 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsgardBench - Evaluating Visually Grounded Interactive Planning Under Minimal Feedback
Mar 16, 2026With AsgardBench we aim to evaluate visually grounded, high-level action sequence generation and interactive planning, focusing specifically on plan adaptation during execution based on visual observations rather than navigation or low-level manipulation. In the landscape of embodied AI benchmarks, AsgardBench targets the capability category of interactive planning, which is more sophisticated than offline high-level planning as it requires agents to revise plans in response to environmental feedback, yet remains distinct from low-level execution. Unlike prior embodied AI benchmarks that conflate reasoning with navigation or provide rich corrective feedback that substitutes for perception, AsgardBench restricts agent input to images, action history, and lightweight success/failure signals, isolating interactive planning in a controlled simulator without low-level control noise. The benchmark contains 108 task instances spanning 12 task types, each systematically varied through object state, placement, and scene configuration. These controlled variations create conditional branches in which a single instruction can require different action sequences depending on what the agent observes, emphasizing conditional branching and plan repair during execution. Our evaluations of leading vision language models show that performance drops sharply without visual input, revealing weaknesses in visual grounding and state tracking that ultimately undermine interactive planning. Our benchmark zeroes in on a narrower question: can a model actually use what it sees to adapt a plan when things do not go as expected?
Magma: A Foundation Model for Multimodal AI Agents
Feb 18, 2025We present Magma, a foundation model that serves multimodal AI agentic tasks in both the digital and physical worlds. Magma is a significant extension of vision-language (VL) models in that it not only retains the VL understanding ability (verbal intelligence) of the latter, but is also equipped with the ability to plan and act in the visual-spatial world (spatial-temporal intelligence) and complete agentic tasks ranging from UI navigation to robot manipulation. To endow the agentic capabilities, Magma is pretrained on large amounts of heterogeneous datasets spanning from images, videos to robotics data, where the actionable visual objects (e.g., clickable buttons in GUI) in images are labeled by Set-of-Mark (SoM) for action grounding, and the object movements (e.g., the trace of human hands or robotic arms) in videos are labeled by Trace-of-Mark (ToM) for action planning. Extensive experiments show that SoM and ToM reach great synergy and facilitate the acquisition of spatial-temporal intelligence for our Magma model, which is fundamental to a wide range of tasks as shown in Fig.1. In particular, Magma creates new state-of-the-art results on UI navigation and robotic manipulation tasks, outperforming previous models that are specifically tailored to these tasks. On image and video-related multimodal tasks, Magma also compares favorably to popular large multimodal models that are trained on much larger datasets. We make our model and code public for reproducibility at https://microsoft.github.io/Magma.
Latent Action Pretraining from Videos
Oct 15, 2024



We introduce Latent Action Pretraining for general Action models (LAPA), an unsupervised method for pretraining Vision-Language-Action (VLA) models without ground-truth robot action labels. Existing Vision-Language-Action models require action labels typically collected by human teleoperators during pretraining, which significantly limits possible data sources and scale. In this work, we propose a method to learn from internet-scale videos that do not have robot action labels. We first train an action quantization model leveraging VQ-VAE-based objective to learn discrete latent actions between image frames, then pretrain a latent VLA model to predict these latent actions from observations and task descriptions, and finally finetune the VLA on small-scale robot manipulation data to map from latent to robot actions. Experimental results demonstrate that our method significantly outperforms existing techniques that train robot manipulation policies from large-scale videos. Furthermore, it outperforms the state-of-the-art VLA model trained with robotic action labels on real-world manipulation tasks that require language conditioning, generalization to unseen objects, and semantic generalization to unseen instructions. Training only on human manipulation videos also shows positive transfer, opening up the potential for leveraging web-scale data for robotics foundation model.
Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback
Mar 08, 2023

