 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometry of Robustness: Optimizing Loss Landscape Curvature and Feature Manifold Alignment for Robust Finetuning of Vision-Language Models
Mar 28, 2026Fine-tuning approaches for Vision-Language Models (VLMs) face a critical three-way trade-off between In-Distribution (ID) accuracy, Out-of-Distribution (OOD) generalization, and adversarial robustness. Existing robust fine-tuning strategies resolve at most two axes of this trade-off. Generalization-preserving methods retain ID/OOD performance but leave models vulnerable to adversarial attacks, while adversarial training improves robustness to targeted attacks but degrades ID/OOD accuracy. Our key insight is that the robustness trade-off stems from two geometric failures: sharp, anisotropic minima in parameter space and unstable feature representations that deform under perturbation. To address this, we propose GRACE (Gram-aligned Robustness via Adaptive Curvature Estimation), a unified fine-tuning framework that jointly regularizes the parameter-space curvature and feature-space invariance for VLMs. Grounded in Robust PAC-Bayes theory, GRACE employs adaptive weight perturbations scaled by local curvature to promote flatter minima, combined with a feature alignment loss that maintains representation consistency across clean, adversarial, and OOD inputs. On ImageNet fine-tuning of CLIP models, GRACE simultaneously improves ID accuracy by 10.8%, and adversarial accuracy by 13.5% while maintaining 57.0% OOD accuracy (vs. 57.4% zero-shot baseline). Geometric analysis confirms that GRACE converges to flatter minima without feature distortion across distribution shifts, providing a principled step toward generalized robustness in foundation VLMs.
VIRTUE: Versatile Video Retrieval Through Unified Embeddings
Jan 17, 2026Modern video retrieval systems are expected to handle diverse tasks ranging from corpus-level retrieval and fine-grained moment localization to flexible multimodal querying. Specialized architectures achieve strong retrieval performance by training modality-specific encoders on massive datasets, but they lack the ability to process composed multimodal queries. In contrast, multimodal LLM (MLLM)-based methods support rich multimodal search but their retrieval performance remains well below that of specialized systems. We present VIRTUE, an MLLM-based versatile video retrieval framework that integrates corpus and moment-level retrieval capabilities while accommodating composed multimodal queries within a single architecture. We use contrastive alignment of visual and textual embeddings generated using a shared MLLM backbone to facilitate efficient embedding-based candidate search. Our embedding model, trained efficiently using low-rank adaptation (LoRA) on 700K paired visual-text data samples, surpasses other MLLM-based methods on zero-shot video retrieval tasks. Additionally, we demonstrate that the same model can be adapted without further training to achieve competitive results on zero-shot moment retrieval, and state of the art results for zero-shot composed video retrieval. With additional training for reranking candidates identified in the embedding-based search, our model substantially outperforms existing MLLM-based retrieval systems and achieves retrieval performance comparable to state of the art specialized models which are trained on orders of magnitude larger data.
Grounding Descriptions in Images informs Zero-Shot Visual Recognition
Dec 05, 2024



Vision-language models (VLMs) like CLIP have been cherished for their ability to perform zero-shot visual recognition on open-vocabulary concepts. This is achieved by selecting the object category whose textual representation bears the highest similarity with the query image. While successful in some domains, this method struggles with identifying fine-grained entities as well as generalizing to unseen concepts that are not captured by the training distribution. Recent works attempt to mitigate these challenges by integrating category descriptions at test time, albeit yielding modest improvements. We attribute these limited gains to a fundamental misalignment between image and description representations, which is rooted in the pretraining structure of CLIP. In this paper, we propose GRAIN, a new pretraining strategy aimed at aligning representations at both fine and coarse levels simultaneously. Our approach learns to jointly ground textual descriptions in image regions along with aligning overarching captions with global image representations. To drive this pre-training, we leverage frozen Multimodal Large Language Models (MLLMs) to derive large-scale synthetic annotations. We demonstrate the enhanced zero-shot performance of our model compared to current state-of-the art methods across 11 diverse image classification datasets. Additionally, we introduce Products-2023, a newly curated, manually labeled dataset featuring novel concepts, and showcase our model's ability to recognize these concepts by benchmarking on it. Significant improvements achieved by our model on other downstream tasks like retrieval further highlight the superior quality of representations learned by our approach. Code available at https://github.com/shaunak27/grain-clip .
Adaptive Memory Replay for Continual Learning
Apr 18, 2024Foundation Models (FMs) have become the hallmark of modern AI, however, these models are trained on massive data, leading to financially expensive training. Updating FMs as new data becomes available is important, however, can lead to `catastrophic forgetting', where models underperform on tasks related to data sub-populations observed too long ago. This continual learning (CL) phenomenon has been extensively studied, but primarily in a setting where only a small amount of past data can be stored. We advocate for the paradigm where memory is abundant, allowing us to keep all previous data, but computational resources are limited. In this setting, traditional replay-based CL approaches are outperformed by a simple baseline which replays past data selected uniformly at random, indicating that this setting necessitates a new approach. We address this by introducing a framework of adaptive memory replay for continual learning, where sampling of past data is phrased as a multi-armed bandit problem. We utilize Bolzmann sampling to derive a method which dynamically selects past data for training conditioned on the current task, assuming full data access and emphasizing training efficiency. Through extensive evaluations on both vision and language pre-training tasks, we demonstrate the effectiveness of our approach, which maintains high performance while reducing forgetting by up to 10% at no training efficiency cost.
HePCo: Data-Free Heterogeneous Prompt Consolidation for Continual Federated Learning
Jun 16, 2023
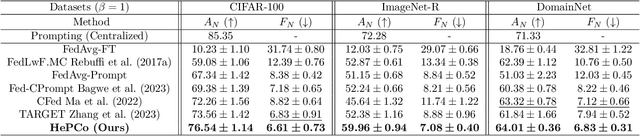
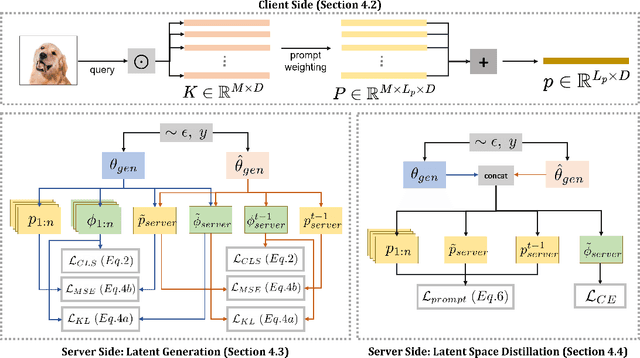

