 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptive Person Search via Dual Self-Calibration
Dec 21, 2024



Unsupervised Domain Adaptive (UDA) person search focuses on employing the model trained on a labeled source domain dataset to a target domain dataset without any additional annotations. Most effective UDA person search methods typically utilize the ground truth of the source domain and pseudo-labels derived from clustering during the training process for domain adaptation. However, the performance of these approaches will be significantly restricted by the disrupting pseudo-labels resulting from inter-domain disparities. In this paper, we propose a Dual Self-Calibration (DSCA) framework for UDA person search that effectively eliminates the interference of noisy pseudo-labels by considering both the image-level and instance-level features perspectives. Specifically, we first present a simple yet effective Perception-Driven Adaptive Filter (PDAF) to adaptively predict a dynamic filter threshold based on input features. This threshold assists in eliminating noisy pseudo-boxes and other background interference, allowing our approach to focus on foreground targets and avoid indiscriminate domain adaptation. Besides, we further propose a Cluster Proxy Representation (CPR) module to enhance the update strategy of cluster representation, which mitigates the pollution of clusters from misidentified instances and effectively streamlines the training process for unlabeled target domains. With the above design, our method can achieve state-of-the-art (SOTA) performance on two benchmark datasets, with 80.2% mAP and 81.7% top-1 on the CUHK-SYSU dataset, with 39.9% mAP and 81.6% top-1 on the PRW dataset, which is comparable to or even exceeds the performance of some fully supervised methods. Our source code is available at https://github.com/whbdmu/DSCA.
Anchor Learning with Potential Cluster Constraints for Multi-view Clustering
Dec 21, 2024



Anchor-based multi-view clustering (MVC) has received extensive attention due to its efficient performance. Existing methods only focus on how to dynamically learn anchors from the original data and simultaneously construct anchor graphs describing the relationships between samples and perform clustering, while ignoring the reality of anchors, i.e., high-quality anchors should be generated uniformly from different clusters of data rather than scattered outside the clusters. To