 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailure-Aware RL: Reliable Offline-to-Online Reinforcement Learning with Self-Recovery for Real-World Manipulation
Jan 12, 2026Post-training algorithms based on deep reinforcement learning can push the limits of robotic models for specific objectives, such as generalizability, accuracy, and robustness. However, Intervention-requiring Failures (IR Failures) (e.g., a robot spilling water or breaking fragile glass) during real-world exploration happen inevitably, hindering the practical deployment of such a paradigm. To tackle this, we introduce Failure-Aware Offline-to-Online Reinforcement Learning (FARL), a new paradigm minimizing failures during real-world reinforcement learning. We create FailureBench, a benchmark that incorporates common failure scenarios requiring human intervention, and propose an algorithm that integrates a world-model-based safety critic and a recovery policy trained offline to prevent failures during online exploration. Extensive simulation and real-world experiments demonstrate the effectiveness of FARL in significantly reducing IR Failures while improving performance and generalization during online reinforcement learning post-training. FARL reduces IR Failures by 73.1% while elevating performance by 11.3% on average during real-world RL post-training. Videos and code are available at https://failure-aware-rl.github.io.
MomaGraph: State-Aware Unified Scene Graphs with Vision-Language Model for Embodied Task Planning
Dec 18, 2025Mobile manipulators in households must both navigate and manipulate. This requires a compact, semantically rich scene representation that captures where objects are, how they function, and which parts are actionable. Scene graphs are a natural choice, yet prior work often separates spatial and functional relations, treats scenes as static snapshots without object states or temporal updates, and overlooks information most relevant for accomplishing the current task. To address these limitations, we introduce MomaGraph, a unified scene representation for embodied agents that integrates spatial-functional relationships and part-level interactive elements. However, advancing such a representation requires both suitable data and rigorous evaluation, which have been largely missing. We thus contribute MomaGraph-Scenes, the first large-scale dataset of richly annotated, task-driven scene graphs in household environments, along with MomaGraph-Bench, a systematic evaluation suite spanning six reasoning capabilities from high-level planning to fine-grained scene understanding. Built upon this foundation, we further develop MomaGraph-R1, a 7B vision-language model trained with reinforcement learning on MomaGraph-Scenes. MomaGraph-R1 predicts task-oriented scene graphs and serves as a zero-shot task planner under a Graph-then-Plan framework. Extensive experiments demonstrate that our model achieves state-of-the-art results among open-source models, reaching 71.6% accuracy on the benchmark (+11.4% over the best baseline), while generalizing across public benchmarks and transferring effectively to real-robot experiments.
Lemon: A Unified and Scalable 3D Multimodal Model for Universal Spatial Understanding
Dec 14, 2025Scaling large multimodal models (LMMs) to 3D understanding poses unique challenges: point cloud data is sparse and irregular, existing models rely on fragmented architectures with modality-specific encoders, and training pipelines often suffer from instability and poor scalability. We introduce Lemon, a unified transformer architecture that addresses these challenges by jointly processing 3D point cloud patches and language tokens as a single sequence. Unlike prior work that relies on modality-specific encoders and cross-modal alignment modules, this design enables early spatial-linguistic fusion, eliminates redundant encoders, improves parameter efficiency, and supports more effective model scaling. To handle the complexity of 3D data, we develop a structured patchification and tokenization scheme that preserves spatial context, and a three-stage training curriculum that progressively builds capabilities from object-level recognition to scene-level spatial reasoning. Lemon establishes new state-of-the-art performance across comprehensive 3D understanding and reasoning tasks, from object recognition and captioning to spatial reasoning in 3D scenes, while demonstrating robust scaling properties as model size and training data increase. Our work provides a unified foundation for advancing 3D spatial intelligence in real-world applications.
