 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Hand Latent Representation for Vision-Language-Action Models
Mar 10, 2026Dexterous manipulation is essential for real-world robot autonomy, mirroring the central role of human hand coordination in daily activity. Humans rely on rich multimodal perception--vision, sound, and language-guided intent--to perform dexterous actions, motivating vision-based, language-conditioned manipulation systems for robots. However, training reliable vision-language-action (VLA) models for dexterous manipulation requires large-scale demonstrations across many robotic hands. In addition, as new dexterous embodiments appear rapidly, collecting data for each becomes costly and impractical, creating a need for scalable cross-embodiment learning. We introduce XL-VLA, a vision-language-action framework integrated with a unified latent action space shared across diverse dexterous hands. This embodiment-invariant latent space is directly pluggable into standard VLA architectures, enabling seamless cross-embodiment training and efficient reuse of both existing and newly collected data. Experimental results demonstrate that XL-VLA consistently outperforms baseline VLA models operating in raw joint spaces, establishing it as an effective solution for scalable cross-embodiment dexterous manipulation.
From Power to Precision: Learning Fine-grained Dexterity for Multi-fingered Robotic Hands
Nov 17, 2025



Human grasps can be roughly categorized into two types: power grasps and precision grasps. Precision grasping enables tool use and is believed to have influenced human evolution. Today's multi-fingered robotic hands are effective in power grasps, but for tasks requiring precision, parallel grippers are still more widely adopted. This contrast highlights a key limitation in current robotic hand design: the difficulty of achieving both stable power grasps and precise, fine-grained manipulation within a single, versatile system. In this work, we bridge this gap by jointly optimizing the control and hardware design of a multi-fingered dexterous hand, enabling both power and precision manipulation. Rather than redesigning the entire hand, we introduce a lightweight fingertip geometry modification, represent it as a contact plane, and jointly optimize its parameters along with the corresponding control. Our control strategy dynamically switches between power and precision manipulation and simplifies precision control into parallel thumb-index motions, which proves robust for sim-to-real transfer. On the design side, we leverage large-scale simulation to optimize the fingertip geometry using a differentiable neural-physics surrogate model. We validate our approach through extensive experiments in both sim-to-real and real-to-real settings. Our method achieves an 82.5% zero-shot success rate on unseen objects in sim-to-real precision grasping, and a 93.3% success rate in challenging real-world tasks involving bread pinching. These results demonstrate that our co-design framework can significantly enhance the fine-grained manipulation ability of multi-fingered hands without reducing their ability for power grasps. Our project page is at https://jianglongye.com/power-to-precision
GSWorld: Closed-Loop Photo-Realistic Simulation Suite for Robotic Manipulation
Oct 23, 2025This paper presents GSWorld, a robust, photo-realistic simulator for robotics manipulation that combines 3D Gaussian Splatting with physics engines. Our framework advocates "closing the loop" of developing manipulation policies with reproducible evaluation of policies learned from real-robot data and sim2real policy training without using real robots. To enable photo-realistic rendering of diverse scenes, we propose a new asset format, which we term GSDF (Gaussian Scene Description File), that infuses Gaussian-on-Mesh representation with robot URDF and other objects. With a streamlined reconstruction pipeline, we curate a database of GSDF that contains 3 robot embodiments for single-arm and bimanual manipulation, as well as more than 40 objects. Combining GSDF with physics engines, we demonstrate several immediate interesting applications: (1) learning zero-shot sim2real pixel-to-action manipulation policy with photo-realistic rendering, (2) automated high-quality DAgger data collection for adapting policies to deployment environments, (3) reproducible benchmarking of real-robot manipulation policies in simulation, (4) simulation data collection by virtual teleoperation, and (5) zero-shot sim2real visual reinforcement learning. Website: https://3dgsworld.github.io/.
Robots Pre-train Robots: Manipulation-Centric Robotic Representation from Large-Scale Robot Dataset
Oct 29, 2024The pre-training of visual representations has enhanced the efficiency of robot learning. Due to the lack of large-scale in-domain robotic datasets, prior works utilize in-the-wild human videos to pre-train robotic visual representation. Despite their promising results, representations from human videos are inevitably subject to distribution shifts and lack the dynamics information crucial for task completion. We first evaluate various pre-trained representations in terms of their correlation to the downstream robotic manipulation tasks (i.e., manipulation centricity). Interestingly, we find that the "manipulation centricity" is a strong indicator of success rates when applied to downstream tasks. Drawing from these findings, we propose Manipulation Centric Representation (MCR), a foundation representation learning framework capturing both visual features and the dynamics information such as actions and proprioceptions of manipulation tasks to improve manipulation centricity. Specifically, we pre-train a visual encoder on the DROID robotic dataset and leverage motion-relevant data such as robot proprioceptive states and actions. We introduce a novel contrastive loss that aligns visual observations with the robot's proprioceptive state-action dynamics, combined with a behavior cloning (BC)-like actor loss to predict actions during pre-training, along with a time contrastive loss. Empirical results across 4 simulation domains with 20 tasks verify that MCR outperforms the strongest baseline method by 14.8%. Moreover, MCR boosts the performance of data-efficient learning with a UR5e arm on 3 real-world tasks by 76.9%. Project website: https://robots-pretrain-robots.github.io/.