deal with this problem, we propose a noval method termed Anchor Learning with Potential Cluster Constraints for Multi-view Clustering (ALPC) method. Specifically, ALPC first establishes a shared latent semantic module to constrain anchors to be generated from specific clusters, and subsequently, ALPC improves the representativeness and discriminability of anchors by adapting the anchor graph to capture the common clustering center of mass from samples and anchors, respectively. Finally, ALPC combines anchor learning and graph construction into a unified framework for collaborative learning and mutual optimization to improve the clustering performance. Extensive experiments demonstrate the effectiveness of our proposed method compared to some state-of-the-art MVC methods. Our source code is available at https://github.com/whbdmu/ALPC.
Fast One-Stage Unsupervised Domain Adaptive Person Search
May 05, 2024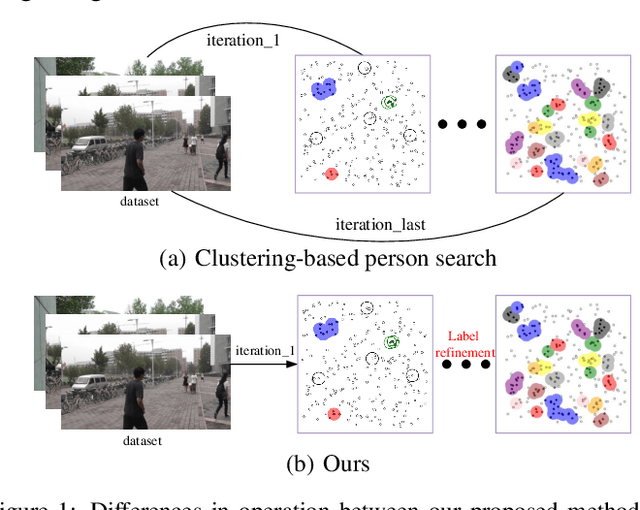

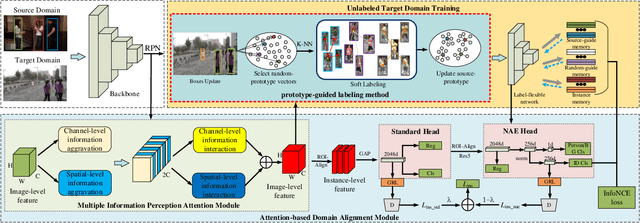
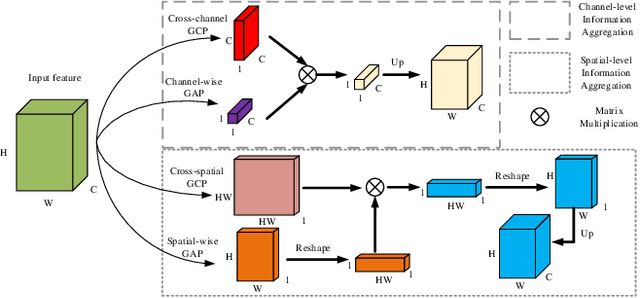
Unsupervised person search aims to localize a particular target person from a gallery set of scene images without annotations, which is extremely challenging due to the unexpected variations of the unlabeled domains. However, most existing methods dedicate to developing multi-stage models to adapt domain variations while using clustering for iterative model training, which inevitably increases model complexity. To address this issue, we propose a Fast One-stage Unsupervised person Search (FOUS) which complementary integrates domain adaptaion with label adaptaion within an end-to-end manner without iterative clustering. To minimize the domain discrepancy, FOUS introduced an Attention-based Domain Alignment Module (ADAM) which can not only align various domains for both detection and ReID tasks but also construct an attention mechanism to reduce the adverse impacts of low-quality candidates resulting from unsupervised detection. Moreover, to avoid the redundant iterative clustering mode, FOUS adopts a prototype-guided labeling method which minimizes redundant correlation computations for partial samples and assigns noisy coarse label groups efficiently. The coarse label groups will be continuously refined via label-flexible training network with an adaptive selection strategy. With the adapted domains and labels, FOUS can achieve the state-of-the-art (SOTA) performance on two benchmark datasets, CUHK-SYSU and PRW. The code is available at https://github.com/whbdmu/FOUS.
