 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMossNet: Mixture of State-Space Experts is a Multi-Head Attention
Oct 30, 2025Large language models (LLMs) have significantly advanced generative applications in natural language processing (NLP). Recent trends in model architectures revolve around efficient variants of transformers or state-space/gated-recurrent models (SSMs, GRMs). However, prevailing SSM/GRM-based methods often emulate only a single attention head, potentially limiting their expressiveness. In this work, we propose MossNet, a novel mixture-of-state-space-experts architecture that emulates a linear multi-head attention (MHA). MossNet leverages a mixture-of-experts (MoE) implementation not only in channel-mixing multi-layered perceptron (MLP) blocks but also in the time-mixing SSM kernels to realize multiple "attention heads." Extensive experiments on language modeling and downstream evaluations show that MossNet outperforms both transformer- and SSM-based architectures of similar model size and data budgets. Larger variants of MossNet, trained on trillions of tokens, further confirm its scalability and superior performance. In addition, real-device profiling on a Samsung Galaxy S24 Ultra and an Nvidia A100 GPU demonstrate favorable runtime speed and resource usage compared to similarly sized baselines. Our results suggest that MossNet is a compelling new direction for efficient, high-performing recurrent LLM architectures.
ToMoE: Converting Dense Large Language Models to Mixture-of-Experts through Dynamic Structural Pruning
Jan 25, 2025Large Language Models (LLMs) have demonstrated remarkable abilities in tackling a wide range of complex tasks. However, their huge computational and memory costs raise significant challenges in deploying these models on resource-constrained devices or efficiently serving them. Prior approaches have attempted to alleviate these problems by permanently removing less important model structures, yet these methods often result in substantial performance degradation due to the permanent deletion of model parameters. In this work, we tried to mitigate this issue by reducing the number of active parameters without permanently removing them. Specifically, we introduce a differentiable dynamic pruning method that pushes dense models to maintain a fixed number of active parameters by converting their MLP layers into a Mixture of Experts (MoE) architecture. Our method, even without fine-tuning, consistently outperforms previous structural pruning techniques across diverse model families, including Phi-2, LLaMA-2, LLaMA-3, and Qwen-2.5.
FlexiGPT: Pruning and Extending Large Language Models with Low-Rank Weight Sharing
Jan 24, 2025



The rapid proliferation of large language models (LLMs) in natural language processing (NLP) has created a critical need for techniques that enable efficient deployment on memory-constrained devices without compromising performance. We present a method to prune LLMs that selectively prunes model blocks based on an importance score and replaces them with a low-parameter replacement strategy. Specifically, we propose a principled metric to replace each pruned block using a weight-sharing mechanism that leverages unpruned counterparts from the model and block-specific low-rank adapters. Furthermore, we facilitate the learning of these replacement blocks with output feature normalization and an adapter initialization scheme built on low-rank SVD reconstructions. Empirical evaluations demonstrate substantial performance gains over existing methods, achieving state-of-the-art performance on 5/6 benchmarks for a compression rate of 30% and 6/6 benchmarks for a compression rate of 40%. We also demonstrate that our approach can extend smaller models, boosting performance on 6/6 benchmarks using only ~0.3% tokens of extended training with minimal additional parameter costs.
DISP-LLM: Dimension-Independent Structural Pruning for Large Language Models
Oct 15, 2024