Make-An-Agent: A Generalizable Policy Network Generator with Behavior-Prompted Diffusion
Jul 15, 2024Can we generate a control policy for an agent using just one demonstration of desired behaviors as a prompt, as effortlessly as creating an image from a textual description? In this paper, we present Make-An-Agent, a novel policy parameter generator that leverages the power of conditional diffusion models for behavior-to-policy generation. Guided by behavior embeddings that encode trajectory information, our policy generator synthesizes latent parameter representations, which can then be decoded into policy networks. Trained on policy network checkpoints and their corresponding trajectories, our generation model demonstrates remarkable versatility and scalability on multiple tasks and has a strong generalization ability on unseen tasks to output well-performed policies with only few-shot demonstrations as inputs. We showcase its efficacy and efficiency on various domains and tasks, including varying objectives, behaviors, and even across different robot manipulators. Beyond simulation, we directly deploy policies generated by Make-An-Agent onto real-world robots on locomotion tasks.
RoboDuet: A Framework Affording Mobile-Manipulation and Cross-Embodiment
Mar 27, 2024
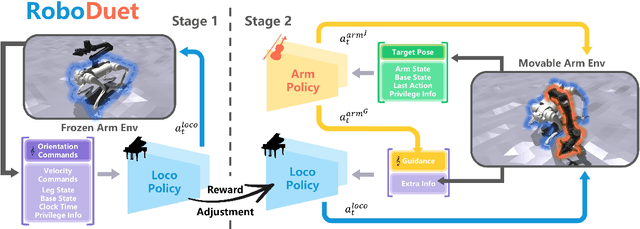
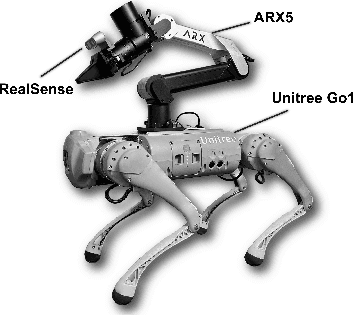
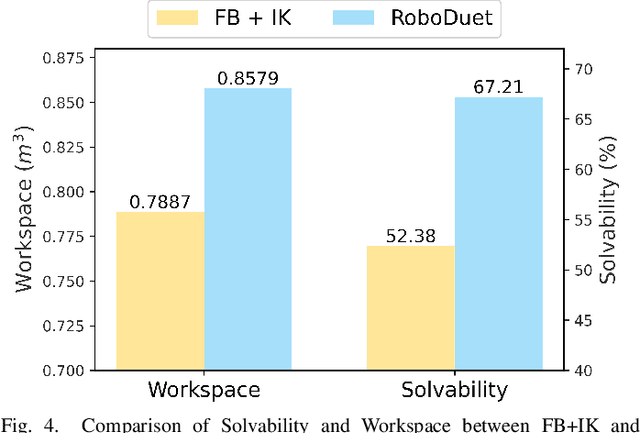
Combining the mobility of legged robots with the manipulation skills of arms has the potential to significantly expand the operational range and enhance the capabilities of robotic systems in performing various mobile manipulation tasks. Existing approaches are confined to imprecise six degrees of freedom (DoF) manipulation and possess a limited arm workspace. In this paper, we propose a novel framework, RoboDuet, which employs two collaborative policies to realize locomotion and manipulation simultaneously, achieving whole-body control through interactions between each other. Surprisingly, going beyond the large-range pose tracking, we find that the two-policy framework may enable cross-embodiment deployment such as using different quadrupedal robots or other arms. Our experiments demonstrate that the policies trained through RoboDuet can accomplish stable gaits, agile 6D end-effector pose tracking, and zero-shot exchange of legged robots, and can be deployed in the real world to perform various mobile manipulation tasks. Our project page with demo videos is at https://locomanip-duet.github.io .