Scene-Adaptive Person Search via Bilateral Modulations
May 05, 2024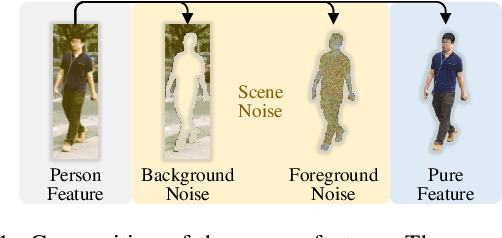
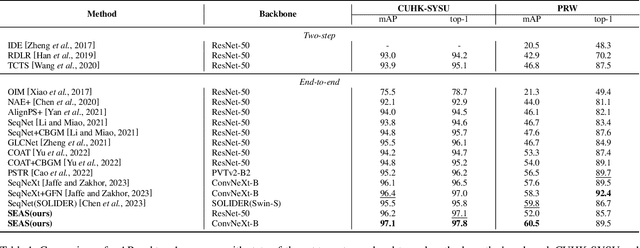
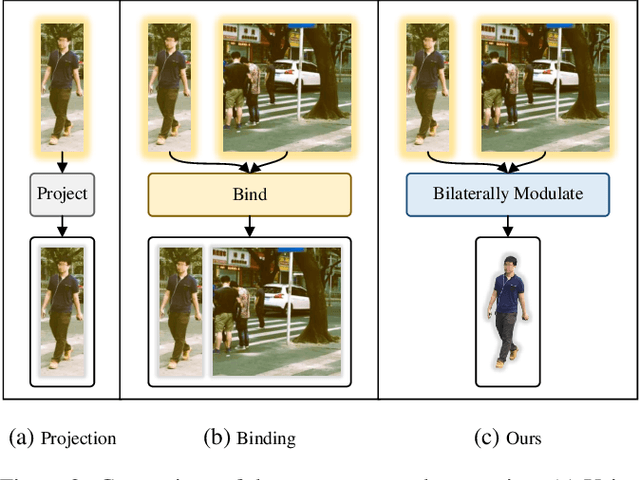

Person search aims to localize specific a target person from a gallery set of images with various scenes. As the scene of moving pedestrian changes, the captured person image inevitably bring in lots of background noise and foreground noise on the person feature, which are completely unrelated to the person identity, leading to severe performance degeneration. To address this issue, we present a Scene-Adaptive Person Search (SEAS) model by introducing bilateral modulations to simultaneously eliminate scene noise and maintain a consistent person representation to adapt to various scenes. In SEAS, a Background Modulation Network (BMN) is designed to encode the feature extracted from the detected bounding box into a multi-granularity embedding, which reduces the input of background noise from multiple levels with norm-aware. Additionally, to mitigate the effect of foreground noise on the person feature, SEAS introduces a Foreground Modulation Network (FMN) to compute the clutter reduction offset for the person embedding based on the feature map of the scene image. By bilateral modulations on both background and foreground within an end-to-end manner, SEAS obtains consistent feature representations without scene noise. SEAS can achieve state-of-the-art (SOTA) performance on two benchmark datasets, CUHK-SYSU with 97.1\% mAP and PRW with 60.5\% mAP. The code is available at https://github.com/whbdmu/SEAS.
Unsupervised Vehicle Re-identification with Progressive Adaptation
Jun 20, 2020

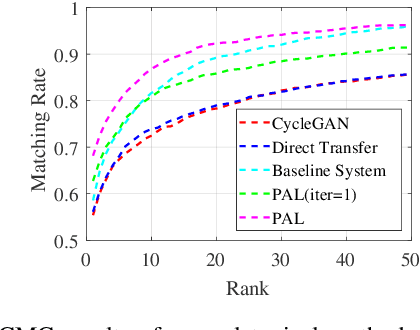

Vehicle re-identification (reID) aims at identifying vehicles across different non-overlapping cameras views. The existing methods heavily relied on well-labeled datasets for ideal performance, which inevitably causes fateful drop due to the severe domain bias between the training domain and the real-world scenes; worse still, these approaches required full annotations, which is labor-consuming. To tackle these challenges, we propose a novel progressive adaptation learning method for vehicle reID, named PAL, which infers from the abundant data without annotations. For PAL, a data adaptation module is employed for source domain, which generates the