 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor Learning with Potential Cluster Constraints for Multi-view Clustering
Dec 21, 2024



Anchor-based multi-view clustering (MVC) has received extensive attention due to its efficient performance. Existing methods only focus on how to dynamically learn anchors from the original data and simultaneously construct anchor graphs describing the relationships between samples and perform clustering, while ignoring the reality of anchors, i.e., high-quality anchors should be generated uniformly from different clusters of data rather than scattered outside the clusters. To deal with this problem, we propose a noval method termed Anchor Learning with Potential Cluster Constraints for Multi-view Clustering (ALPC) method. Specifically, ALPC first establishes a shared latent semantic module to constrain anchors to be generated from specific clusters, and subsequently, ALPC improves the representativeness and discriminability of anchors by adapting the anchor graph to capture the common clustering center of mass from samples and anchors, respectively. Finally, ALPC combines anchor learning and graph construction into a unified framework for collaborative learning and mutual optimization to improve the clustering performance. Extensive experiments demonstrate the effectiveness of our proposed method compared to some state-of-the-art MVC methods. Our source code is available at https://github.com/whbdmu/ALPC.
Unsupervised Domain Adaptive Person Search via Dual Self-Calibration
Dec 21, 2024



Unsupervised Domain Adaptive (UDA) person search focuses on employing the model trained on a labeled source domain dataset to a target domain dataset without any additional annotations. Most effective UDA person search methods typically utilize the ground truth of the source domain and pseudo-labels derived from clustering during the training process for domain adaptation. However, the performance of these approaches will be significantly restricted by the disrupting pseudo-labels resulting from inter-domain disparities. In this paper, we propose a Dual Self-Calibration (DSCA) framework for UDA person search that effectively eliminates the interference of noisy pseudo-labels by considering both the image-level and instance-level features perspectives. Specifically, we first present a simple yet effective Perception-Driven Adaptive Filter (PDAF) to adaptively predict a dynamic filter threshold based on input features. This threshold assists in eliminating noisy pseudo-boxes and other background interference, allowing our approach to focus on foreground targets and avoid indiscriminate domain adaptation. Besides, we further propose a Cluster Proxy Representation (CPR) module to enhance the update strategy of cluster representation, which mitigates the pollution of clusters from misidentified instances and effectively streamlines the training process for unlabeled target domains. With the above design, our method can achieve state-of-the-art (SOTA) performance on two benchmark datasets, with 80.2% mAP and 81.7% top-1 on the CUHK-SYSU dataset, with 39.9% mAP and 81.6% top-1 on the PRW dataset, which is comparable to or even exceeds the performance of some fully supervised methods. Our source code is available at https://github.com/whbdmu/DSCA.
Manifold-based Incomplete Multi-view Clustering via Bi-Consistency Guidance
May 16, 2024



Incomplete multi-view clustering primarily focuses on dividing unlabeled data into corresponding categories with missing instances, and has received intensive attention due to its superiority in real applications. Considering the influence of incomplete data, the existing methods mostly attempt to recover data by adding extra terms. However, for the unsupervised methods, a simple recovery strategy will cause errors and outlying value accumulations, which will affect the performance of the methods. Broadly, the previous methods have not taken the effectiveness of recovered instances into consideration, or cannot flexibly balance the discrepancies between recovered data and original data. To address these problems, we propose a novel method termed Manifold-based Incomplete Multi-view clustering via Bi-consistency guidance (MIMB), which flexibly recovers incomplete data among various views, and attempts to achieve biconsistency guidance via reverse regularization. In particular, MIMB adds reconstruction terms to representation learning by recovering missing instances, which dynamically examines the latent consensus representation. Moreover, to preserve the consistency information among multiple views, MIMB implements a biconsistency guidance strategy with reverse regularization of the consensus representation and proposes a manifold embedding measure for exploring the hidden structure of the recovered data. Notably, MIMB aims to balance the importance of different views, and introduces an adaptive weight term for each view. Finally, an optimization algorithm with an alternating iteration optimization strategy is designed for final clustering. Extensive experimental results on 6 benchmark datasets are provided to confirm that MIMB can significantly obtain superior results as compared with several state-of-the-art baselines.
Fast One-Stage Unsupervised Domain Adaptive Person Search
May 05, 2024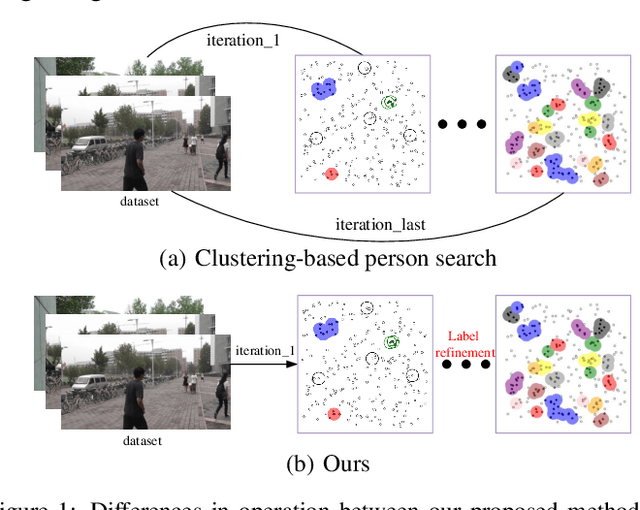

