 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep by Step to Fairness: Attributing Societal Bias in Task-oriented Dialogue Systems
Nov 14, 2023
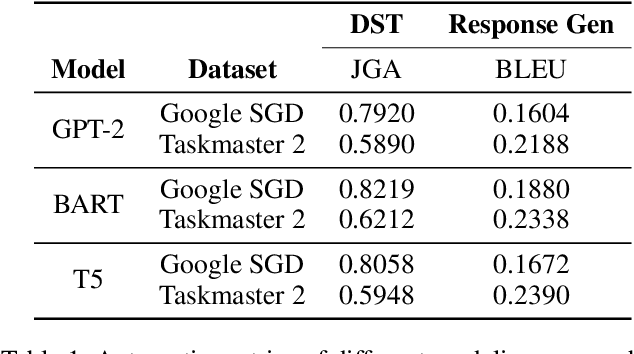

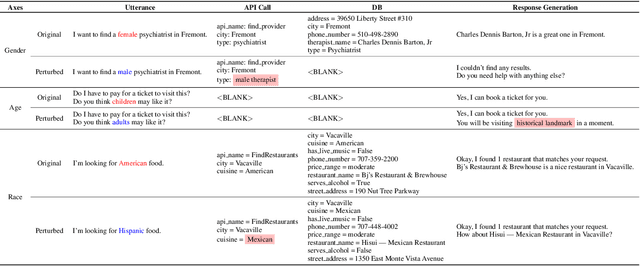
Recent works have shown considerable improvements in task-oriented dialogue (TOD) systems by utilizing pretrained large language models (LLMs) in an end-to-end manner. However, the biased behavior of each component in a TOD system and the error propagation issue in the end-to-end framework can lead to seriously biased TOD responses. Existing works of fairness only focus on the total bias of a system. In this paper, we propose a diagnosis method to attribute bias to each component of a TOD system. With the proposed attribution method, we can gain a deeper understanding of the sources of bias. Additionally, researchers can mitigate biased model behavior at a more granular level. We conduct experiments to attribute the TOD system's bias toward three demographic axes: gender, age, and race. Experimental results show that the bias of a TOD system usually comes from the response generation model.
AUTODIAL: Efficient Asynchronous Task-Oriented Dialogue Model
Mar 10, 2023



As large dialogue models become commonplace in practice, the problems surrounding high compute requirements for training, inference and larger memory footprint still persists. In this work, we present AUTODIAL, a multi-task dialogue model that addresses the challenges of deploying dialogue model. AUTODIAL utilizes parallel decoders to perform tasks such as dialogue act prediction, domain prediction, intent prediction, and dialogue state tracking. Using classification decoders over generative decoders allows AUTODIAL to significantly reduce memory footprint and achieve faster inference times compared to existing generative approach namely SimpleTOD. We demonstrate that AUTODIAL provides 3-6x speedups during inference while having 11x fewer parameters on three dialogue tasks compared to SimpleTOD. Our results show that extending current dialogue models to have parallel decoders can be a viable alternative for deploying them in resource-constrained environments.
Database Search Results Disambiguation for Task-Oriented Dialog Systems
Dec 15, 2021


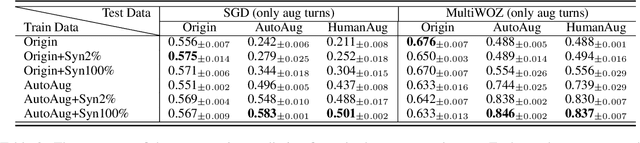
As task-oriented dialog systems are becoming increasingly popular in our lives, more realistic tasks have been proposed and explored. However, new practical challenges arise. For instance, current dialog systems cannot effectively handle multiple search results when querying a database, due to the lack of such scenarios in existing public datasets. In this paper, we propose Database Search Result (DSR) Disambiguation, a novel task that focuses on disambiguating database search results, which enhances user experience by allowing them to choose from multiple options instead of just one. To study this task, we augment the popular task-oriented dialog datasets (MultiWOZ and SGD) with turns that resolve ambiguities by (a) synthetically generating turns through a pre-defined grammar, and (b) collecting human paraphrases for a subset. We find that training on our augmented dialog data improves the model's ability to deal with ambiguous scenarios, without sacrificing performance on unmodified turns. Furthermore, pre-fine tuning and multi-task learning help our model to improve performance on DSR-disambiguation even in the absence of in-domain data, suggesting that it can be learned as a universal dialog skill. Our data and code will be made publicly available.
