 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-guided Feature Learning Network for Vehicle Re-identification
Jan 12, 2020
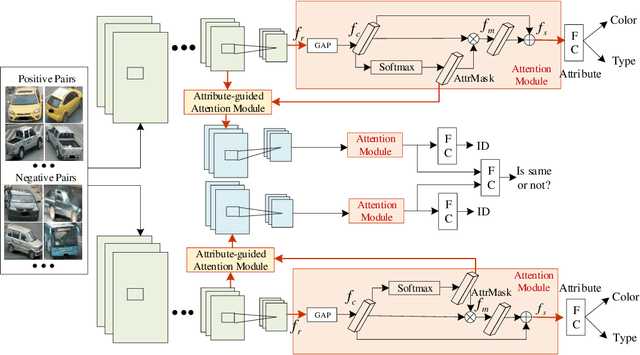
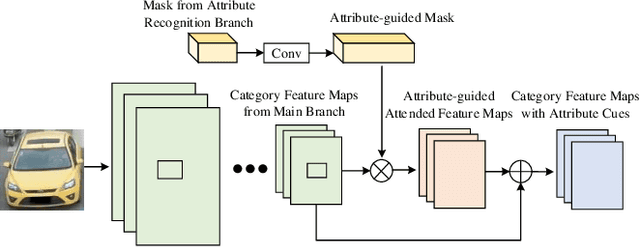

Vehicle re-identification (reID) plays an important role in the automatic analysis of the increasing urban surveillance videos, which has become a hot topic in recent years. However, it poses the critical but challenging problem that is caused by various viewpoints of vehicles, diversified illuminations and complicated environments. Till now, most existing vehicle reID approaches focus on learning metrics or ensemble to derive better representation, which are only take identity labels of vehicle into consideration. However, the attributes of vehicle that contain detailed descriptions are beneficial for training reID model. Hence, this paper proposes a novel Attribute-Guided Network (AGNet), which could learn global representation with the abundant attribute features in an end-to-end manner. Specially, an attribute-guided module is proposed in AGNet to generate the attribute mask which could inversely guide to select discriminative features for category classification. Besides that, in our proposed AGNet, an attribute-based label smoothing (ALS) loss is presented to better train the reID model, which can strength the distinct ability of vehicle reID model to regularize AGNet model according to the attributes. Comprehensive experimental results clearly demonstrate that our method achieves excellent performance on both VehicleID dataset and VeRi-776 dataset.
Eliminating cross-camera bias for vehicle re-identification
Dec 21, 2019
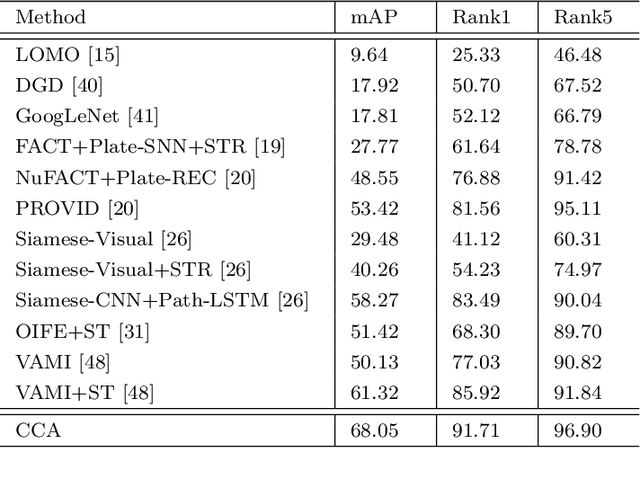
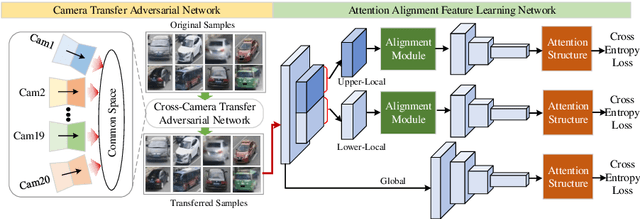
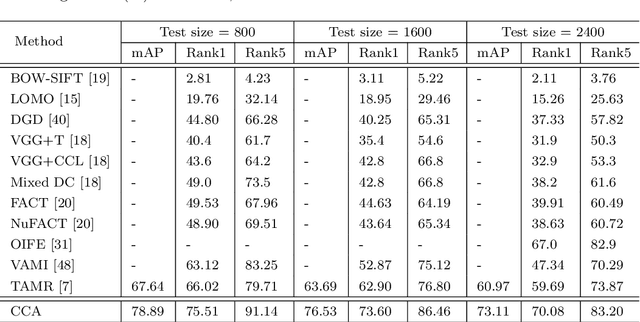
Vehicle re-identification (reID) often requires recognize a target vehicle in large datasets captured from multi-cameras. It plays an important role in the automatic analysis of the increasing urban surveillance videos, which has become a hot topic in recent years. However, the appearance of vehicle images is easily affected by the environment that various illuminations, different backgrounds and viewpoints, which leads to the large bias between different cameras. To address this problem, this paper proposes a cross-camera adaptation framework (CCA), which smooths the bias by exploiting the common space between cameras for all samples. CCA first transfers images from multi-cameras into one camera to reduce the impact of the illumination and resolution, which generates the samples with the similar distribution. Then, to eliminate the influence of background and focus on the valuable parts, we propose an attention alignment network (AANet) to learn powerful features for vehicle reID. Specially, in AANet, the spatial transfer network with attention module is introduced to locate a series of the most discriminative regions with high-attention weights and suppress the background. Moreover, comprehensive experimental results have demonstrated that our proposed CCA can achieve excellent performances on benchmark datasets VehicleID and VeRi-776.
Graph-based Multi-view Binary Learning for Image Clustering
Dec 11, 2019
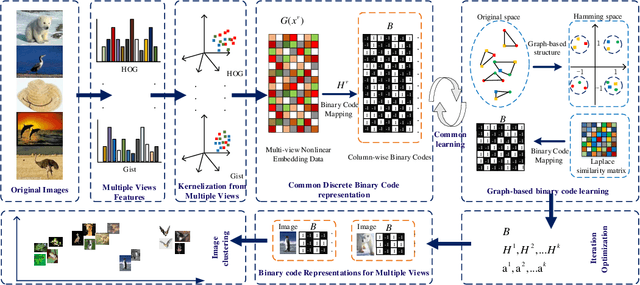


Hashing techniques, also known as binary code learning, have recently gained increasing attention in large-scale data analysis and storage. Generally, most existing hash clustering methods are single-view ones, which lack complete structure or complementary information from multiple views. For cluster tasks, abundant prior researches mainly focus on learning discrete hash code while few works take original data structure into consideration. To address these problems, we propose a novel binary code algorithm for clustering, which adopts graph embedding to preserve the original data structure, called (Graph-based Multi-view Binary Learning) GMBL in this paper. GMBL mainly focuses on encoding the information of multiple views into a compact binary code, which explores complementary information from multiple views. In particular, in order to maintain the graph-based structure of the original data, we adopt a Laplacian matrix to preserve the local linear relationship of the data and map it to the Hamming space. Considering different views have distinctive contributions to the final clustering results, GMBL adopts a strategy of automatically assign weights for each view to better guide the clustering. Finally, An alternating iterative optimization method is adopted to optimize discrete binary codes directly instead of relaxing the binary constraint in two steps. Experiments on five public datasets demonstrate the superiority of our proposed method compared with previous approaches in terms of clustering performance.