 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Collaborated Auto-Encoder Hashing for Multi-view Binary Clustering
Jan 06, 2023Unsupervised hashing methods have attracted widespread attention with the explosive growth of large-scale data, which can greatly reduce storage and computation by learning compact binary codes. Existing unsupervised hashing methods attempt to exploit the valuable information from samples, which fails to take the local geometric structure of unlabeled samples into consideration. Moreover, hashing based on auto-encoders aims to minimize the reconstruction loss between the input data and binary codes, which ignores the potential consistency and complementarity of multiple sources data. To address the above issues, we propose a hashing algorithm based on auto-encoders for multi-view binary clustering, which dynamically learns affinity graphs with low-rank constraints and adopts collaboratively learning between auto-encoders and affinity graphs to learn a unified binary code, called Graph-Collaborated Auto-Encoder Hashing for Multi-view Binary Clustering (GCAE). Specifically, we propose a multi-view affinity graphs learning model with low-rank constraint, which can mine the underlying geometric information from multi-view data. Then, we design an encoder-decoder paradigm to collaborate the multiple affinity graphs, which can learn a unified binary code effectively. Notably, we impose the decorrelation and code balance constraints on binary codes to reduce the quantization errors. Finally, we utilize an alternating iterative optimization scheme to obtain the multi-view clustering results. Extensive experimental results on $5$ public datasets are provided to reveal the effectiveness of the algorithm and its superior performance over other state-of-the-art alternatives.
Jointly Adversarial Network to Wavelength Compensation and Dehazing of Underwater Images
Jul 12, 2019


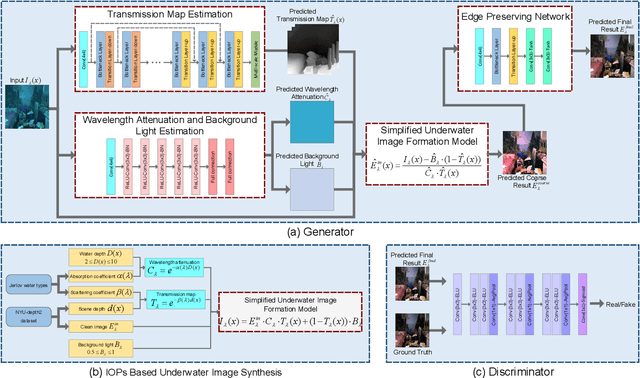
Severe color casts, low contrast and blurriness of underwater images caused by light absorption and scattering result in a difficult task for exploring underwater environments. Different from most of previous underwater image enhancement methods that compute light attenuation along object-camera path through hazy image formation model, we propose a novel jointly wavelength compensation and dehazing network (JWCDN) that takes into account the wavelength attenuation along surface-object path and the scattering along object-camera path simultaneously. By embedding a simplified underwater formation model into generative adversarial network, we can jointly estimates the transmission map, wavelength attenuation and background light via different network modules, and uses the simplified underwater image formation model to recover degraded underwater images. Especially, a multi-scale densely connected encoder-decoder network is proposed to leverage features from multiple layers for estimating the transmission map. To further improve the recovered image, we use an edge preserving network module to enhance the detail of the recovered image. Moreover, to train the proposed network, we propose a novel underwater image synthesis method that generates underwater images with inherent optical properties of different water types. The synthesis method can simulate the color, contrast and blurriness appearance of real-world underwater environments simultaneously. Extensive experiments on synthetic and real-world underwater images demonstrate that the proposed method yields comparable or better results on both subjective and objective assessments, compared with several state-of-the-art methods.
Removing Stripes, Scratches, and Curtaining with Non-Recoverable Compressed Sensing
Jan 23, 2019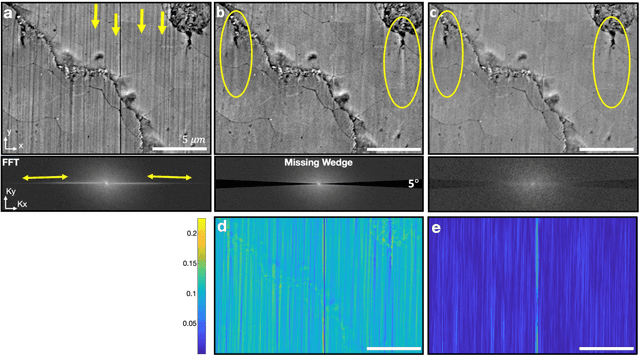