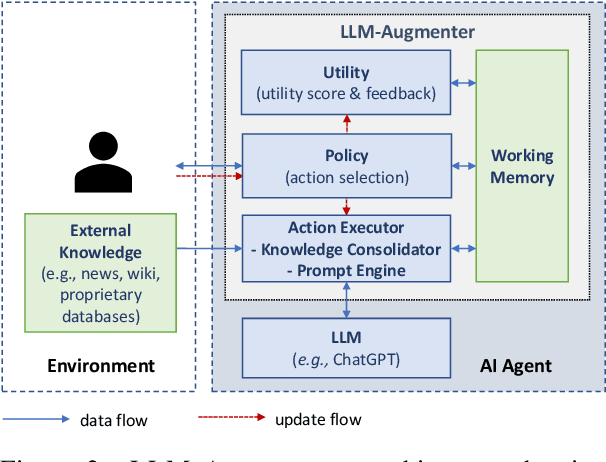

Large language models (LLMs), such as ChatGPT, are able to generate human-like, fluent responses for many downstream tasks, e.g., task-oriented dialog and question answering. However, applying LLMs to real-world, mission-critical applications remains challenging mainly due to their tendency to generate hallucinations and their inability to use external knowledge. This paper proposes a LLM-Augmenter system, which augments a black-box LLM with a set of plug-and-play modules. Our system makes the LLM generate responses grounded in external knowledge, e.g., stored in task-specific databases. It also iteratively revises LLM prompts to improve model responses using feedback generated by utility functions, e.g., the factuality score of a LLM-generated response. The effectiveness of LLM-Augmenter is empirically validated on two types of scenarios, task-oriented dialog and open-domain question answering. LLM-Augmenter significantly reduces ChatGPT's hallucinations without sacrificing the fluency and informativeness of its responses. We make the source code and models publicly available.
GODEL: Large-Scale Pre-Training for Goal-Directed Dialog
Jun 22, 2022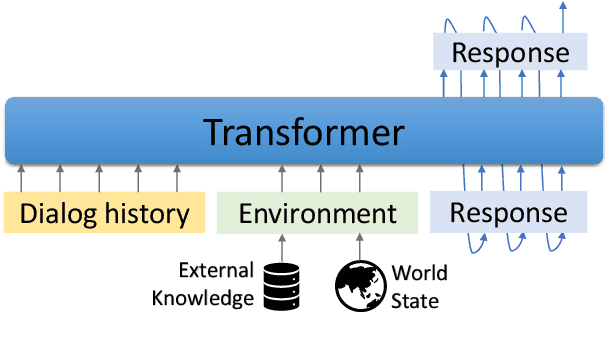
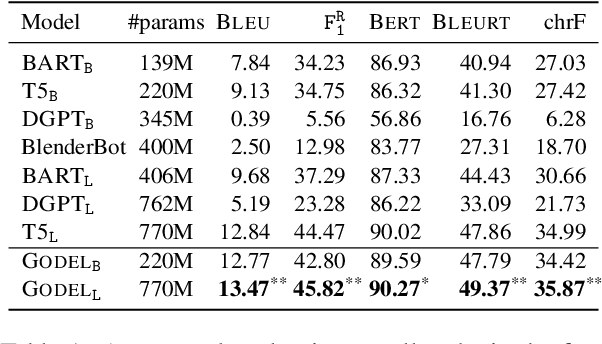

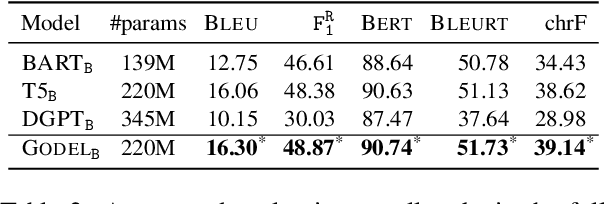
We introduce GODEL (Grounded Open Dialogue Language Model), a large pre-trained language model for dialog. In contrast with earlier models such as DialoGPT, GODEL leverages a new phase of grounded pre-training designed to better support adapting GODEL to a wide range of downstream dialog tasks that require information external to the current conversation (e.g., a database or document) to produce good responses. Experiments against an array of benchmarks that encompass task-oriented dialog, conversational QA, and grounded open-domain dialog show that GODEL outperforms state-of-the-art pre-trained dialog models in few-shot fine-tuning setups, in terms of both human and automatic evaluation. A novel feature of our evaluation methodology is the introduction of a notion of utility that assesses the usefulness of responses (extrinsic evaluation) in addition to their communicative features (intrinsic evaluation). We show that extrinsic evaluation offers improved inter-annotator agreement and correlation with automated metrics. Code and data processing scripts are publicly available.
Knowledge-Grounded Dialogue Generation with a Unified Knowledge Representation
Dec 15, 2021
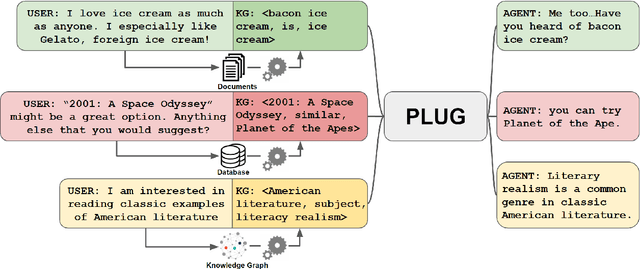