images with similar data distribution to unlabeled target domain as ``pseudo target samples''. These pseudo samples are combined with the unlabeled samples that are selected by a dynamic sampling strategy to make training faster. We further proposed a weighted label smoothing (WLS) loss, which considers the similarity between samples with different clusters to balance the confidence of pseudo labels. Comprehensive experimental results validate the advantages of PAL on both VehicleID and VeRi-776 dataset.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
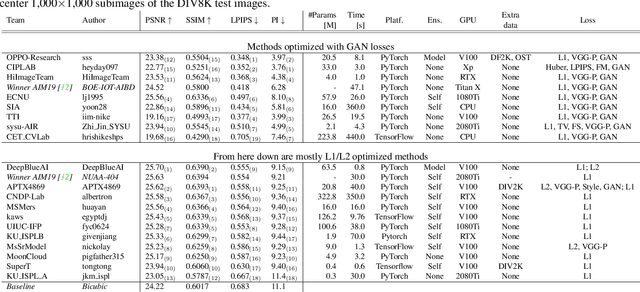

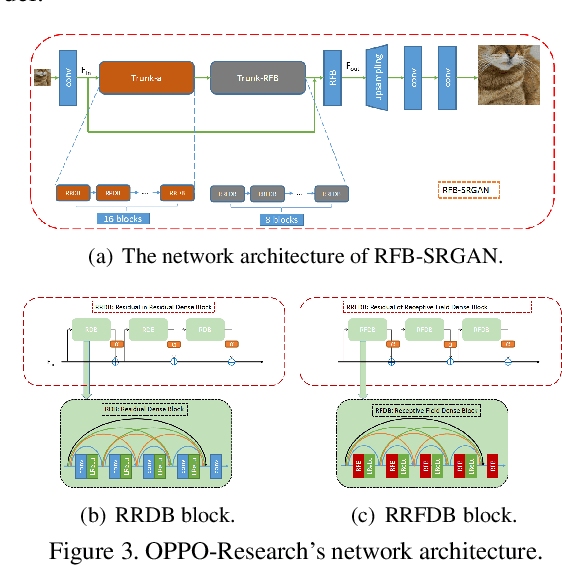
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Discriminative Feature and Dictionary Learning with Part-aware Model for Vehicle Re-identification
Mar 16, 2020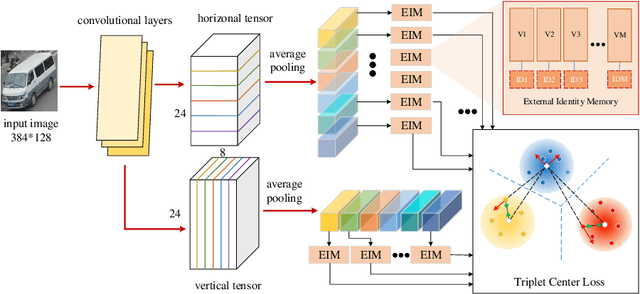
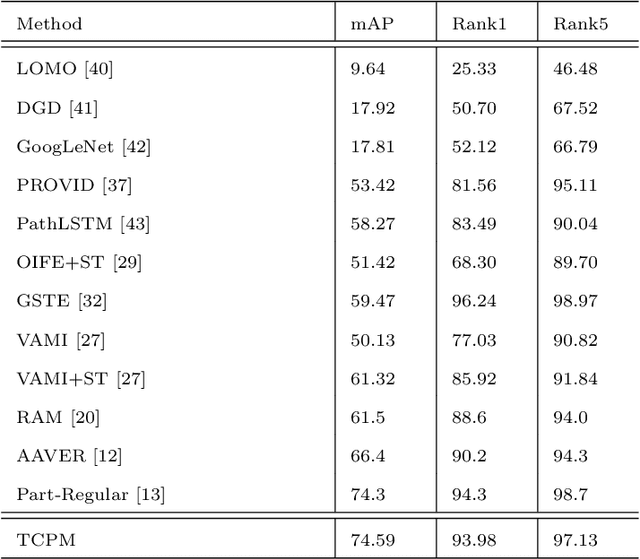
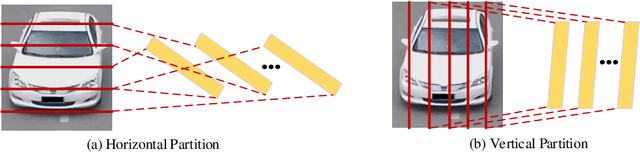
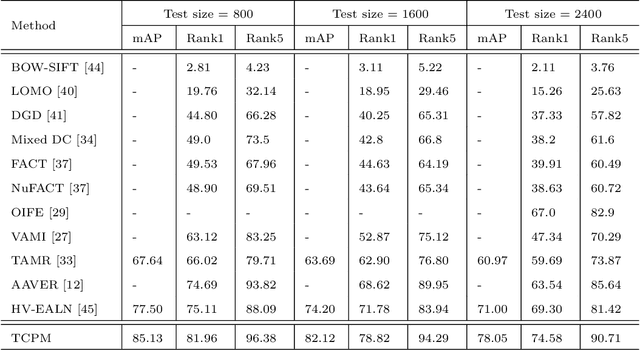
With the development of smart cities, urban surveillance video analysis will play a further significant role in intelligent transportation systems. Identifying the same target vehicle in large datasets from non-overlapping cameras should be highlighted, which has grown into a hot topic in promoting intelligent transportation systems. However, vehicle re-identification (re-ID) technology is a challenging task since vehicles of the same design or manufacturer show similar appearance. To fill these gaps, we tackle this challenge by proposing Triplet Center Loss based Part-aware Model (TCPM) that leverages the discriminative features in part details of vehicles to refine the accuracy of vehicle re-identification. TCPM base on part discovery is that partitions the vehicle from horizontal and vertical directions to strengthen the details of the vehicle and reinforce the internal consistency of the parts. In addition, to eliminate intra-class differences in local regions of the vehicle, we propose external memory modules to emphasize the consistency of each part to learn the discriminating features, which forms a global dictionary over all categories in dataset. In TCPM, triplet-center loss is introduced to ensure each part of vehicle features extracted has intra-class consistency and inter-class separability. Experimental results show that our proposed TCPM has an enormous preference over the existing state-of-the-art methods on benchmark datasets VehicleID and VeRi-776.