Large Language Models (LLMs) have achieved remarkable success in various natural language processing tasks, including language modeling, understanding, and generation. However, the increased memory and computational costs associated with these models pose significant challenges for deployment on resource-limited devices. Structural pruning has emerged as a promising solution to reduce the costs of LLMs without requiring post-processing steps. Prior structural pruning methods either follow the dependence of structures at the cost of limiting flexibility, or introduce non-trivial additional parameters by incorporating different projection matrices. In this work, we propose a novel approach that relaxes the constraint imposed by regular structural pruning methods and eliminates the structural dependence along the embedding dimension. Our dimension-independent structural pruning method offers several benefits. Firstly, our method enables different blocks to utilize different subsets of the feature maps. Secondly, by removing structural dependence, we facilitate each block to possess varying widths along its input and output dimensions, thereby significantly enhancing the flexibility of structural pruning. We evaluate our method on various LLMs, including OPT, LLaMA, LLaMA-2, Phi-1.5, and Phi-2. Experimental results demonstrate that our approach outperforms other state-of-the-art methods, showing for the first time that structural pruning can achieve an accuracy similar to semi-structural pruning.
Retraining-Free Merging of Sparse Mixture-of-Experts via Hierarchical Clustering
Oct 11, 2024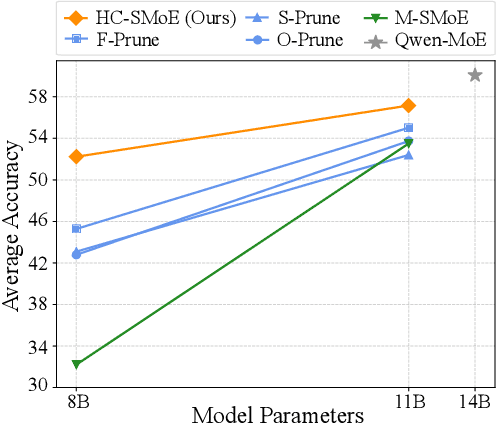

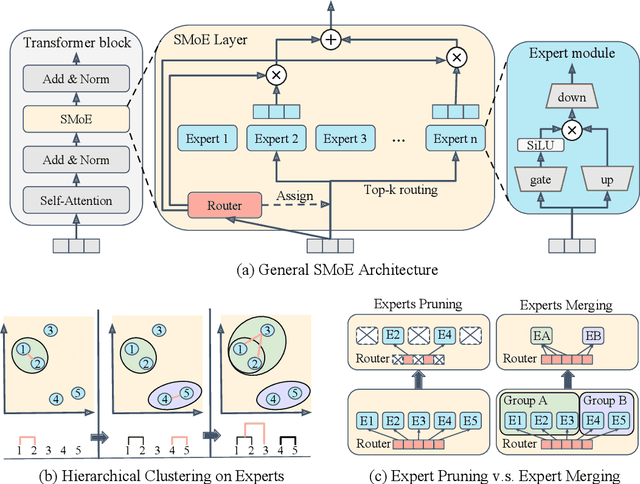
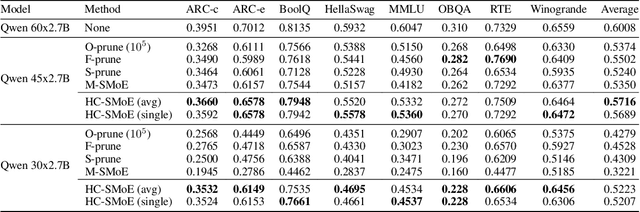
Sparse Mixture-of-Experts (SMoE) models represent a significant breakthrough in large language model development. These models enable performance improvements without a proportional increase in inference costs. By selectively activating a small set of parameters during task execution, SMoEs enhance model capacity. However, their deployment remains challenging due to the substantial memory footprint required to accommodate the growing number of experts. This constraint renders them less feasible in environments with limited hardware resources. To address this challenge, we propose Hierarchical Clustering for Sparsely activated Mixture of Experts (HC-SMoE), a task-agnostic expert merging framework that reduces SMoE model parameters without retraining. Unlike previous methods, HC-SMoE employs hierarchical clustering based on expert outputs. This approach ensures that the merging process remains unaffected by routing decisions. The output-based clustering strategy captures functional similarities between experts, offering an adaptable solution for models with numerous experts. We validate our approach through extensive experiments on eight zero-shot language tasks and demonstrate its effectiveness in large-scale SMoE models such as Qwen and Mixtral. Our comprehensive results demonstrate that HC-SMoE consistently achieves strong performance, which highlights its potential for real-world deployment.
MoDeGPT: Modular Decomposition for Large Language Model Compression
Aug 20, 2024