WEAVE: Unleashing and Benchmarking the In-context Interleaved Comprehension and Generation
Nov 14, 2025
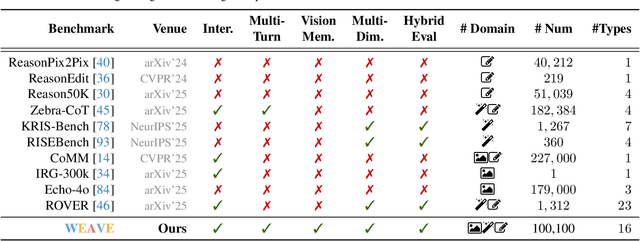
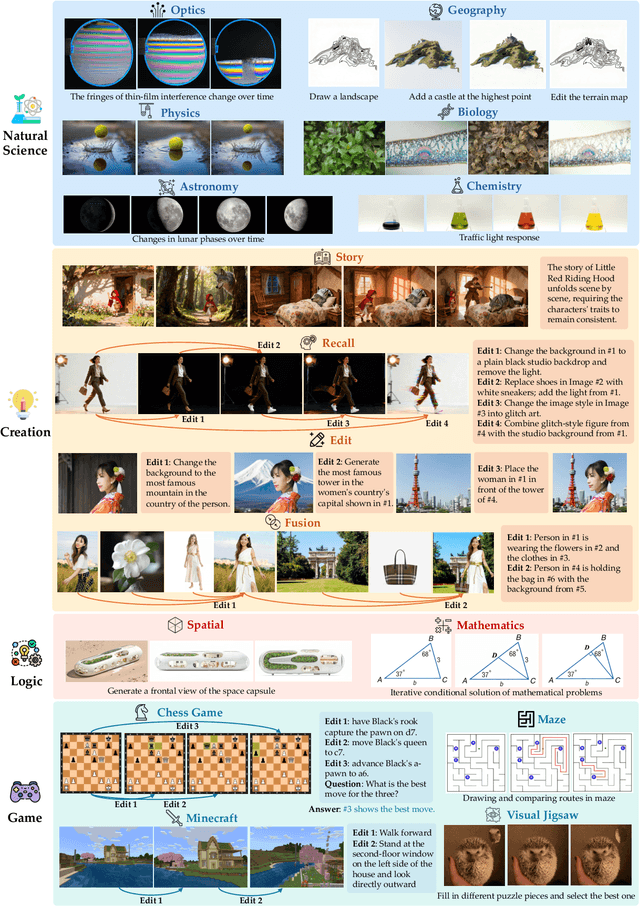

Recent advances in unified multimodal models (UMMs) have enabled impressive progress in visual comprehension and generation. However, existing datasets and benchmarks focus primarily on single-turn interactions, failing to capture the multi-turn, context-dependent nature of real-world image creation and editing. To address this gap, we present WEAVE, the first suite for in-context interleaved cross-modality comprehension and generation. Our suite consists of two complementary parts. WEAVE-100k is a large-scale dataset of 100K interleaved samples spanning over 370K dialogue turns and 500K images, covering comprehension, editing, and generation tasks that require reasoning over historical context. WEAVEBench is a human-annotated benchmark with 100 tasks based on 480 images, featuring a hybrid VLM judger evaluation framework based on both the reference image and the combination of the original image with editing instructions that assesses models' abilities in multi-turn generation, visual memory, and world-knowledge reasoning across diverse domains. Experiments demonstrate that training on WEAVE-100k enables vision comprehension, image editing, and comprehension-generation collaboration capabilities. Furthermore, it facilitates UMMs to develop emergent visual-memory capabilities, while extensive evaluations on WEAVEBench expose the persistent limitations and challenges of current approaches in multi-turn, context-aware image generation and editing. We believe WEAVE provides a view and foundation for studying in-context interleaved comprehension and generation for multi-modal community.
