 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast One-Stage Unsupervised Domain Adaptive Person Search
May 05, 2024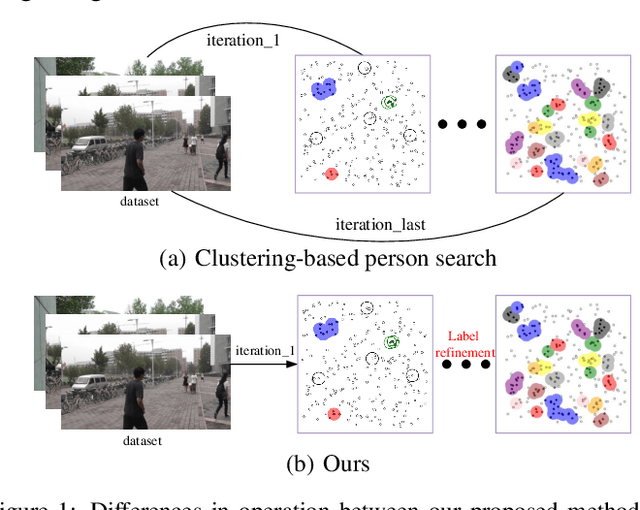

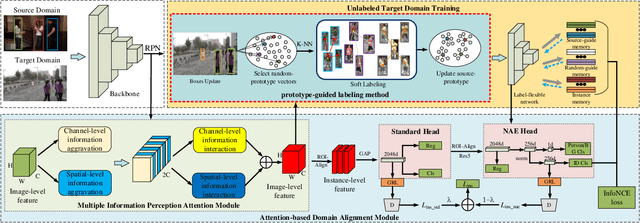
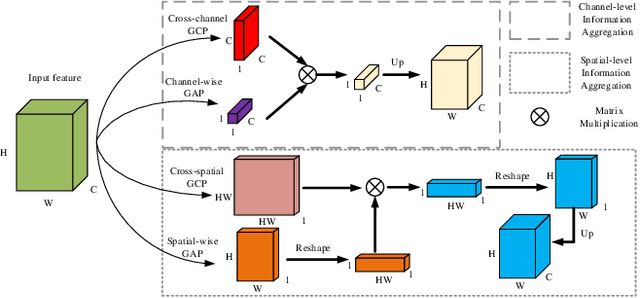
Unsupervised person search aims to localize a particular target person from a gallery set of scene images without annotations, which is extremely challenging due to the unexpected variations of the unlabeled domains. However, most existing methods dedicate to developing multi-stage models to adapt domain variations while using clustering for iterative model training, which inevitably increases model complexity. To address this issue, we propose a Fast One-stage Unsupervised person Search (FOUS) which complementary integrates domain adaptaion with label adaptaion within an end-to-end manner without iterative clustering. To minimize the domain discrepancy, FOUS introduced an Attention-based Domain Alignment Module (ADAM) which can not only align various domains for both detection and ReID tasks but also construct an attention mechanism to reduce the adverse impacts of low-quality candidates resulting from unsupervised detection. Moreover, to avoid the redundant iterative clustering mode, FOUS adopts a prototype-guided labeling method which minimizes redundant correlation computations for partial samples and assigns noisy coarse label groups efficiently. The coarse label groups will be continuously refined via label-flexible training network with an adaptive selection strategy. With the adapted domains and labels, FOUS can achieve the state-of-the-art (SOTA) performance on two benchmark datasets, CUHK-SYSU and PRW. The code is available at https://github.com/whbdmu/FOUS.
Learning to predict crisp boundaries
Jul 26, 2018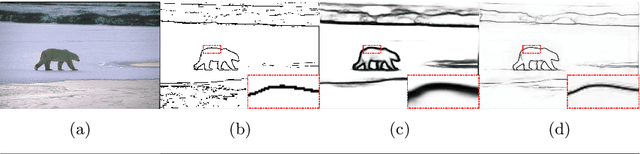