Diffusion Reward: Learning Rewards via Conditional Video Diffusion
Dec 21, 2023
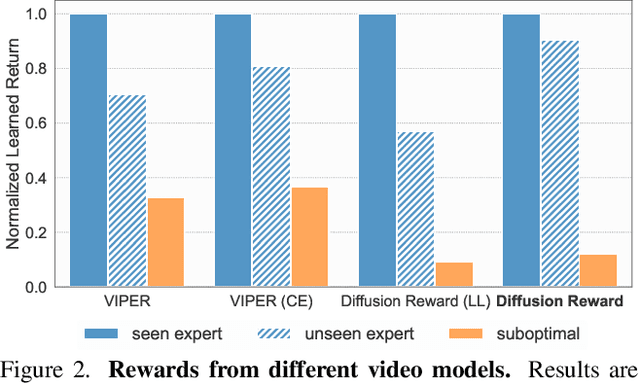
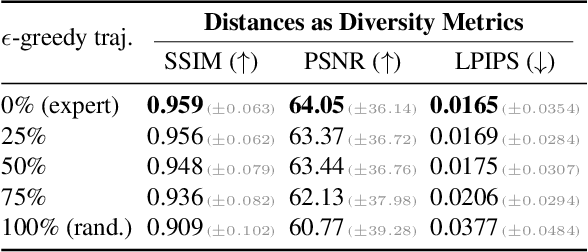
Learning rewards from expert videos offers an affordable and effective solution to specify the intended behaviors for reinforcement learning tasks. In this work, we propose Diffusion Reward, a novel framework that learns rewards from expert videos via conditional video diffusion models for solving complex visual RL problems. Our key insight is that lower generative diversity is observed when conditioned on expert trajectories. Diffusion Reward is accordingly formalized by the negative of conditional entropy that encourages productive exploration of expert-like behaviors. We show the efficacy of our method over 10 robotic manipulation tasks from MetaWorld and Adroit with visual input and sparse reward. Moreover, Diffusion Reward could even solve unseen tasks successfully and effectively, largely surpassing baseline methods. Project page and code: https://diffusion-reward.github.io/.
Graph-Collaborated Auto-Encoder Hashing for Multi-view Binary Clustering
Jan 06, 2023Unsupervised hashing methods have attracted widespread attention with the explosive growth of large-scale data, which can greatly reduce storage and computation by learning compact binary codes. Existing unsupervised hashing methods attempt to exploit the valuable information from samples, which fails to take the local geometric structure of unlabeled samples into consideration. Moreover, hashing based on auto-encoders aims to minimize the reconstruction loss between the input data and binary codes, which ignores the potential consistency and complementarity of multiple sources data. To address the above issues, we propose a hashing algorithm based on auto-encoders for multi-view binary clustering, which dynamically learns affinity graphs with low-rank constraints and adopts collaboratively learning between auto-encoders and affinity graphs to learn a unified binary code, called Graph-Collaborated Auto-Encoder Hashing for Multi-view Binary Clustering (GCAE). Specifically, we propose a multi-view affinity graphs learning model with low-rank constraint, which can mine the underlying geometric information from multi-view data. Then, we design an encoder-decoder paradigm to collaborate the multiple affinity graphs, which can learn a unified binary code effectively. Notably, we impose the decorrelation and code balance constraints on binary codes to reduce the quantization errors. Finally, we utilize an alternating iterative optimization scheme to obtain the multi-view clustering results. Extensive experimental results on $5$ public datasets are provided to reveal the effectiveness of the algorithm and its superior performance over other state-of-the-art alternatives.
Discriminative Feature and Dictionary Learning with Part-aware Model for Vehicle Re-identification
Mar 16, 2020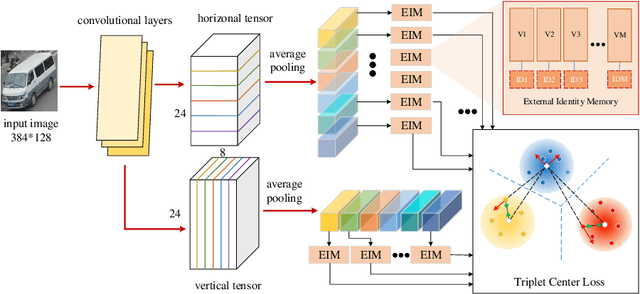
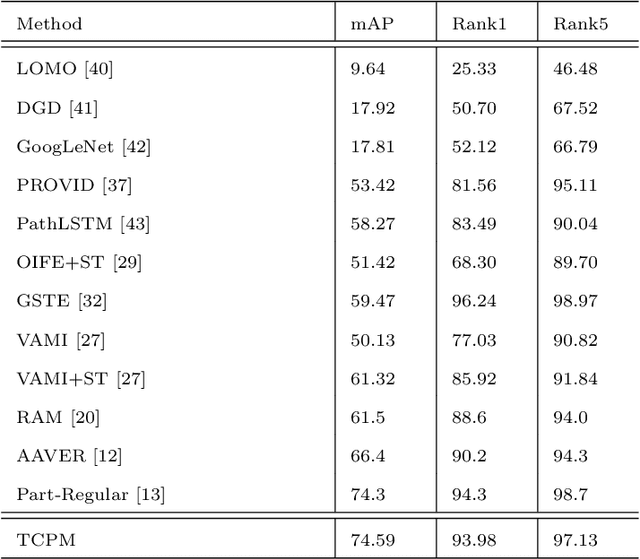
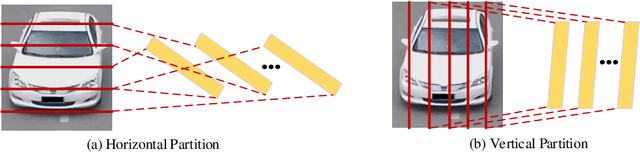