ViCrit: A Verifiable Reinforcement Learning Proxy Task for Visual Perception in VLMs
Jun 11, 2025Reinforcement learning (RL) has shown great effectiveness for fine-tuning large language models (LLMs) using tasks that are challenging yet easily verifiable, such as math reasoning or code generation. However, extending this success to visual perception in vision-language models (VLMs) has been impeded by the scarcity of vision-centric tasks that are simultaneously challenging and unambiguously verifiable. To this end, we introduce ViCrit (Visual Caption Hallucination Critic), an RL proxy task that trains VLMs to localize a subtle, synthetic visual hallucination injected into paragraphs of human-written image captions. Starting from a 200-word captions, we inject a single, subtle visual description error-altering a few words on objects, attributes, counts, or spatial relations-and task the model to pinpoint the corrupted span given the image and the modified caption. This formulation preserves the full perceptual difficulty while providing a binary, exact-match reward that is easy to compute and unambiguous. Models trained with the ViCrit Task exhibit substantial gains across a variety of VL benchmarks. Crucially, the improvements transfer beyond natural-image training data to abstract image reasoning and visual math, showing promises of learning to perceive rather than barely memorizing seen objects. To facilitate evaluation, we further introduce ViCrit-Bench, a category-balanced diagnostic benchmark that systematically probes perception errors across diverse image domains and error types. Together, our results demonstrate that fine-grained hallucination criticism is an effective and generalizable objective for enhancing visual perception in VLMs.
MORSE-500: A Programmatically Controllable Video Benchmark to Stress-Test Multimodal Reasoning
Jun 05, 2025Despite rapid advances in vision-language models (VLMs), current benchmarks for multimodal reasoning fall short in three key dimensions. First, they overwhelmingly rely on static images, failing to capture the temporal complexity of real-world environments. Second, they narrowly focus on mathematical problem-solving, neglecting the broader spectrum of reasoning skills -- including abstract, physical, planning, spatial, and temporal capabilities -- required for robust multimodal intelligence. Third, many benchmarks quickly saturate, offering limited headroom for diagnosing failure modes or measuring continued progress. We introduce MORSE-500 (Multimodal Reasoning Stress-test Environment), a video benchmark composed of 500 fully scripted clips with embedded questions spanning six complementary reasoning categories. Each instance is programmatically generated using deterministic Python scripts (via Manim, Matplotlib, MoviePy), generative video models, and curated real footage. This script-driven design allows fine-grained control over visual complexity, distractor density, and temporal dynamics -- enabling difficulty to be scaled systematically as models improve. Unlike static benchmarks that become obsolete once saturated, MORSE-500 is built to evolve: its controllable generation pipeline supports the creation of arbitrarily challenging new instances, making it ideally suited for stress-testing next-generation models. Initial experiments with state-of-the-art systems -- including various Gemini 2.5 Pro and OpenAI o3 which represent the strongest available at the time, alongside strong open-source models -- reveal substantial performance gaps across all categories, with particularly large deficits in abstract and planning tasks. We release the full dataset, generation scripts, and evaluation harness to support transparent, reproducible, and forward-looking multimodal reasoning research.
Magma: A Foundation Model for Multimodal AI Agents
Feb 18, 2025We present Magma, a foundation model that serves multimodal AI agentic tasks in both the digital and physical worlds. Magma is a significant extension of vision-language (VL) models in that it not only retains the VL understanding ability (verbal intelligence) of the latter, but is also equipped with the ability to plan and act in the visual-spatial world (spatial-temporal intelligence) and complete agentic tasks ranging from UI navigation to robot manipulation. To endow the agentic capabilities, Magma is pretrained on large amounts of heterogeneous datasets spanning from images, videos to robotics data, where the actionable visual objects (e.g., clickable buttons in GUI) in images are labeled by Set-of-Mark (SoM) for action grounding, and the object movements (e.g., the trace of human hands or robotic arms) in videos are labeled by Trace-of-Mark (ToM) for action planning. Extensive experiments show that SoM and ToM reach great synergy and facilitate the acquisition of spatial-temporal intelligence for our Magma model, which is fundamental to a wide range of tasks as shown in Fig.1. In particular, Magma creates new state-of-the-art results on UI navigation and robotic manipulation tasks, outperforming previous models that are specifically tailored to these tasks. On image and video-related multimodal tasks, Magma also compares favorably to popular large multimodal models that are trained on much larger datasets. We make our model and code public for reproducibility at https://microsoft.github.io/Magma.