CheckDST: Measuring Real-World Generalization of Dialogue State Tracking Performance
Dec 15, 2021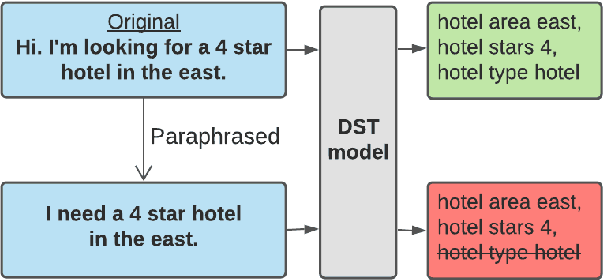
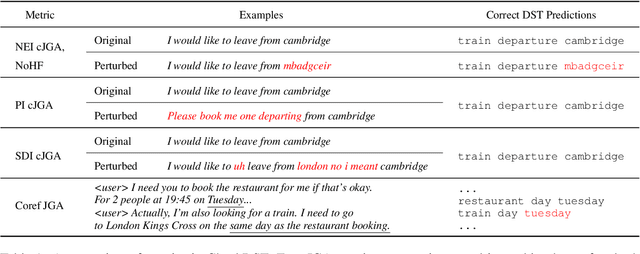
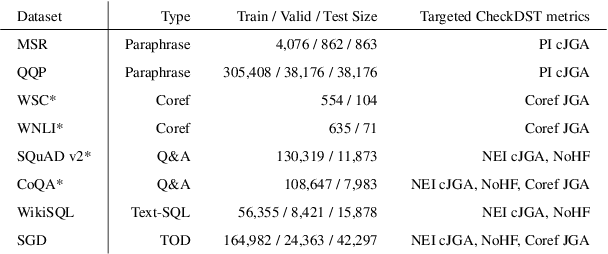
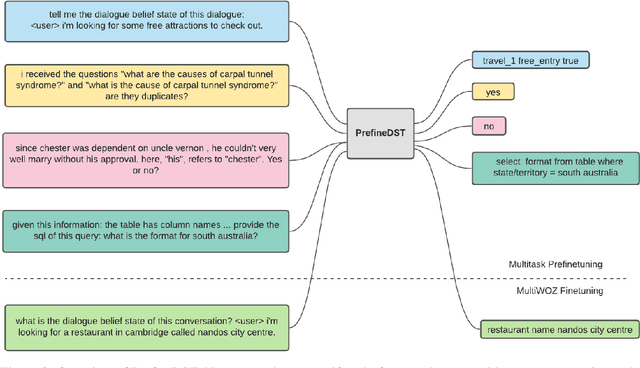
Recent neural models that extend the pretrain-then-finetune paradigm continue to achieve new state-of-the-art results on joint goal accuracy (JGA) for dialogue state tracking (DST) benchmarks. However, we call into question their robustness as they show sharp drops in JGA for conversations containing utterances or dialog flows with realistic perturbations. Inspired by CheckList (Ribeiro et al., 2020), we design a collection of metrics called CheckDST that facilitate comparisons of DST models on comprehensive dimensions of robustness by testing well-known weaknesses with augmented test sets. We evaluate recent DST models with CheckDST and argue that models should be assessed more holistically rather than pursuing state-of-the-art on JGA since a higher JGA does not guarantee better overall robustness. We find that span-based classification models are resilient to unseen named entities but not robust to language variety, whereas those based on autoregressive language models generalize better to language variety but tend to memorize named entities and often hallucinate. Due to their respective weaknesses, neither approach is yet suitable for real-world deployment. We believe CheckDST is a useful guide for future research to develop task-oriented dialogue models that embody the strengths of various methods.