In this paper, we focus on the important yet understudied problem of Continual Federated Learning (CFL), where a server communicates with a set of clients to incrementally learn new concepts over time without sharing or storing any data. The complexity of this problem is compounded by challenges from both the Continual and Federated Learning perspectives. Specifically, models trained in a CFL setup suffer from catastrophic forgetting which is exacerbated by data heterogeneity across clients. Existing attempts at this problem tend to impose large overheads on clients and communication channels or require access to stored data which renders them unsuitable for real-world use due to privacy. In this paper, we attempt to tackle forgetting and heterogeneity while minimizing overhead costs and without requiring access to any stored data. We achieve this by leveraging a prompting based approach (such that only prompts and classifier heads have to be communicated) and proposing a novel and lightweight generation and distillation scheme to consolidate client models at the server. We formulate this problem for image classification and establish strong baselines for comparison, conduct experiments on CIFAR-100 as well as challenging, large-scale datasets like ImageNet-R and DomainNet. Our approach outperforms both existing methods and our own baselines by as much as 7% while significantly reducing communication and client-level computation costs.
DAIR: Data Augmented Invariant Regularization
Oct 21, 2021


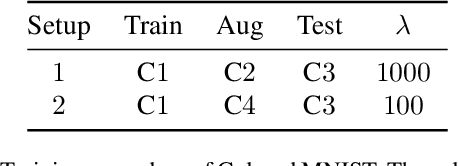
While deep learning through empirical risk minimization (ERM) has succeeded at achieving human-level performance at a variety of complex tasks, ERM generalizes poorly to distribution shift. This is partly explained by overfitting to spurious features such as background in images or named entities in natural language. Synthetic data augmentation followed by empirical risk minimization (DA-ERM) is a simple yet powerful solution to remedy this problem. In this paper, we propose data augmented invariant regularization (DAIR). The idea of DAIR is based on the observation that the model performance (loss) is desired to be consistent on the augmented sample and the original one. DAIR introduces a regularizer on DA-ERM to penalize such loss inconsistency. Both theoretically and through empirical experiments, we show that a particular form of the DAIR regularizer consistently performs well in a variety of settings. We apply it to multiple real-world learning problems involving domain shift, namely robust regression, visual question answering, robust deep neural network training, and task-oriented dialog modeling. Our experiments show that DAIR consistently outperforms ERM and DA-ERM with little marginal cost and setting new state-of-the-art results in several benchmarks.
Exploring Weaknesses of VQA Models through Attribution Driven Insights
Jun 16, 2020
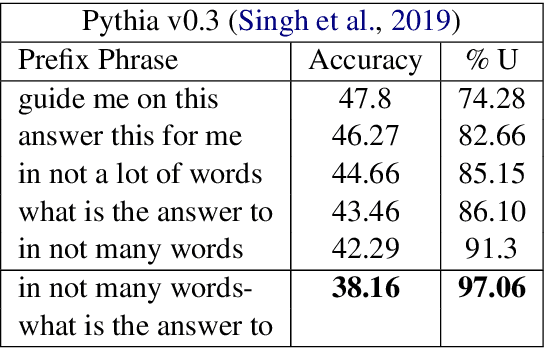

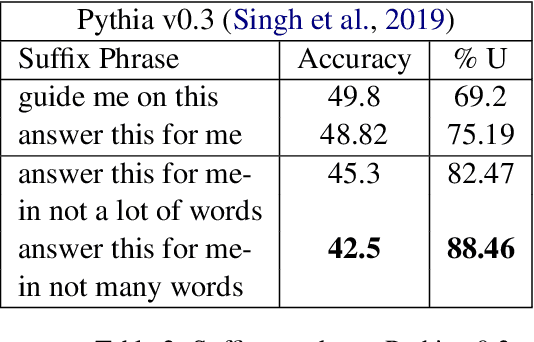
Deep Neural Networks have been successfully used for the task of Visual Question Answering for the past few years owing to the availability of relevant large scale datasets. However these datasets are created in artificial settings and rarely reflect the real world scenario. Recent research effectively applies these VQA models for answering visual questions for the blind. Despite achieving high accuracy these models appear to be susceptible to variation in input questions.We analyze popular VQA models through the lens of attribution (input's influence on predictions) to gain valuable insights. Further, We use these insights to craft adversarial attacks which inflict significant damage to these systems with negligible change in meaning of the input questions. We believe this will enhance development of systems more robust to the possible variations in inputs when deployed to assist the visually impaired.