Large Language Models (LLMs) have reshaped the landscape of artificial intelligence by demonstrating exceptional performance across various tasks. However, substantial computational requirements make their deployment challenging on devices with limited resources. Recently, compression methods using low-rank matrix techniques have shown promise, yet these often lead to degraded accuracy or introduce significant overhead in parameters and inference latency. This paper introduces \textbf{Mo}dular \textbf{De}composition (MoDeGPT), a novel structured compression framework that does not need recovery fine-tuning while resolving the above drawbacks. MoDeGPT partitions the Transformer block into modules comprised of matrix pairs and reduces the hidden dimensions via reconstructing the module-level outputs. MoDeGPT is developed based on a theoretical framework that utilizes three well-established matrix decomposition algorithms -- Nystr\"om approximation, CR decomposition, and SVD -- and applies them to our redefined transformer modules. Our comprehensive experiments show MoDeGPT, without backward propagation, matches or surpasses previous structured compression methods that rely on gradient information, and saves 98% of compute costs on compressing a 13B model. On \textsc{Llama}-2/3 and OPT models, MoDeGPT maintains 90-95% zero-shot performance with 25-30% compression rates. Moreover, the compression can be done on a single GPU within a few hours and increases the inference throughput by up to 46%.
DynaMo: Accelerating Language Model Inference with Dynamic Multi-Token Sampling
May 01, 2024



Traditional language models operate autoregressively, i.e., they predict one token at a time. Rapid explosion in model sizes has resulted in high inference times. In this work, we propose DynaMo, a suite of multi-token prediction language models that reduce net inference times. Our models $\textit{dynamically}$ predict multiple tokens based on their confidence in the predicted joint probability distribution. We propose a lightweight technique to train these models, leveraging the weights of traditional autoregressive counterparts. Moreover, we propose novel ways to enhance the estimated joint probability to improve text generation quality, namely co-occurrence weighted masking and adaptive thresholding. We also propose systematic qualitative and quantitative methods to rigorously test the quality of generated text for non-autoregressive generation. One of the models in our suite, DynaMo-7.3B-T3, achieves same-quality generated text as the baseline (Pythia-6.9B) while achieving 2.57$\times$ speed-up with only 5.87% and 2.67% parameter and training time overheads, respectively.
Token Fusion: Bridging the Gap between Token Pruning and Token Merging
Dec 02, 2023



Vision Transformers (ViTs) have emerged as powerful backbones in computer vision, outperforming many traditional CNNs. However, their computational overhead, largely attributed to the self-attention mechanism, makes deployment on resource-constrained edge devices challenging. Multiple solutions rely on token pruning or token merging. In this paper, we introduce "Token Fusion" (ToFu), a method that amalgamates the benefits of both token pruning and token merging. Token pruning proves advantageous when the model exhibits sensitivity to input interpolations, while token merging is effective when the model manifests close to linear responses to inputs. We combine this to propose a new scheme called Token Fusion. Moreover, we tackle the limitations of average merging, which doesn't preserve the intrinsic feature norm, resulting in distributional shifts. To mitigate this, we introduce MLERP merging, a variant of the SLERP technique, tailored to merge multiple tokens while maintaining the norm distribution. ToFu is versatile, applicable to ViTs with or without additional training. Our empirical evaluations indicate that ToFu establishes new benchmarks in both classification and image generation tasks concerning computational efficiency and model accuracy.
Continual Diffusion with STAMINA: STack-And-Mask INcremental Adapters
Nov 30, 2023