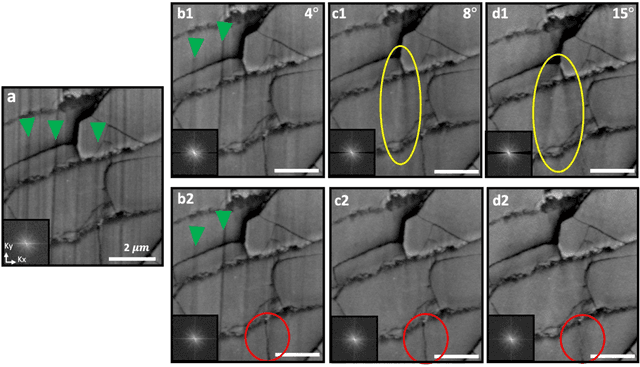

Highly-directional image artifacts such as ion mill curtaining, mechanical scratches, or image striping from beam instability degrade the interpretability of micrographs. These unwanted, aperiodic features extend the image along a primary direction and occupy a small wedge of information in Fourier space. Deleting this wedge of data replaces stripes, scratches, or curtaining, with more complex streaking and blurring artifacts-known within the tomography community as missing wedge artifacts. Here, we overcome this problem by recovering the missing region using total variation minimization, which leverages image sparsity based reconstruction techniques-colloquially referred to as compressed sensing-to reliably restore images corrupted by stripe like features. Our approach removes beam instability, ion mill curtaining, mechanical scratches, or any stripe features and remains robust at low signal-to-noise. The success of this approach is achieved by exploiting compressed sensings inability to recover directional structures that are highly localized and missing in Fourier Space.
Guiding Intelligent Surveillance System by learning-by-synthesis gaze estimation
Oct 08, 2018
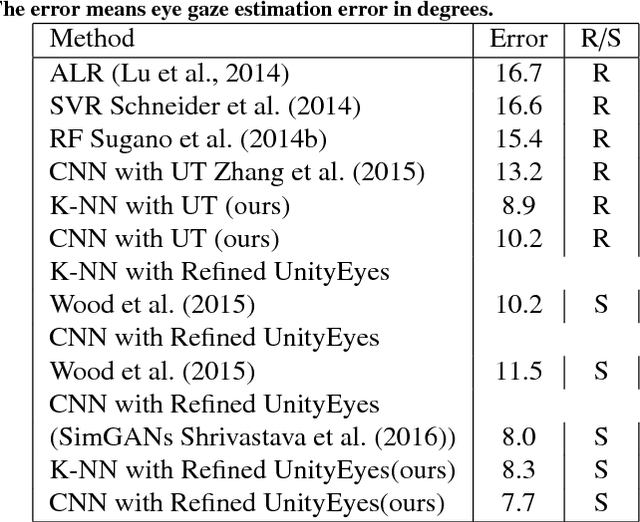

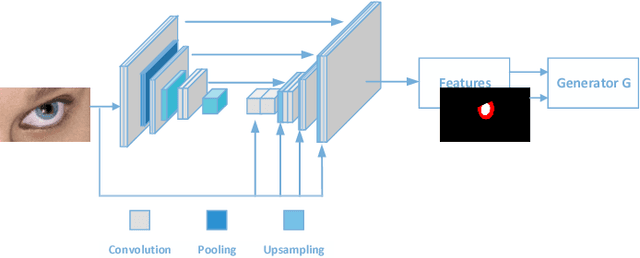
We describe a novel learning-by-synthesis method for estimating gaze direction of an automated intelligent surveillance system. Recently, progress in learning-by-synthesis has proposed training models on synthetic images, which can effectively reduce the cost of manpower and material resources. However, learning from synthetic images still fails to achieve the desired performance compared to naturalistic images due to the different distribution of synthetic images. In an attempt to address this issue, previous method is to improve the realism of synthetic images by learning a model. However, the disadvantage of the method is that the distortion has not been improved and the authenticity level is unstable. To solve this problem, we put forward a new structure to improve synthetic images, via the reference to the idea of style transformation, through which we can efficiently reduce the distortion of pictures and minimize the need of real data annotation. We estimate that this enables generation of highly realistic images, which we demonstrate both qualitatively and with a user study. We quantitatively evaluate the generated images by training models for gaze estimation. We show a significant improvement over using synthetic images, and achieve state-of-the-art results on various datasets including MPIIGaze dataset.