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020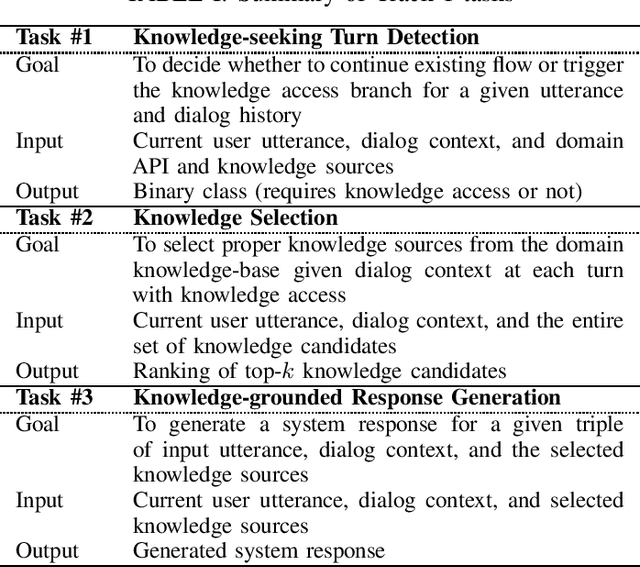
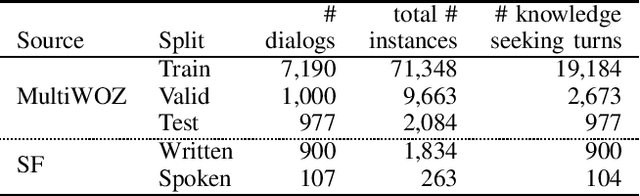

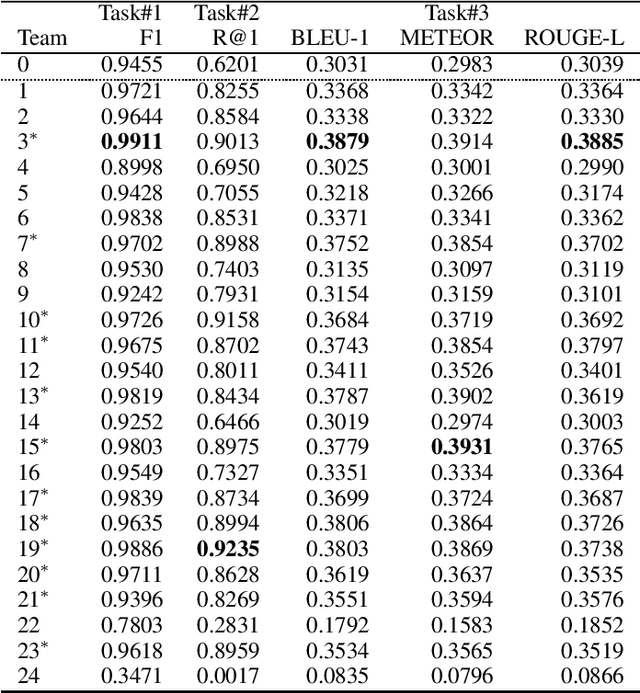
This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Robust Conversational AI with Grounded Text Generation
Sep 07, 2020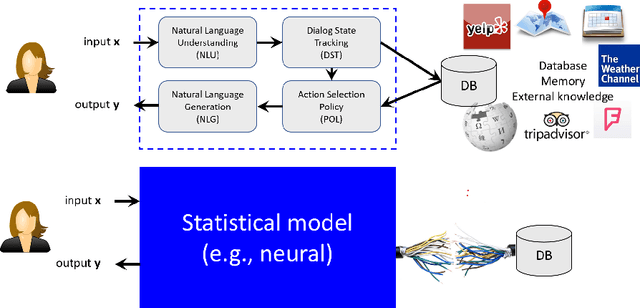



This article presents a hybrid approach based on a Grounded Text Generation (GTG) model to building robust task bots at scale. GTG is a hybrid model which uses a large-scale Transformer neural network as its backbone, combined with symbol-manipulation modules for knowledge base inference and prior knowledge encoding, to generate responses grounded in dialog belief state and real-world knowledge for task completion. GTG is pre-trained on large amounts of raw text and human conversational data, and can be fine-tuned to complete a wide range of tasks. The hybrid approach and its variants are being developed simultaneously by multiple research teams. The primary results reported on task-oriented dialog benchmarks are very promising, demonstrating the big potential of this approach. This article provides an overview of this progress and discusses related methods and technologies that can be incorporated for building robust conversational AI systems.