TraceVLA: Visual Trace Prompting Enhances Spatial-Temporal Awareness for Generalist Robotic Policies
Dec 13, 2024Although large vision-language-action (VLA) models pretrained on extensive robot datasets offer promising generalist policies for robotic learning, they still struggle with spatial-temporal dynamics in interactive robotics, making them less effective in handling complex tasks, such as manipulation. In this work, we introduce visual trace prompting, a simple yet effective approach to facilitate VLA models' spatial-temporal awareness for action prediction by encoding state-action trajectories visually. We develop a new TraceVLA model by finetuning OpenVLA on our own collected dataset of 150K robot manipulation trajectories using visual trace prompting. Evaluations of TraceVLA across 137 configurations in SimplerEnv and 4 tasks on a physical WidowX robot demonstrate state-of-the-art performance, outperforming OpenVLA by 10% on SimplerEnv and 3.5x on real-robot tasks and exhibiting robust generalization across diverse embodiments and scenarios. To further validate the effectiveness and generality of our method, we present a compact VLA model based on 4B Phi-3-Vision, pretrained on the Open-X-Embodiment and finetuned on our dataset, rivals the 7B OpenVLA baseline while significantly improving inference efficiency.
Robots Pre-train Robots: Manipulation-Centric Robotic Representation from Large-Scale Robot Dataset
Oct 29, 2024The pre-training of visual representations has enhanced the efficiency of robot learning. Due to the lack of large-scale in-domain robotic datasets, prior works utilize in-the-wild human videos to pre-train robotic visual representation. Despite their promising results, representations from human videos are inevitably subject to distribution shifts and lack the dynamics information crucial for task completion. We first evaluate various pre-trained representations in terms of their correlation to the downstream robotic manipulation tasks (i.e., manipulation centricity). Interestingly, we find that the "manipulation centricity" is a strong indicator of success rates when applied to downstream tasks. Drawing from these findings, we propose Manipulation Centric Representation (MCR), a foundation representation learning framework capturing both visual features and the dynamics information such as actions and proprioceptions of manipulation tasks to improve manipulation centricity. Specifically, we pre-train a visual encoder on the DROID robotic dataset and leverage motion-relevant data such as robot proprioceptive states and actions. We introduce a novel contrastive loss that aligns visual observations with the robot's proprioceptive state-action dynamics, combined with a behavior cloning (BC)-like actor loss to predict actions during pre-training, along with a time contrastive loss. Empirical results across 4 simulation domains with 20 tasks verify that MCR outperforms the strongest baseline method by 14.8%. Moreover, MCR boosts the performance of data-efficient learning with a UR5e arm on 3 real-world tasks by 76.9%. Project website: https://robots-pretrain-robots.github.io/.
Make-An-Agent: A Generalizable Policy Network Generator with Behavior-Prompted Diffusion
Jul 15, 2024Can we generate a control policy for an agent using just one demonstration of desired behaviors as a prompt, as effortlessly as creating an image from a textual description? In this paper, we present Make-An-Agent, a novel policy parameter generator that leverages the power of conditional diffusion models for behavior-to-policy generation. Guided by behavior embeddings that encode trajectory information, our policy generator synthesizes latent parameter representations, which can then be decoded into policy networks. Trained on policy network checkpoints and their corresponding trajectories, our generation model demonstrates remarkable versatility and scalability on multiple tasks and has a strong generalization ability on unseen tasks to output well-performed policies with only few-shot demonstrations as inputs. We showcase its efficacy and efficiency on various domains and tasks, including varying objectives, behaviors, and even across different robot manipulators. Beyond simulation, we directly deploy policies generated by Make-An-Agent onto real-world robots on locomotion tasks.