Knowledge-grounded dialogue systems are challenging to build due to the lack of training data and heterogeneous knowledge sources. Existing systems perform poorly on unseen topics due to limited topics covered in the training data. In addition, heterogeneous knowledge sources make it challenging for systems to generalize to other tasks because knowledge sources in different knowledge representations require different knowledge encoders. To address these challenges, we present PLUG, a language model that homogenizes different knowledge sources to a unified knowledge representation for knowledge-grounded dialogue generation tasks. PLUG is pre-trained on a dialogue generation task conditioned on a unified essential knowledge representation. It can generalize to different downstream knowledge-grounded dialogue generation tasks with a few training examples. The empirical evaluation on two benchmarks shows that our model generalizes well across different knowledge-grounded tasks. It can achieve comparable performance with state-of-the-art methods under a fully-supervised setting and significantly outperforms other methods in zero-shot and few-shot settings.
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020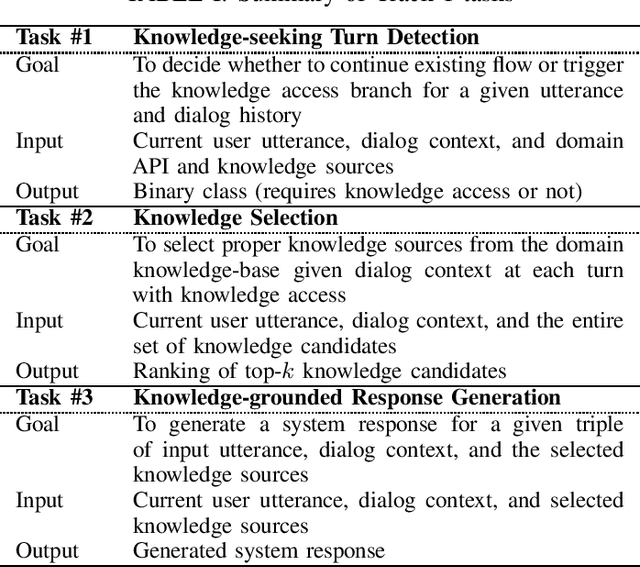

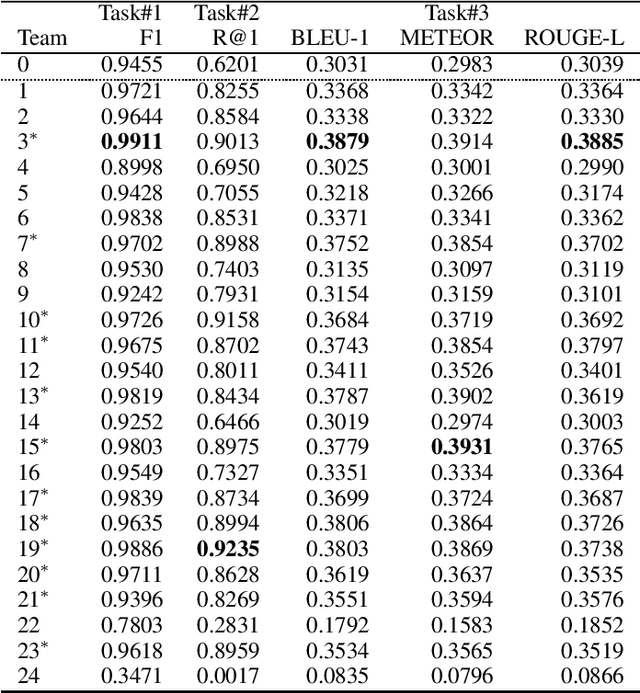
This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Robust Conversational AI with Grounded Text Generation
Sep 07, 2020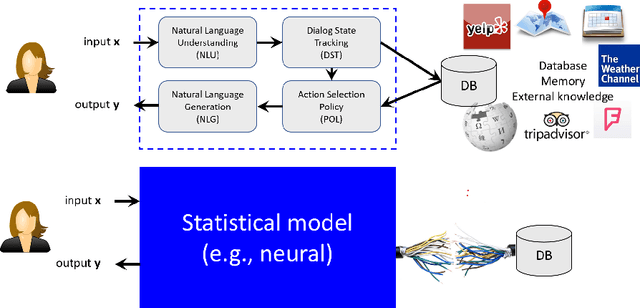