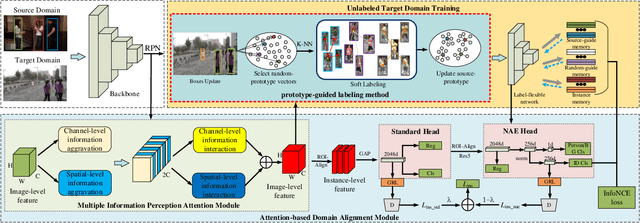
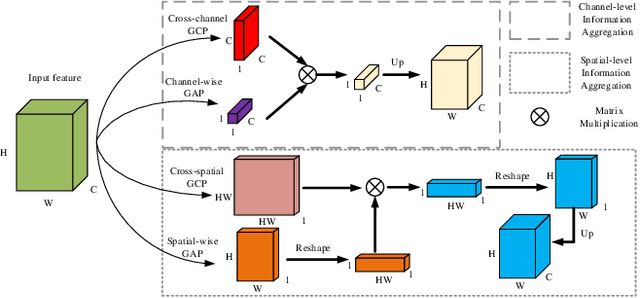
Unsupervised person search aims to localize a particular target person from a gallery set of scene images without annotations, which is extremely challenging due to the unexpected variations of the unlabeled domains. However, most existing methods dedicate to developing multi-stage models to adapt domain variations while using clustering for iterative model training, which inevitably increases model complexity. To address this issue, we propose a Fast One-stage Unsupervised person Search (FOUS) which complementary integrates domain adaptaion with label adaptaion within an end-to-end manner without iterative clustering. To minimize the domain discrepancy, FOUS introduced an Attention-based Domain Alignment Module (ADAM) which can not only align various domains for both detection and ReID tasks but also construct an attention mechanism to reduce the adverse impacts of low-quality candidates resulting from unsupervised detection. Moreover, to avoid the redundant iterative clustering mode, FOUS adopts a prototype-guided labeling method which minimizes redundant correlation computations for partial samples and assigns noisy coarse label groups efficiently. The coarse label groups will be continuously refined via label-flexible training network with an adaptive selection strategy. With the adapted domains and labels, FOUS can achieve the state-of-the-art (SOTA) performance on two benchmark datasets, CUHK-SYSU and PRW. The code is available at https://github.com/whbdmu/FOUS.
Scene-Adaptive Person Search via Bilateral Modulations
May 05, 2024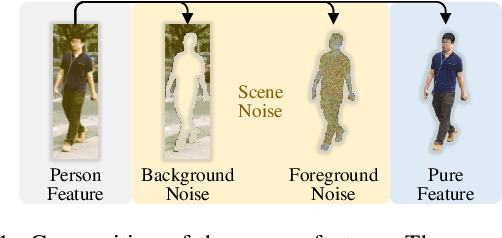
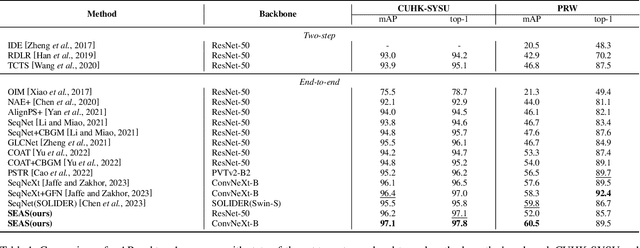
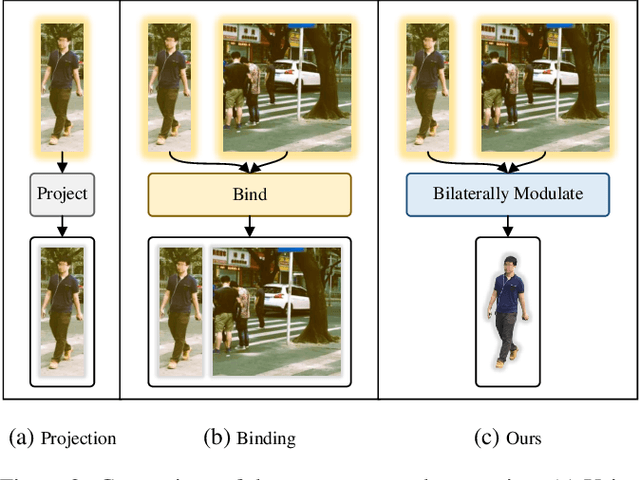

