 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMossNet: Mixture of State-Space Experts is a Multi-Head Attention
Oct 30, 2025Large language models (LLMs) have significantly advanced generative applications in natural language processing (NLP). Recent trends in model architectures revolve around efficient variants of transformers or state-space/gated-recurrent models (SSMs, GRMs). However, prevailing SSM/GRM-based methods often emulate only a single attention head, potentially limiting their expressiveness. In this work, we propose MossNet, a novel mixture-of-state-space-experts architecture that emulates a linear multi-head attention (MHA). MossNet leverages a mixture-of-experts (MoE) implementation not only in channel-mixing multi-layered perceptron (MLP) blocks but also in the time-mixing SSM kernels to realize multiple "attention heads." Extensive experiments on language modeling and downstream evaluations show that MossNet outperforms both transformer- and SSM-based architectures of similar model size and data budgets. Larger variants of MossNet, trained on trillions of tokens, further confirm its scalability and superior performance. In addition, real-device profiling on a Samsung Galaxy S24 Ultra and an Nvidia A100 GPU demonstrate favorable runtime speed and resource usage compared to similarly sized baselines. Our results suggest that MossNet is a compelling new direction for efficient, high-performing recurrent LLM architectures.
GraphMERT: Efficient and Scalable Distillation of Reliable Knowledge Graphs from Unstructured Data
Oct 10, 2025

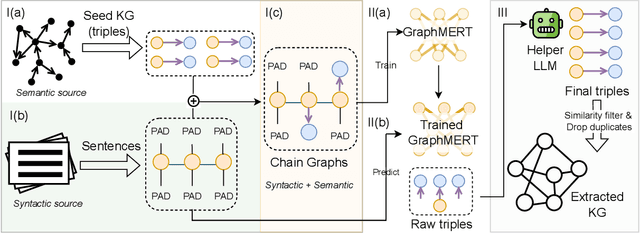

Researchers have pursued neurosymbolic artificial intelligence (AI) applications for nearly three decades because symbolic components provide abstraction while neural components provide generalization. Thus, a marriage of the two components can lead to rapid advancements in AI. Yet, the field has not realized this promise since most neurosymbolic AI frameworks fail to scale. In addition, the implicit representations and approximate reasoning of neural approaches limit interpretability and trust. Knowledge graphs (KGs), a gold-standard representation of explicit semantic knowledge, can address the symbolic side. However, automatically deriving reliable KGs from text corpora has remained an open problem. We address these challenges by introducing GraphMERT, a tiny graphical encoder-only model that distills high-quality KGs from unstructured text corpora and its own internal representations. GraphMERT and its equivalent KG form a modular neurosymbolic stack: neural learning of abstractions; symbolic KGs for verifiable reasoning. GraphMERT + KG is the first efficient and scalable neurosymbolic model to achieve state-of-the-art benchmark accuracy along with superior symbolic representations relative to baselines. Concretely, we target reliable domain-specific KGs that are both (1) factual (with provenance) and (2) valid (ontology-consistent relations with domain-appropriate semantics). When a large language model (LLM), e.g., Qwen3-32B, generates domain-specific KGs, it falls short on reliability due to prompt sensitivity, shallow domain expertise, and hallucinated relations. On text obtained from PubMed papers on diabetes, our 80M-parameter GraphMERT yields a KG with a 69.8% FActScore; a 32B-parameter baseline LLM yields a KG that achieves only 40.2% FActScore. The GraphMERT KG also attains a higher ValidityScore of 68.8%, versus 43.0% for the LLM baseline.
FlexiGPT: Pruning and Extending Large Language Models with Low-Rank Weight Sharing
Jan 24, 2025



The rapid proliferation of large language models (LLMs) in natural language processing (NLP) has created a critical need for techniques that enable efficient deployment on memory-constrained devices without compromising performance. We present a method to prune LLMs that selectively prunes model blocks based on an importance score and replaces them with a low-parameter replacement strategy. Specifically, we propose a principled metric to replace each pruned block using a weight-sharing mechanism that leverages unpruned counterparts from the model and block-specific low-rank adapters. Furthermore, we facilitate the learning of these replacement blocks with output feature normalization and an adapter initialization scheme built on low-rank SVD reconstructions. Empirical evaluations demonstrate substantial performance gains over existing methods, achieving state-of-the-art performance on 5/6 benchmarks for a compression rate of 30% and 6/6 benchmarks for a compression rate of 40%. We also demonstrate that our approach can extend smaller models, boosting performance on 6/6 benchmarks using only ~0.3% tokens of extended training with minimal additional parameter costs.
MoDeGPT: Modular Decomposition for Large Language Model Compression
Aug 20, 2024



