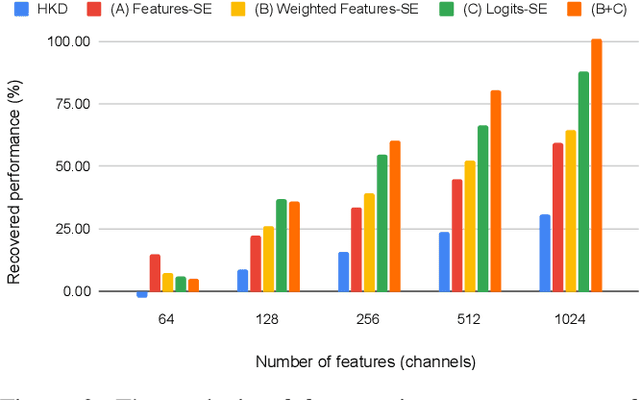
Knowledge distillation (KD) is a substantial strategy for transferring learned knowledge from one neural network model to another. A vast number of methods have been developed for this strategy. While most method designs a more efficient way to facilitate knowledge transfer, less attention has been put on comparing the effect of knowledge sources such as features, logits, and gradients. This work provides a new perspective to motivate a set of knowledge distillation strategies by approximating the classical KL-divergence criteria with different knowledge sources, making a systematic comparison possible in model compression and incremental learning. Our analysis indicates that logits are generally a more efficient knowledge source and suggests that having sufficient feature dimensions is crucial for the model design, providing a practical guideline for effective KD-based transfer learning.