Person search aims to localize specific a target person from a gallery set of images with various scenes. As the scene of moving pedestrian changes, the captured person image inevitably bring in lots of background noise and foreground noise on the person feature, which are completely unrelated to the person identity, leading to severe performance degeneration. To address this issue, we present a Scene-Adaptive Person Search (SEAS) model by introducing bilateral modulations to simultaneously eliminate scene noise and maintain a consistent person representation to adapt to various scenes. In SEAS, a Background Modulation Network (BMN) is designed to encode the feature extracted from the detected bounding box into a multi-granularity embedding, which reduces the input of background noise from multiple levels with norm-aware. Additionally, to mitigate the effect of foreground noise on the person feature, SEAS introduces a Foreground Modulation Network (FMN) to compute the clutter reduction offset for the person embedding based on the feature map of the scene image. By bilateral modulations on both background and foreground within an end-to-end manner, SEAS obtains consistent feature representations without scene noise. SEAS can achieve state-of-the-art (SOTA) performance on two benchmark datasets, CUHK-SYSU with 97.1\% mAP and PRW with 60.5\% mAP. The code is available at https://github.com/whbdmu/SEAS.
Domain Adaptive Person Search via GAN-based Scene Synthesis for Cross-scene Videos
Aug 08, 2023



Person search has recently been a challenging task in the computer vision domain, which aims to search specific pedestrians from real cameras.Nevertheless, most surveillance videos comprise only a handful of images of each pedestrian, which often feature identical backgrounds and clothing. Hence, it is difficult to learn more discriminative features for person search in real scenes. To tackle this challenge, we draw on Generative Adversarial Networks (GAN) to synthesize data from surveillance videos. GAN has thrived in computer vision problems because it produces high-quality images efficiently. We merely alter the popular Fast R-CNN model, which is capable of processing videos and yielding accurate detection outcomes. In order to appropriately relieve the pressure brought by the two-stage model, we design an Assisted-Identity Query Module (AIDQ) to provide positive images for the behind part. Besides, the proposed novel GAN-based Scene Synthesis model that can synthesize high-quality cross-id person images for person search tasks. In order to facilitate the feature learning of the GAN-based Scene Synthesis model, we adopt an online learning strategy that collaboratively learns the synthesized images and original images. Extensive experiments on two widely used person search benchmarks, CUHK-SYSU and PRW, have shown that our method has achieved great performance, and the extensive ablation study further justifies our GAN-synthetic data can effectively increase the variability of the datasets and be more realistic.
Graph-Collaborated Auto-Encoder Hashing for Multi-view Binary Clustering
Jan 06, 2023Unsupervised hashing methods have attracted widespread attention with the explosive growth of large-scale data, which can greatly reduce storage and computation by learning compact binary codes. Existing unsupervised hashing methods attempt to exploit the valuable information from samples, which fails to take the local geometric structure of unlabeled samples into consideration. Moreover, hashing based on auto-encoders aims to minimize the reconstruction loss between the input data and binary codes, which ignores the potential consistency and complementarity of multiple sources data. To address the above issues, we propose a hashing algorithm based on auto-encoders for multi-view binary clustering, which dynamically learns affinity graphs with low-rank constraints and adopts collaboratively learning between auto-encoders and affinity graphs to learn a unified binary code, called Graph-Collaborated Auto-Encoder Hashing for Multi-view Binary Clustering (GCAE). Specifically, we propose a multi-view affinity graphs learning model with low-rank constraint, which can mine the underlying geometric information from multi-view data. Then, we design an encoder-decoder paradigm to collaborate the multiple affinity graphs, which can learn a unified binary code effectively. Notably, we impose the decorrelation and code balance constraints on binary codes to reduce the quantization errors. Finally, we utilize an alternating iterative optimization scheme to obtain the multi-view clustering results. Extensive experimental results on $5$ public datasets are provided to reveal the effectiveness of the algorithm and its superior performance over other state-of-the-art alternatives.
Unsupervised Vehicle Re-identification with Progressive Adaptation
Jun 20, 2020