Large Language Models (LLMs) have reshaped the landscape of artificial intelligence by demonstrating exceptional performance across various tasks. However, substantial computational requirements make their deployment challenging on devices with limited resources. Recently, compression methods using low-rank matrix techniques have shown promise, yet these often lead to degraded accuracy or introduce significant overhead in parameters and inference latency. This paper introduces \textbf{Mo}dular \textbf{De}composition (MoDeGPT), a novel structured compression framework that does not need recovery fine-tuning while resolving the above drawbacks. MoDeGPT partitions the Transformer block into modules comprised of matrix pairs and reduces the hidden dimensions via reconstructing the module-level outputs. MoDeGPT is developed based on a theoretical framework that utilizes three well-established matrix decomposition algorithms -- Nystr\"om approximation, CR decomposition, and SVD -- and applies them to our redefined transformer modules. Our comprehensive experiments show MoDeGPT, without backward propagation, matches or surpasses previous structured compression methods that rely on gradient information, and saves 98% of compute costs on compressing a 13B model. On \textsc{Llama}-2/3 and OPT models, MoDeGPT maintains 90-95% zero-shot performance with 25-30% compression rates. Moreover, the compression can be done on a single GPU within a few hours and increases the inference throughput by up to 46%.
DynaMo: Accelerating Language Model Inference with Dynamic Multi-Token Sampling
May 01, 2024



Traditional language models operate autoregressively, i.e., they predict one token at a time. Rapid explosion in model sizes has resulted in high inference times. In this work, we propose DynaMo, a suite of multi-token prediction language models that reduce net inference times. Our models $\textit{dynamically}$ predict multiple tokens based on their confidence in the predicted joint probability distribution. We propose a lightweight technique to train these models, leveraging the weights of traditional autoregressive counterparts. Moreover, we propose novel ways to enhance the estimated joint probability to improve text generation quality, namely co-occurrence weighted masking and adaptive thresholding. We also propose systematic qualitative and quantitative methods to rigorously test the quality of generated text for non-autoregressive generation. One of the models in our suite, DynaMo-7.3B-T3, achieves same-quality generated text as the baseline (Pythia-6.9B) while achieving 2.57$\times$ speed-up with only 5.87% and 2.67% parameter and training time overheads, respectively.
BREATHE: Second-Order Gradients and Heteroscedastic Emulation based Design Space Exploration
Aug 16, 2023Researchers constantly strive to explore larger and more complex search spaces in various scientific studies and physical experiments. However, such investigations often involve sophisticated simulators or time-consuming experiments that make exploring and observing new design samples challenging. Previous works that target such applications are typically sample-inefficient and restricted to vector search spaces. To address these limitations, this work proposes a constrained multi-objective optimization (MOO) framework, called BREATHE, that searches not only traditional vector-based design spaces but also graph-based design spaces to obtain best-performing graphs. It leverages second-order gradients and actively trains a heteroscedastic surrogate model for sample-efficient optimization. In a single-objective vector optimization application, it leads to 64.1% higher performance than the next-best baseline, random forest regression. In graph-based search, BREATHE outperforms the next-best baseline, i.e., a graphical version of Gaussian-process-based Bayesian optimization, with up to 64.9% higher performance. In a MOO task, it achieves up to 21.9$\times$ higher hypervolume than the state-of-the-art method, multi-objective Bayesian optimization (MOBOpt). BREATHE also outperforms the baseline methods on most standard MOO benchmark applications.
TransCODE: Co-design of Transformers and Accelerators for Efficient Training and Inference
Mar 27, 2023



