 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMossNet: Mixture of State-Space Experts is a Multi-Head Attention
Oct 30, 2025Large language models (LLMs) have significantly advanced generative applications in natural language processing (NLP). Recent trends in model architectures revolve around efficient variants of transformers or state-space/gated-recurrent models (SSMs, GRMs). However, prevailing SSM/GRM-based methods often emulate only a single attention head, potentially limiting their expressiveness. In this work, we propose MossNet, a novel mixture-of-state-space-experts architecture that emulates a linear multi-head attention (MHA). MossNet leverages a mixture-of-experts (MoE) implementation not only in channel-mixing multi-layered perceptron (MLP) blocks but also in the time-mixing SSM kernels to realize multiple "attention heads." Extensive experiments on language modeling and downstream evaluations show that MossNet outperforms both transformer- and SSM-based architectures of similar model size and data budgets. Larger variants of MossNet, trained on trillions of tokens, further confirm its scalability and superior performance. In addition, real-device profiling on a Samsung Galaxy S24 Ultra and an Nvidia A100 GPU demonstrate favorable runtime speed and resource usage compared to similarly sized baselines. Our results suggest that MossNet is a compelling new direction for efficient, high-performing recurrent LLM architectures.
FlexiGPT: Pruning and Extending Large Language Models with Low-Rank Weight Sharing
Jan 24, 2025



The rapid proliferation of large language models (LLMs) in natural language processing (NLP) has created a critical need for techniques that enable efficient deployment on memory-constrained devices without compromising performance. We present a method to prune LLMs that selectively prunes model blocks based on an importance score and replaces them with a low-parameter replacement strategy. Specifically, we propose a principled metric to replace each pruned block using a weight-sharing mechanism that leverages unpruned counterparts from the model and block-specific low-rank adapters. Furthermore, we facilitate the learning of these replacement blocks with output feature normalization and an adapter initialization scheme built on low-rank SVD reconstructions. Empirical evaluations demonstrate substantial performance gains over existing methods, achieving state-of-the-art performance on 5/6 benchmarks for a compression rate of 30% and 6/6 benchmarks for a compression rate of 40%. We also demonstrate that our approach can extend smaller models, boosting performance on 6/6 benchmarks using only ~0.3% tokens of extended training with minimal additional parameter costs.
Grounding Descriptions in Images informs Zero-Shot Visual Recognition
Dec 05, 2024



Vision-language models (VLMs) like CLIP have been cherished for their ability to perform zero-shot visual recognition on open-vocabulary concepts. This is achieved by selecting the object category whose textual representation bears the highest similarity with the query image. While successful in some domains, this method struggles with identifying fine-grained entities as well as generalizing to unseen concepts that are not captured by the training distribution. Recent works attempt to mitigate these challenges by integrating category descriptions at test time, albeit yielding modest improvements. We attribute these limited gains to a fundamental misalignment between image and description representations, which is rooted in the pretraining structure of CLIP. In this paper, we propose GRAIN, a new pretraining strategy aimed at aligning representations at both fine and coarse levels simultaneously. Our approach learns to jointly ground textual descriptions in image regions along with aligning overarching captions with global image representations. To drive this pre-training, we leverage frozen Multimodal Large Language Models (MLLMs) to derive large-scale synthetic annotations. We demonstrate the enhanced zero-shot performance of our model compared to current state-of-the art methods across 11 diverse image classification datasets. Additionally, we introduce Products-2023, a newly curated, manually labeled dataset featuring novel concepts, and showcase our model's ability to recognize these concepts by benchmarking on it. Significant improvements achieved by our model on other downstream tasks like retrieval further highlight the superior quality of representations learned by our approach. Code available at https://github.com/shaunak27/grain-clip .
MoDeGPT: Modular Decomposition for Large Language Model Compression
Aug 20, 2024