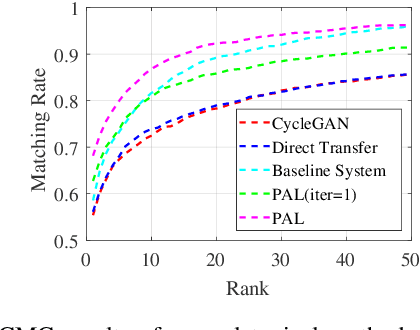

Vehicle re-identification (reID) aims at identifying vehicles across different non-overlapping cameras views. The existing methods heavily relied on well-labeled datasets for ideal performance, which inevitably causes fateful drop due to the severe domain bias between the training domain and the real-world scenes; worse still, these approaches required full annotations, which is labor-consuming. To tackle these challenges, we propose a novel progressive adaptation learning method for vehicle reID, named PAL, which infers from the abundant data without annotations. For PAL, a data adaptation module is employed for source domain, which generates the images with similar data distribution to unlabeled target domain as ``pseudo target samples''. These pseudo samples are combined with the unlabeled samples that are selected by a dynamic sampling strategy to make training faster. We further proposed a weighted label smoothing (WLS) loss, which considers the similarity between samples with different clusters to balance the confidence of pseudo labels. Comprehensive experimental results validate the advantages of PAL on both VehicleID and VeRi-776 dataset.
Multi-view Low-rank Preserving Embedding: A Novel Method for Multi-view Representation
Jun 14, 2020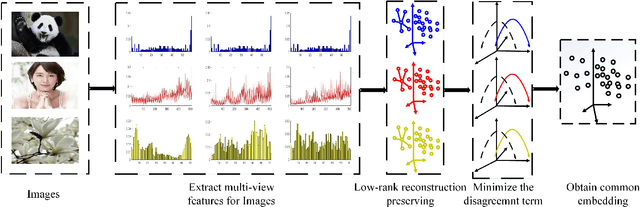
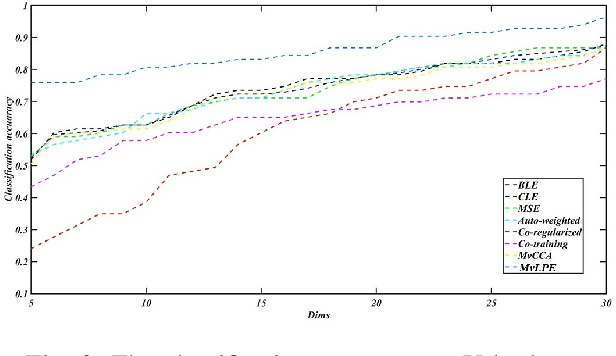
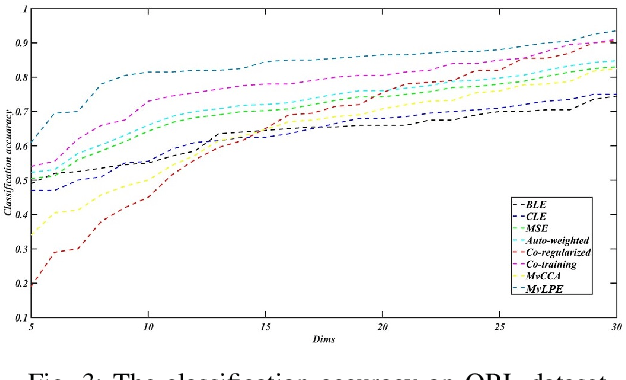
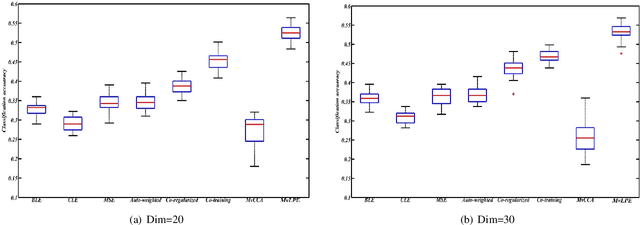
In recent years, we have witnessed a surge of interest in multi-view representation learning, which is concerned with the problem of learning representations of multi-view data. When facing multiple views that are highly related but sightly different from each other, most of existing multi-view methods might fail to fully integrate multi-view information. Besides, correlations between features from multiple views always vary seriously, which makes multi-view representation challenging. Therefore, how to learn appropriate embedding from multi-view information is still an open problem but challenging. To handle this issue, this paper proposes a novel multi-view learning