Attribute-guided Feature Learning Network for Vehicle Re-identification
Jan 12, 2020
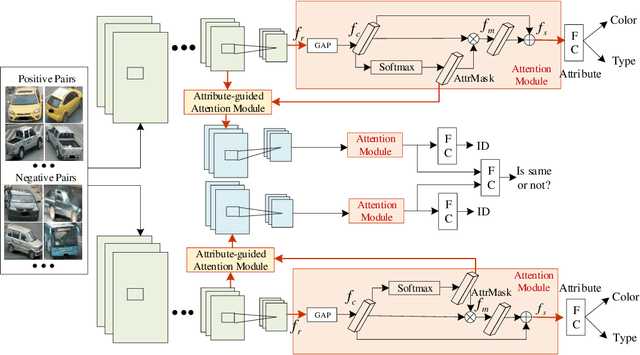
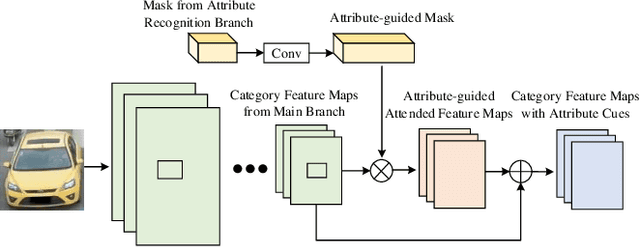

Vehicle re-identification (reID) plays an important role in the automatic analysis of the increasing urban surveillance videos, which has become a hot topic in recent years. However, it poses the critical but challenging problem that is caused by various viewpoints of vehicles, diversified illuminations and complicated environments. Till now, most existing vehicle reID approaches focus on learning metrics or ensemble to derive better representation, which are only take identity labels of vehicle into consideration. However, the attributes of vehicle that contain detailed descriptions are beneficial for training reID model. Hence, this paper proposes a novel Attribute-Guided Network (AGNet), which could learn global representation with the abundant attribute features in an end-to-end manner. Specially, an attribute-guided module is proposed in AGNet to generate the attribute mask which could inversely guide to select discriminative features for category classification. Besides that, in our proposed AGNet, an attribute-based label smoothing (ALS) loss is presented to better train the reID model, which can strength the distinct ability of vehicle reID model to regularize AGNet model according to the attributes. Comprehensive experimental results clearly demonstrate that our method achieves excellent performance on both VehicleID dataset and VeRi-776 dataset.