Large Language Models (LLMs) have reshaped the landscape of artificial intelligence by demonstrating exceptional performance across various tasks. However, substantial computational requirements make their deployment challenging on devices with limited resources. Recently, compression methods using low-rank matrix techniques have shown promise, yet these often lead to degraded accuracy or introduce significant overhead in parameters and inference latency. This paper introduces \textbf{Mo}dular \textbf{De}composition (MoDeGPT), a novel structured compression framework that does not need recovery fine-tuning while resolving the above drawbacks. MoDeGPT partitions the Transformer block into modules comprised of matrix pairs and reduces the hidden dimensions via reconstructing the module-level outputs. MoDeGPT is developed based on a theoretical framework that utilizes three well-established matrix decomposition algorithms -- Nystr\"om approximation, CR decomposition, and SVD -- and applies them to our redefined transformer modules. Our comprehensive experiments show MoDeGPT, without backward propagation, matches or surpasses previous structured compression methods that rely on gradient information, and saves 98% of compute costs on compressing a 13B model. On \textsc{Llama}-2/3 and OPT models, MoDeGPT maintains 90-95% zero-shot performance with 25-30% compression rates. Moreover, the compression can be done on a single GPU within a few hours and increases the inference throughput by up to 46%.
Adaptive Memory Replay for Continual Learning
Apr 18, 2024Foundation Models (FMs) have become the hallmark of modern AI, however, these models are trained on massive data, leading to financially expensive training. Updating FMs as new data becomes available is important, however, can lead to `catastrophic forgetting', where models underperform on tasks related to data sub-populations observed too long ago. This continual learning (CL) phenomenon has been extensively studied, but primarily in a setting where only a small amount of past data can be stored. We advocate for the paradigm where memory is abundant, allowing us to keep all previous data, but computational resources are limited. In this setting, traditional replay-based CL approaches are outperformed by a simple baseline which replays past data selected uniformly at random, indicating that this setting necessitates a new approach. We address this by introducing a framework of adaptive memory replay for continual learning, where sampling of past data is phrased as a multi-armed bandit problem. We utilize Bolzmann sampling to derive a method which dynamically selects past data for training conditioned on the current task, assuming full data access and emphasizing training efficiency. Through extensive evaluations on both vision and language pre-training tasks, we demonstrate the effectiveness of our approach, which maintains high performance while reducing forgetting by up to 10% at no training efficiency cost.
Continual Diffusion with STAMINA: STack-And-Mask INcremental Adapters
Nov 30, 2023



Recent work has demonstrated a remarkable ability to customize text-to-image diffusion models to multiple, fine-grained concepts in a sequential (i.e., continual) manner while only providing a few example images for each concept. This setting is known as continual diffusion. Here, we ask the question: Can we scale these methods to longer concept sequences without forgetting? Although prior work mitigates the forgetting of previously learned concepts, we show that its capacity to learn new tasks reaches saturation over longer sequences. We address this challenge by introducing a novel method, STack-And-Mask INcremental Adapters (STAMINA), which is composed of low-ranked attention-masked adapters and customized MLP tokens. STAMINA is designed to enhance the robust fine-tuning properties of LoRA for sequential concept learning via learnable hard-attention masks parameterized with low rank MLPs, enabling precise, scalable learning via sparse adaptation. Notably, all introduced trainable parameters can be folded back into the model after training, inducing no additional inference parameter costs. We show that STAMINA outperforms the prior SOTA for the setting of text-to-image continual customization on a 50-concept benchmark composed of landmarks and human faces, with no stored replay data. Additionally, we extended our method to the setting of continual learning for image classification, demonstrating that our gains also translate to state-of-the-art performance in this standard benchmark.
Fast Trainable Projection for Robust Fine-Tuning
Oct 29, 2023
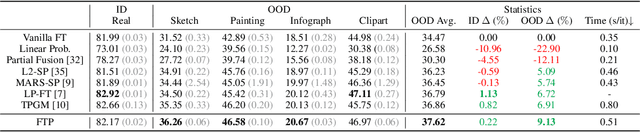

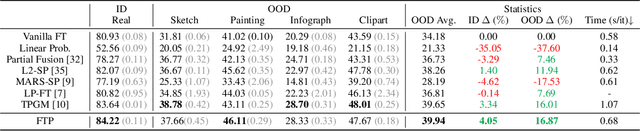
Robust fine-tuning aims to achieve competitive in-distribution (ID) performance while maintaining the out-of-distribution (OOD) robustness of a pre-trained model when transferring it to a downstream task. Recently, projected gradient descent has been successfully used in robust fine-tuning by constraining the deviation from the initialization of the fine-tuned model explicitly through projection. However, algorithmically, two limitations prevent this method from being adopted more widely, scalability and efficiency. In this paper, we propose a new projection-based fine-tuning algorithm, Fast Trainable Projection (FTP) for computationally efficient learning of per-layer projection constraints, resulting in an average $35\%$ speedup on our benchmarks compared to prior works. FTP can be combined with existing optimizers such as AdamW, and be used in a plug-and-play fashion. Finally, we show that FTP is a special instance of hyper-optimizers that tune the hyper-parameters of optimizers in a learnable manner through nested differentiation. Empirically, we show superior robustness on OOD datasets, including domain shifts and natural corruptions, across four different vision tasks with five different pre-trained models. Additionally, we demonstrate that FTP is broadly applicable and beneficial to other learning scenarios such as low-label and continual learning settings thanks to its easy adaptability. The code will be available at https://github.com/GT-RIPL/FTP.git.
HePCo: Data-Free Heterogeneous Prompt Consolidation for Continual Federated Learning
Jun 16, 2023
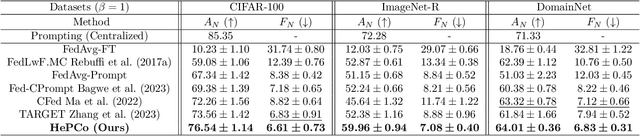
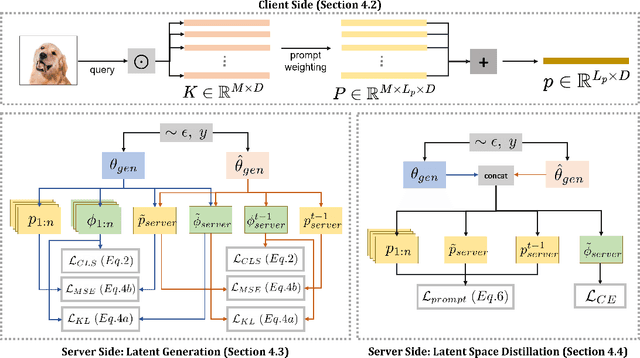