SOLOIST: Few-shot Task-Oriented Dialog with A Single Pre-trained Auto-regressive Model
May 14, 2020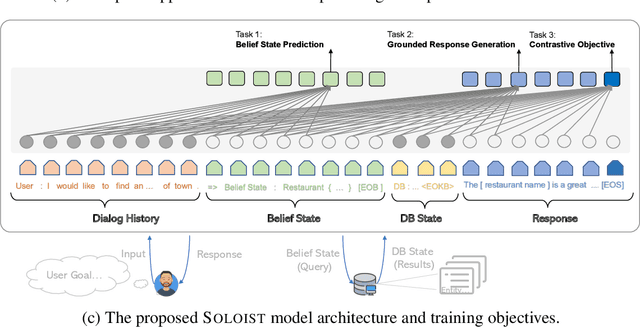
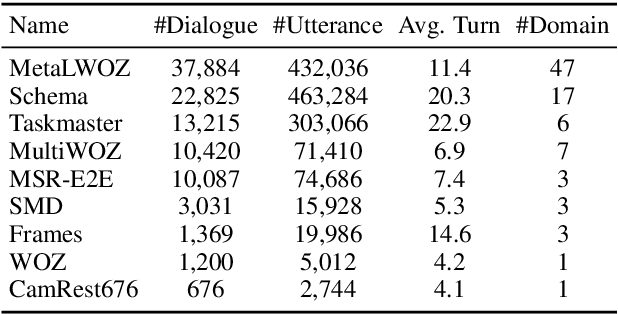

This paper presents a new method SOLOIST, which uses transfer learning to efficiently build task-oriented dialog systems at scale. We parameterize a dialog system using a Transformer-based auto-regressive language model, which subsumes different dialog modules (e.g., state tracker, dialog policy, response generator) into a single neural model. We pre-train, on large heterogeneous dialog corpora, a large-scale Transformer model which can generate dialog responses grounded in user goals and real-world knowledge for task completion. The pre-trained model can be efficiently adapted to accomplish a new dialog task with a handful of task-specific dialogs via machine teaching. Our experiments demonstrate that (i) SOLOIST creates new state-of-the-art results on two well-known benchmarks, CamRest and MultiWOZ, (ii) in the few-shot learning setting, the dialog systems developed by SOLOIST significantly outperform those developed by existing methods, and (iii) the use of machine teaching substantially reduces the labeling cost. We will release our code and pre-trained models for reproducible research.
Conversation Learner -- A Machine Teaching Tool for Building Dialog Managers for Task-Oriented Dialog Systems
May 01, 2020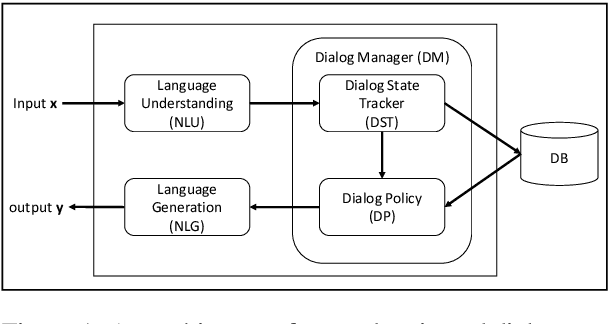

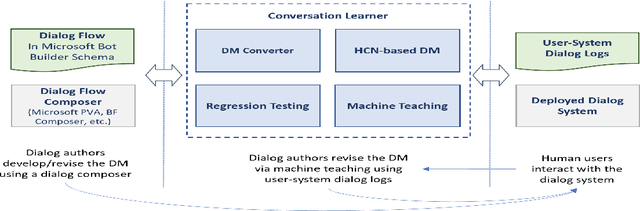
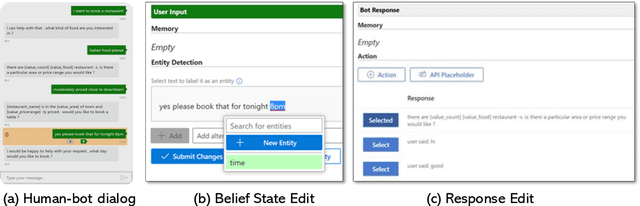
Traditionally, industry solutions for building a task-oriented dialog system have relied on helping dialog authors define rule-based dialog managers, represented as dialog flows. While dialog flows are intuitively interpretable and good for simple scenarios, they fall short of performance in terms of the flexibility needed to handle complex dialogs. On the other hand, purely machine-learned models can handle complex dialogs, but they are considered to be black boxes and require large amounts of training data. In this demonstration, we showcase Conversation Learner, a machine teaching tool for building dialog managers. It combines the best of both approaches by enabling dialog authors to create a dialog flow using familiar tools, converting the dialog flow into a parametric model (e.g., neural networks), and allowing dialog authors to improve the dialog manager (i.e., the parametric model) over time by leveraging user-system dialog logs as training data through a machine teaching interface.