Eliminating cross-camera bias for vehicle re-identification
Dec 21, 2019
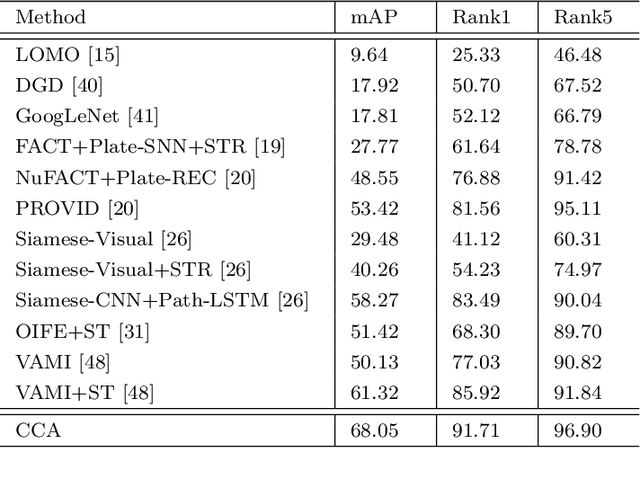
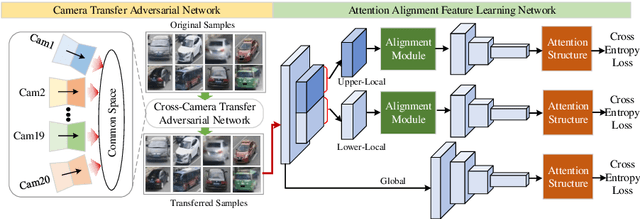
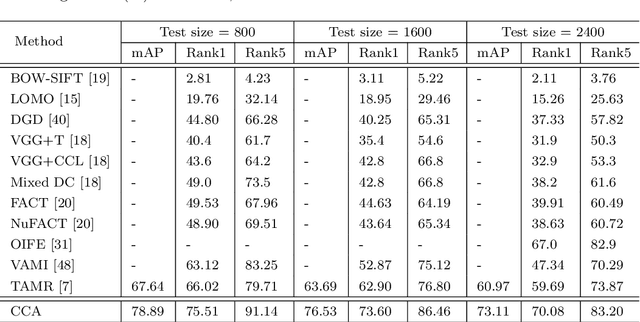
Vehicle re-identification (reID) often requires recognize a target vehicle in large datasets captured from multi-cameras. It plays an important role in the automatic analysis of the increasing urban surveillance videos, which has become a hot topic in recent years. However, the appearance of vehicle images is easily affected by the environment that various illuminations, different backgrounds and viewpoints, which leads to the large bias between different cameras. To address this problem, this paper proposes a cross-camera adaptation framework (CCA), which smooths the bias by exploiting the common space between cameras for all samples. CCA first transfers images from multi-cameras into one camera to reduce the impact of the illumination and resolution, which generates the samples with the similar distribution. Then, to eliminate the influence of background and focus on the valuable parts, we propose an attention alignment network (AANet) to learn powerful features for vehicle reID. Specially, in AANet, the spatial transfer network with attention module is introduced to locate a series of the most discriminative regions with high-attention weights and suppress the background. Moreover, comprehensive experimental results have demonstrated that our proposed CCA can achieve excellent performances on benchmark datasets VehicleID and VeRi-776.
Graph-based Multi-view Binary Learning for Image Clustering
Dec 11, 2019
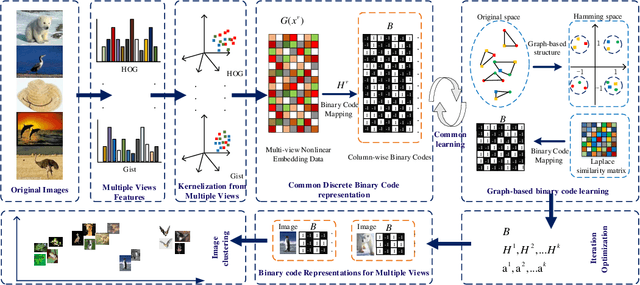


Hashing techniques, also known as binary code learning, have recently gained increasing attention in large-scale data analysis and storage. Generally, most existing hash clustering methods are single-view ones, which lack complete structure or complementary information from multiple views. For cluster tasks, abundant prior researches mainly focus on learning discrete hash code while few works take original data structure into consideration. To address these problems, we propose a novel binary code algorithm for clustering, which adopts graph embedding to preserve the original data structure, called (Graph-based Multi-view Binary Learning) GMBL in this paper. GMBL mainly focuses on encoding the information of multiple views into a compact binary code, which explores complementary information from multiple views. In particular, in order to maintain the graph-based structure of the original data, we adopt a Laplacian matrix to preserve the local linear relationship of the data and map it to the Hamming space. Considering different views have distinctive contributions to the final clustering results, GMBL adopts a strategy of automatically assign weights for each view to better guide the clustering. Finally, An alternating iterative optimization method is adopted to optimize discrete binary codes directly instead of relaxing the binary constraint in two steps. Experiments on five public datasets demonstrate the superiority of our proposed method compared with previous approaches in terms of clustering performance.