In this paper, we focus on the important yet understudied problem of Continual Federated Learning (CFL), where a server communicates with a set of clients to incrementally learn new concepts over time without sharing or storing any data. The complexity of this problem is compounded by challenges from both the Continual and Federated Learning perspectives. Specifically, models trained in a CFL setup suffer from catastrophic forgetting which is exacerbated by data heterogeneity across clients. Existing attempts at this problem tend to impose large overheads on clients and communication channels or require access to stored data which renders them unsuitable for real-world use due to privacy. In this paper, we attempt to tackle forgetting and heterogeneity while minimizing overhead costs and without requiring access to any stored data. We achieve this by leveraging a prompting based approach (such that only prompts and classifier heads have to be communicated) and proposing a novel and lightweight generation and distillation scheme to consolidate client models at the server. We formulate this problem for image classification and establish strong baselines for comparison, conduct experiments on CIFAR-100 as well as challenging, large-scale datasets like ImageNet-R and DomainNet. Our approach outperforms both existing methods and our own baselines by as much as 7% while significantly reducing communication and client-level computation costs.
Continual Diffusion: Continual Customization of Text-to-Image Diffusion with C-LoRA
Apr 12, 2023Recent works demonstrate a remarkable ability to customize text-to-image diffusion models while only providing a few example images. What happens if you try to customize such models using multiple, fine-grained concepts in a sequential (i.e., continual) manner? In our work, we show that recent state-of-the-art customization of text-to-image models suffer from catastrophic forgetting when new concepts arrive sequentially. Specifically, when adding a new concept, the ability to generate high quality images of past, similar concepts degrade. To circumvent this forgetting, we propose a new method, C-LoRA, composed of a continually self-regularized low-rank adaptation in cross attention layers of the popular Stable Diffusion model. Furthermore, we use customization prompts which do not include the word of the customized object (i.e., "person" for a human face dataset) and are initialized as completely random embeddings. Importantly, our method induces only marginal additional parameter costs and requires no storage of user data for replay. We show that C-LoRA not only outperforms several baselines for our proposed setting of text-to-image continual customization, which we refer to as Continual Diffusion, but that we achieve a new state-of-the-art in the well-established rehearsal-free continual learning setting for image classification. The high achieving performance of C-LoRA in two separate domains positions it as a compelling solution for a wide range of applications, and we believe it has significant potential for practical impact.
Going Beyond Nouns With Vision & Language Models Using Synthetic Data
Mar 30, 2023



Large-scale pre-trained Vision & Language (VL) models have shown remarkable performance in many applications, enabling replacing a fixed set of supported classes with zero-shot open vocabulary reasoning over (almost arbitrary) natural language prompts. However, recent works have uncovered a fundamental weakness of these models. For example, their difficulty to understand Visual Language Concepts (VLC) that go 'beyond nouns' such as the meaning of non-object words (e.g., attributes, actions, relations, states, etc.), or difficulty in performing compositional reasoning such as understanding the significance of the order of the words in a sentence. In this work, we investigate to which extent purely synthetic data could be leveraged to teach these models to overcome such shortcomings without compromising their zero-shot capabilities. We contribute Synthetic Visual Concepts (SyViC) - a million-scale synthetic dataset and data generation codebase allowing to generate additional suitable data to improve VLC understanding and compositional reasoning of VL models. Additionally, we propose a general VL finetuning strategy for effectively leveraging SyViC towards achieving these improvements. Our extensive experiments and ablations on VL-Checklist, Winoground, and ARO benchmarks demonstrate that it is possible to adapt strong pre-trained VL models with synthetic data significantly enhancing their VLC understanding (e.g. by 9.9% on ARO and 4.3% on VL-Checklist) with under 1% drop in their zero-shot accuracy.