 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUTODIAL: Efficient Asynchronous Task-Oriented Dialogue Model
Mar 10, 2023



As large dialogue models become commonplace in practice, the problems surrounding high compute requirements for training, inference and larger memory footprint still persists. In this work, we present AUTODIAL, a multi-task dialogue model that addresses the challenges of deploying dialogue model. AUTODIAL utilizes parallel decoders to perform tasks such as dialogue act prediction, domain prediction, intent prediction, and dialogue state tracking. Using classification decoders over generative decoders allows AUTODIAL to significantly reduce memory footprint and achieve faster inference times compared to existing generative approach namely SimpleTOD. We demonstrate that AUTODIAL provides 3-6x speedups during inference while having 11x fewer parameters on three dialogue tasks compared to SimpleTOD. Our results show that extending current dialogue models to have parallel decoders can be a viable alternative for deploying them in resource-constrained environments.
DAIR: Data Augmented Invariant Regularization
Oct 21, 2021


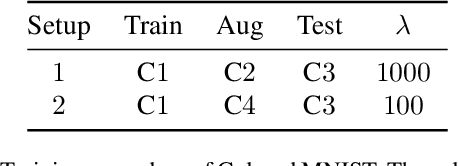
While deep learning through empirical risk minimization (ERM) has succeeded at achieving human-level performance at a variety of complex tasks, ERM generalizes poorly to distribution shift. This is partly explained by overfitting to spurious features such as background in images or named entities in natural language. Synthetic data augmentation followed by empirical risk minimization (DA-ERM) is a simple yet powerful solution to remedy this problem. In this paper, we propose data augmented invariant regularization (DAIR). The idea of DAIR is based on the observation that the model performance (loss) is desired to be consistent on the augmented sample and the original one. DAIR introduces a regularizer on DA-ERM to penalize such loss inconsistency. Both theoretically and through empirical experiments, we show that a particular form of the DAIR regularizer consistently performs well in a variety of settings. We apply it to multiple real-world learning problems involving domain shift, namely robust regression, visual question answering, robust deep neural network training, and task-oriented dialog modeling. Our experiments show that DAIR consistently outperforms ERM and DA-ERM with little marginal cost and setting new state-of-the-art results in several benchmarks.