This article presents a hybrid approach based on a Grounded Text Generation (GTG) model to building robust task bots at scale. GTG is a hybrid model which uses a large-scale Transformer neural network as its backbone, combined with symbol-manipulation modules for knowledge base inference and prior knowledge encoding, to generate responses grounded in dialog belief state and real-world knowledge for task completion. GTG is pre-trained on large amounts of raw text and human conversational data, and can be fine-tuned to complete a wide range of tasks. The hybrid approach and its variants are being developed simultaneously by multiple research teams. The primary results reported on task-oriented dialog benchmarks are very promising, demonstrating the big potential of this approach. This article provides an overview of this progress and discusses related methods and technologies that can be incorporated for building robust conversational AI systems.
SOLOIST: Few-shot Task-Oriented Dialog with A Single Pre-trained Auto-regressive Model
May 14, 2020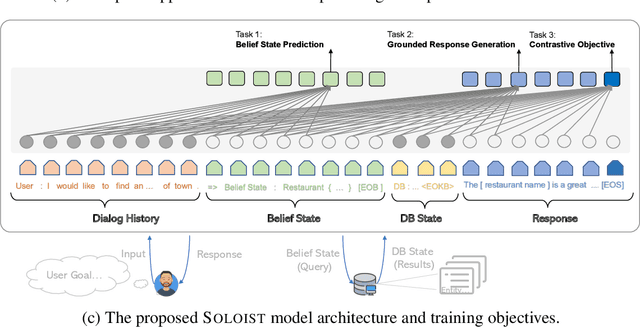

This paper presents a new method SOLOIST, which uses transfer learning to efficiently build task-oriented dialog systems at scale. We parameterize a dialog system using a Transformer-based auto-regressive language model, which subsumes different dialog modules (e.g., state tracker, dialog policy, response generator) into a single neural model. We pre-train, on large heterogeneous dialog corpora, a large-scale Transformer model which can generate dialog responses grounded in user goals and real-world knowledge for task completion. The pre-trained model can be efficiently adapted to accomplish a new dialog task with a handful of task-specific dialogs via machine teaching. Our experiments demonstrate that (i) SOLOIST creates new state-of-the-art results on two well-known benchmarks, CamRest and MultiWOZ, (ii) in the few-shot learning setting, the dialog systems developed by SOLOIST significantly outperform those developed by existing methods, and (iii) the use of machine teaching substantially reduces the labeling cost. We will release our code and pre-trained models for reproducible research.
Conversation Learner -- A Machine Teaching Tool for Building Dialog Managers for Task-Oriented Dialog Systems
May 01, 2020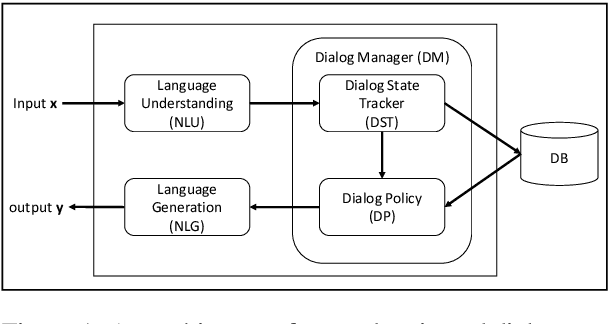

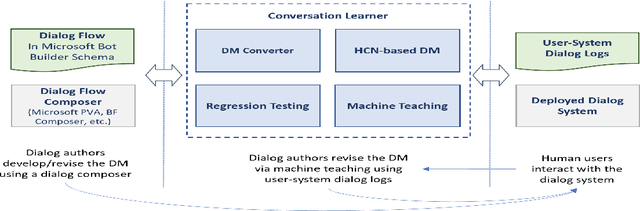
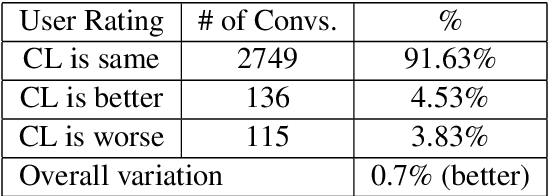
Traditionally, industry solutions for building a task-oriented dialog system have relied on helping dialog authors define rule-based dialog managers, represented as dialog flows. While dialog flows are intuitively interpretable and good for simple scenarios, they fall short of performance in terms of the flexibility needed to handle complex dialogs. On the other hand, purely machine-learned models can handle complex dialogs, but they are considered to be black boxes and require large amounts of training data. In this demonstration, we showcase Conversation Learner, a machine teaching tool for building dialog managers. It combines the best of both approaches by enabling dialog authors to create a dialog flow using familiar tools, converting the dialog flow into a parametric model (e.g., neural networks), and allowing dialog authors to improve the dialog manager (i.e., the parametric model) over time by leveraging user-system dialog logs as training data through a machine teaching interface.