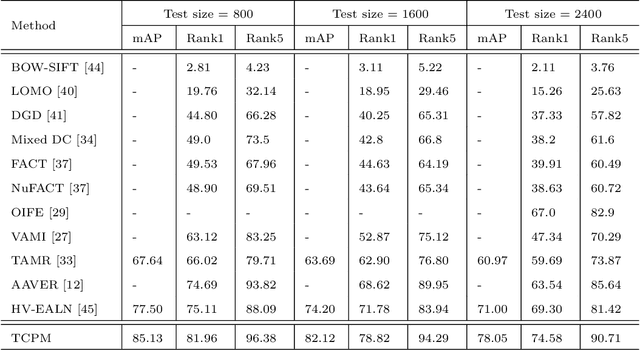
With the development of smart cities, urban surveillance video analysis will play a further significant role in intelligent transportation systems. Identifying the same target vehicle in large datasets from non-overlapping cameras should be highlighted, which has grown into a hot topic in promoting intelligent transportation systems. However, vehicle re-identification (re-ID) technology is a challenging task since vehicles of the same design or manufacturer show similar appearance. To fill these gaps, we tackle this challenge by proposing Triplet Center Loss based Part-aware Model (TCPM) that leverages the discriminative features in part details of vehicles to refine the accuracy of vehicle re-identification. TCPM base on part discovery is that partitions the vehicle from horizontal and vertical directions to strengthen the details of the vehicle and reinforce the internal consistency of the parts. In addition, to eliminate intra-class differences in local regions of the vehicle, we propose external memory modules to emphasize the consistency of each part to learn the discriminating features, which forms a global dictionary over all categories in dataset. In TCPM, triplet-center loss is introduced to ensure each part of vehicle features extracted has intra-class consistency and inter-class separability. Experimental results show that our proposed TCPM has an enormous preference over the existing state-of-the-art methods on benchmark datasets VehicleID and VeRi-776.
Attribute-guided Feature Learning Network for Vehicle Re-identification
Jan 12, 2020
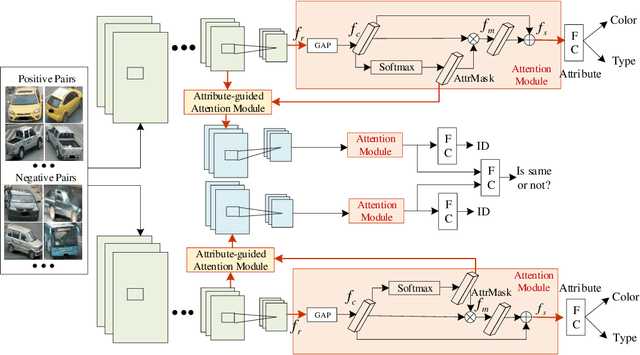
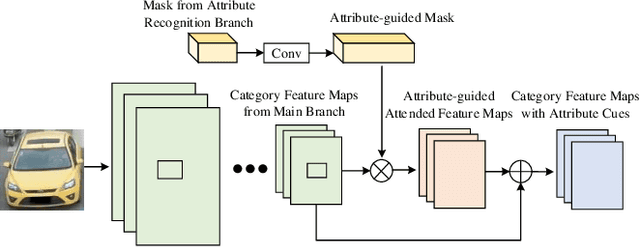

Vehicle re-identification (reID) plays an important role in the automatic analysis of the increasing urban surveillance videos, which has become a hot topic in recent years. However, it poses the critical but challenging problem that is caused by various viewpoints of vehicles, diversified illuminations and complicated environments. Till now, most existing vehicle reID approaches focus on learning metrics or ensemble to derive better representation, which are only take identity labels of vehicle into consideration. However, the attributes of vehicle that contain detailed descriptions are beneficial for training reID model. Hence, this paper proposes a novel Attribute-Guided Network (AGNet), which could learn global representation with the abundant attribute features in an end-to-end manner. Specially, an attribute-guided module is proposed in AGNet to generate the attribute mask which could inversely guide to select discriminative features for category classification. Besides that, in our proposed AGNet, an attribute-based label smoothing (ALS) loss is presented to better train the reID model, which can strength the distinct ability of vehicle reID model to regularize AGNet model according to the attributes. Comprehensive experimental results clearly demonstrate that our method achieves excellent performance on both VehicleID dataset and VeRi-776 dataset.