Recent methods for boundary or edge detection built on Deep Convolutional Neural Networks (CNNs) typically suffer from the issue of predicted edges being thick and need post-processing to obtain crisp boundaries. Highly imbalanced categories of boundary versus background in training data is one of main reasons for the above problem. In this work, the aim is to make CNNs produce sharp boundaries without post-processing. We introduce a novel loss for boundary detection, which is very effective for classifying imbalanced data and allows CNNs to produce crisp boundaries. Moreover, we propose an end-to-end network which adopts the bottom-up/top-down architecture to tackle the task. The proposed network effectively leverages hierarchical features and produces pixel-accurate boundary mask, which is critical to reconstruct the edge map. Our experiments illustrate that directly making crisp prediction not only promotes the visual results of CNNs, but also achieves better results against the state-of-the-art on the BSDS500 dataset (ODS F-score of .815) and the NYU Depth dataset (ODS F-score of .762).
Relative Depth Order Estimation Using Multi-scale Densely Connected Convolutional Networks
Jul 27, 2017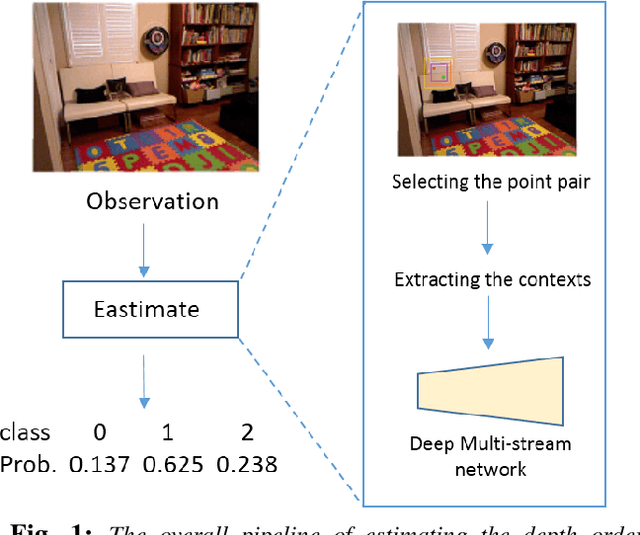
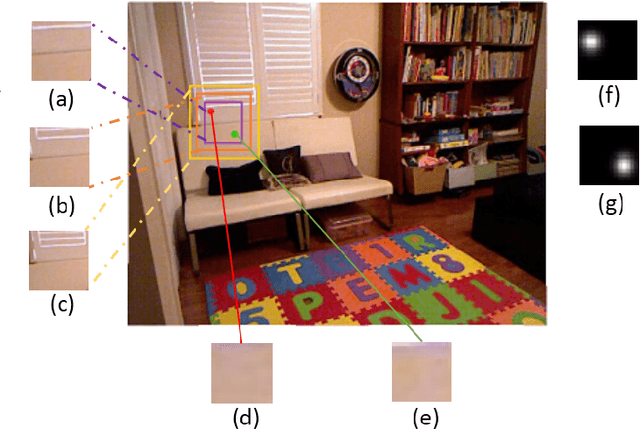


We study the problem of estimating the relative depth order of point pairs in a monocular image. Recent advances mainly focus on using deep convolutional neural networks (DCNNs) to learn and infer the ordinal information from multiple contextual information of the points pair such as global scene context, local contextual information, and the locations. However, it remains unclear how much each context contributes to the task. To address this, we first examine the contribution of each context cue [1], [2] to the performance in the context of depth order estimation. We find out the local context surrounding the points pair contributes the most and the global scene context helps little. Based on the findings, we propose a simple method, using a multi-scale densely-connected network to tackle the task. Instead of learning the global structure, we dedicate to explore the local structure by learning to regress from regions of multiple sizes around the point pairs. Moreover, we use the recent densely connected network [3] to encourage substantial feature reuse as well as deepen our network to boost the performance. We show in experiments that the results of our approach is on par with or better than the state-of-the-art methods with the benefit of using only a small number of training data.