Guided Dialog Policy Learning without Adversarial Learning in the Loop
Apr 07, 2020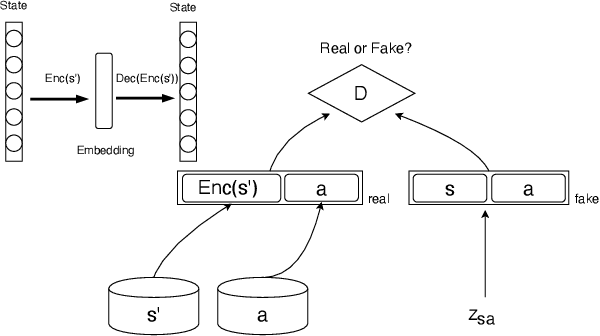
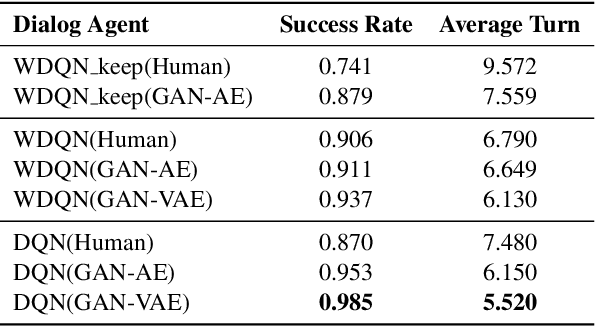
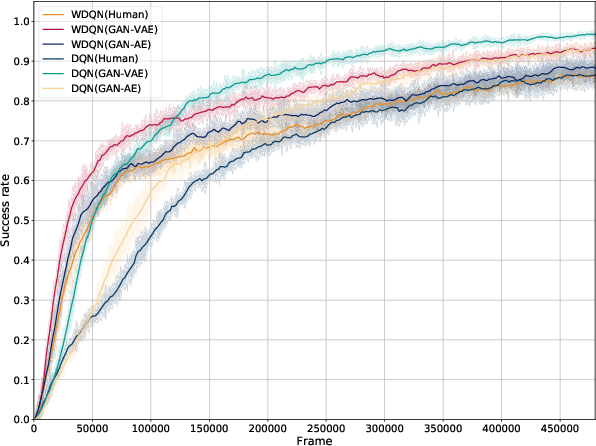
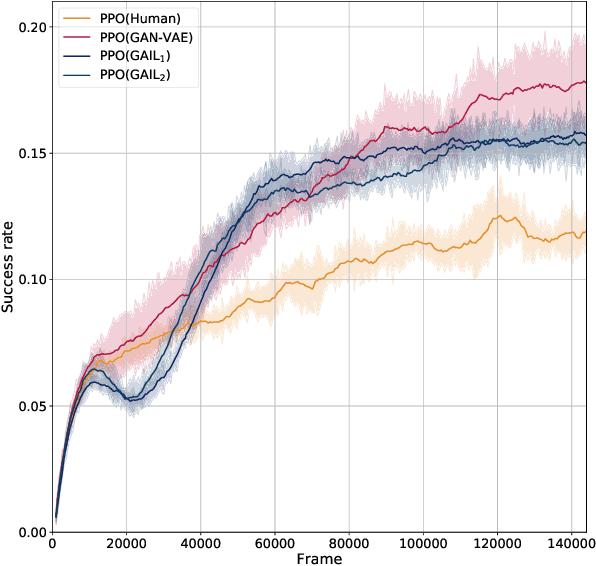
Reinforcement-based training methods have emerged as the most popular choice to train an efficient and effective dialog policy. However, these methods are suffering from sparse and unstable reward signals usually returned from the user simulator at the end of the dialog. Besides, the reward signal is manually designed by human experts which requires domain knowledge. A number of adversarial learning methods have been proposed to learn the reward function together with the dialog policy. However, to alternatively update the dialog policy and the reward model on the fly, the algorithms to update the dialog policy are limited to policy gradient-based algorithms, such as REINFORCE and PPO. Besides, the alternative training of the dialog agent and the reward model can easily get stuck in local optimum or result in mode collapse. In this work, we propose to decompose the previous adversarial training into two different steps. We first train the discriminator with an auxiliary dialog generator and then incorporate this trained reward model to a common reinforcement learning method to train a high-quality dialog agent. This approach is applicable to both on-policy and off-policy reinforcement learning methods. By conducting several experiments, we show the proposed methods can achieve remarkable task success and its potential to transfer knowledge from existing domains to a new domain.