Recent work has demonstrated a remarkable ability to customize text-to-image diffusion models to multiple, fine-grained concepts in a sequential (i.e., continual) manner while only providing a few example images for each concept. This setting is known as continual diffusion. Here, we ask the question: Can we scale these methods to longer concept sequences without forgetting? Although prior work mitigates the forgetting of previously learned concepts, we show that its capacity to learn new tasks reaches saturation over longer sequences. We address this challenge by introducing a novel method, STack-And-Mask INcremental Adapters (STAMINA), which is composed of low-ranked attention-masked adapters and customized MLP tokens. STAMINA is designed to enhance the robust fine-tuning properties of LoRA for sequential concept learning via learnable hard-attention masks parameterized with low rank MLPs, enabling precise, scalable learning via sparse adaptation. Notably, all introduced trainable parameters can be folded back into the model after training, inducing no additional inference parameter costs. We show that STAMINA outperforms the prior SOTA for the setting of text-to-image continual customization on a 50-concept benchmark composed of landmarks and human faces, with no stored replay data. Additionally, we extended our method to the setting of continual learning for image classification, demonstrating that our gains also translate to state-of-the-art performance in this standard benchmark.
Training Energy-Based Normalizing Flow with Score-Matching Objectives
May 24, 2023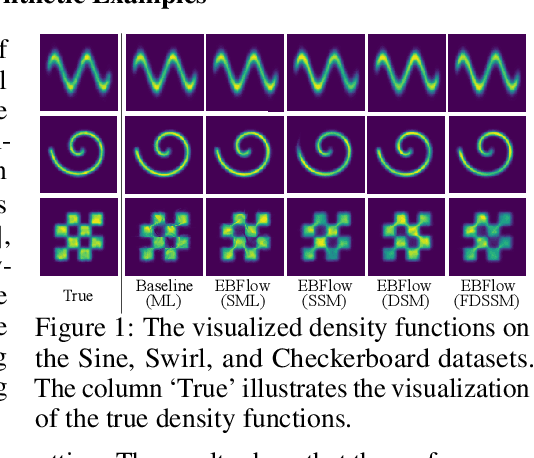

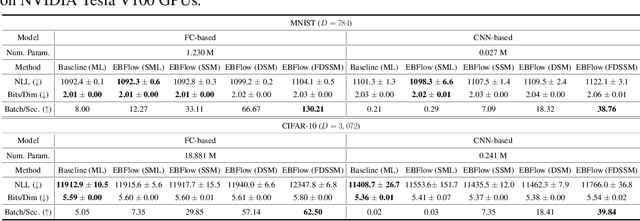
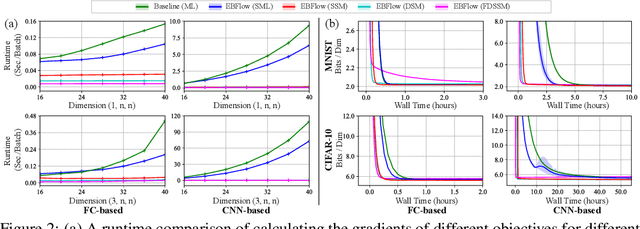
In this paper, we establish a connection between the parameterization of flow-based and energy-based generative models, and present a new flow-based modeling approach called energy-based normalizing flow (EBFlow). We demonstrate that by optimizing EBFlow with score-matching objectives, the computation of Jacobian determinants for linear transformations can be entirely bypassed. This feature enables the use of arbitrary linear layers in the construction of flow-based models without increasing the computational time complexity of each training iteration from $\mathcal{O}(D^2L)$ to $\mathcal{O}(D^3L)$ for an $L$-layered model that accepts $D$-dimensional inputs. This makes the training of EBFlow more efficient than the commonly-adopted maximum likelihood training method. In addition to the reduction in runtime, we enhance the training stability and empirical performance of EBFlow through a number of techniques developed based on our analysis on the score-matching methods. The experimental results demonstrate that our approach achieves a significant speedup compared to maximum likelihood estimation, while outperforming prior efficient training techniques with a noticeable margin in terms of negative log-likelihood (NLL).