method, named Multi-view Low-rank Preserving Embedding (MvLPE). It integrates different views into one centroid view by minimizing the disagreement term, based on distance or similarity matrix among instances, between the centroid view and each view meanwhile maintaining low-rank reconstruction relations among samples for each view, which could make more full use of compatible and complementary information from multi-view features. Unlike existing methods with additive parameters, the proposed method could automatically allocate a suitable weight for each view in multi-view information fusion. However, MvLPE couldn't be directly solved, which makes the proposed MvLPE difficult to obtain an analytic solution. To this end, we approximate this solution based on stationary hypothesis and normalization post-processing to efficiently obtain the optimal solution. Furthermore, an iterative alternating strategy is provided to solve this multi-view representation problem. The experiments on six benchmark datasets demonstrate that the proposed method outperforms its counterparts while achieving very competitive performance.
NTIRE 2020 Challenge on Real-World Image Super-Resolution: Methods and Results
May 05, 2020
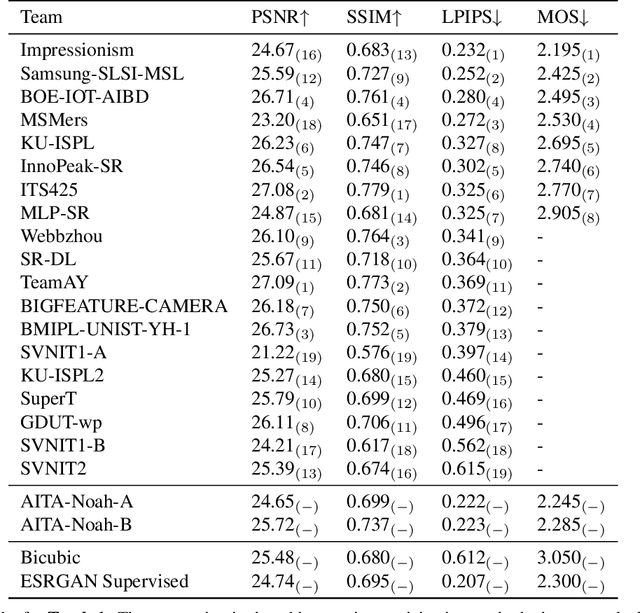
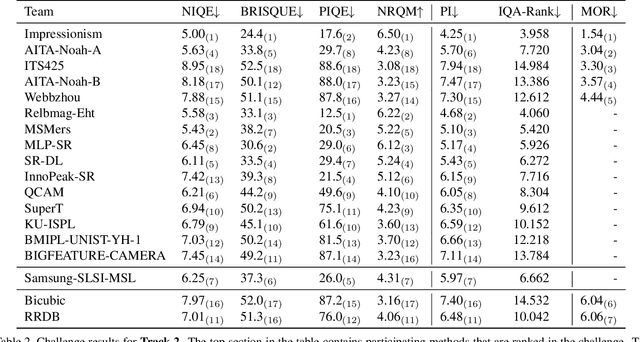

This paper reviews the NTIRE 2020 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided along with a set of unpaired high-quality target images. In Track 1: Image Processing artifacts, the aim is to super-resolve images with synthetically generated image processing artifacts. This allows for quantitative benchmarking of the approaches \wrt a ground-truth image. In Track 2: Smartphone Images, real low-quality smart phone images have to be super-resolved. In both tracks, the ultimate goal is to achieve the best perceptual quality, evaluated using a human study. This is the second challenge on the subject, following AIM 2019, targeting to advance the state-of-the-art in super-resolution. To measure the performance we use the benchmark protocol from AIM 2019. In total 22 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.