Automated co-design of machine learning models and evaluation hardware is critical for efficiently deploying such models at scale. Despite the state-of-the-art performance of transformer models, they are not yet ready for execution on resource-constrained hardware platforms. High memory requirements and low parallelizability of the transformer architecture exacerbate this problem. Recently-proposed accelerators attempt to optimize the throughput and energy consumption of transformer models. However, such works are either limited to a one-sided search of the model architecture or a restricted set of off-the-shelf devices. Furthermore, previous works only accelerate model inference and not training, which incurs substantially higher memory and compute resources, making the problem even more challenging. To address these limitations, this work proposes a dynamic training framework, called DynaProp, that speeds up the training process and reduces memory consumption. DynaProp is a low-overhead pruning method that prunes activations and gradients at runtime. To effectively execute this method on hardware for a diverse set of transformer architectures, we propose ELECTOR, a framework that simulates transformer inference and training on a design space of accelerators. We use this simulator in conjunction with the proposed co-design technique, called TransCODE, to obtain the best-performing models with high accuracy on the given task and minimize latency, energy consumption, and chip area. The obtained transformer-accelerator pair achieves 0.3% higher accuracy than the state-of-the-art pair while incurring 5.2$\times$ lower latency and 3.0$\times$ lower energy consumption.
EdgeTran: Co-designing Transformers for Efficient Inference on Mobile Edge Platforms
Mar 24, 2023Automated design of efficient transformer models has recently attracted significant attention from industry and academia. However, most works only focus on certain metrics while searching for the best-performing transformer architecture. Furthermore, running traditional, complex, and large transformer models on low-compute edge platforms is a challenging problem. In this work, we propose a framework, called ProTran, to profile the hardware performance measures for a design space of transformer architectures and a diverse set of edge devices. We use this profiler in conjunction with the proposed co-design technique to obtain the best-performing models that have high accuracy on the given task and minimize latency, energy consumption, and peak power draw to enable edge deployment. We refer to our framework for co-optimizing accuracy and hardware performance measures as EdgeTran. It searches for the best transformer model and edge device pair. Finally, we propose GPTran, a multi-stage block-level grow-and-prune post-processing step that further improves accuracy in a hardware-aware manner. The obtained transformer model is 2.8$\times$ smaller and has a 0.8% higher GLUE score than the baseline (BERT-Base). Inference with it on the selected edge device enables 15.0% lower latency, 10.0$\times$ lower energy, and 10.8$\times$ lower peak power draw compared to an off-the-shelf GPU.
AccelTran: A Sparsity-Aware Accelerator for Dynamic Inference with Transformers
Feb 28, 2023Self-attention-based transformer models have achieved tremendous success in the domain of natural language processing. Despite their efficacy, accelerating the transformer is challenging due to its quadratic computational complexity and large activation sizes. Existing transformer accelerators attempt to prune its tokens to reduce memory access, albeit with high compute overheads. Moreover, previous works directly operate on large matrices involved in the attention operation, which limits hardware utilization. In order to address these challenges, this work proposes a novel dynamic inference scheme, DynaTran, which prunes activations at runtime with low overhead, substantially reducing the number of ineffectual operations. This improves the throughput of transformer inference. We further propose tiling the matrices in transformer operations along with diverse dataflows to improve data reuse, thus enabling higher energy efficiency. To effectively implement these methods, we propose AccelTran, a novel accelerator architecture for transformers. Extensive experiments with different models and benchmarks demonstrate that DynaTran achieves higher accuracy than the state-of-the-art top-k hardware-aware pruning strategy while attaining up to 1.2$\times$ higher sparsity. One of our proposed accelerators, AccelTran-Edge, achieves 330K$\times$ higher throughput with 93K$\times$ lower energy requirement when compared to a Raspberry Pi device. On the other hand, AccelTran-Server achieves 5.73$\times$ higher throughput and 3.69$\times$ lower energy consumption compared to the state-of-the-art transformer co-processor, Energon.
CODEBench: A Neural Architecture and Hardware Accelerator Co-Design Framework
Dec 07, 2022Recently, automated co-design of machine learning (ML) models and accelerator architectures has attracted significant attention from both the industry and academia. However, most co-design frameworks either explore a limited search space or employ suboptimal exploration techniques for simultaneous design decision investigations of the ML model and the accelerator. Furthermore, training the ML model and simulating the accelerator performance is computationally expensive. To address these limitations, this work proposes a novel neural architecture and hardware accelerator co-design framework, called CODEBench. It is composed of two new benchmarking sub-frameworks, CNNBench and AccelBench, which explore expanded design spaces of convolutional neural networks (CNNs) and CNN accelerators. CNNBench leverages an advanced search technique, BOSHNAS, to efficiently train a neural heteroscedastic surrogate model to converge to an optimal CNN architecture by employing second-order gradients. AccelBench performs cycle-accurate simulations for a diverse set of accelerator architectures in a vast design space. With the proposed co-design method, called BOSHCODE, our best CNN-accelerator pair achieves 1.4% higher accuracy on the CIFAR-10 dataset compared to the state-of-the-art pair, while enabling 59.1% lower latency and 60.8% lower energy consumption. On the ImageNet dataset, it achieves 3.7% higher Top1 accuracy at 43.8% lower latency and 11.2% lower energy consumption. CODEBench outperforms the state-of-the-art framework, i.e., Auto-NBA, by achieving 1.5% higher accuracy and 34.7x higher throughput, while enabling 11.0x lower energy-delay product (EDP) and 4.0x lower chip area on CIFAR-10.