 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep MSFOP: Multiple Spectral filter Operators Preservation in Deep Functional Maps for Unsupervised Shape Matching
Feb 06, 2024



We propose a novel constraint called Multiple Spectral filter Operators Preservation (MSFOR) to compute functional maps and based on it, develop an efficient deep functional map architecture called Deep MSFOP for shape matching. The core idea is that, instead of using the general descriptor preservation constraint, we require our maps to preserve multiple spectral filter operators. This allows us to incorporate more informative geometrical information, contained in different frequency bands of functions, into the functional map computing. This can be confirmed by that some previous techniques like wavelet preservation and LBO commutativity are actually our special cases. Moreover, we also develop a very efficient way to compute the maps with MSFOP constraint, which can be conveniently embedded into the deep learning, especially having learnable filter operators. Utilizing the above results, we finally design our Deep MSFOP pipeline, equipped with a suitable unsupervised loss jointly penalizing the functional map and the underlying pointwise map. Our deep functional map has notable advantages, including that the functional map is more geometrically informative and guaranteed to be proper, and the computing is numerically stable. Extensive experimental results on different datasets demonstrate that our approach outperforms the existing state-of-the-art methods, especially in challenging settings like non-isometric and inconsistent topology datasets.
Visual Attack and Defense on Text
Aug 07, 2020


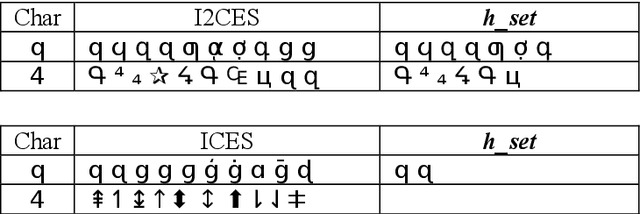
Modifying characters of a piece of text to their visual similar ones often ap-pear in spam in order to fool inspection systems and other conditions, which we regard as a kind of adversarial attack to neural models. We pro-pose a way of generating such visual text attack and show that the attacked text are readable by humans but mislead a neural classifier greatly. We ap-ply a vision-based model and adversarial training to defense the attack without losing the ability to understand normal text. Our results also show that visual attack is extremely sophisticated and diverse, more work needs to be done to solve this.
Learning to predict crisp boundaries
Jul 26, 2018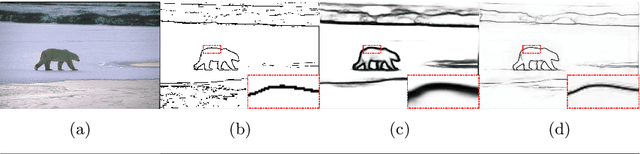



Recent methods for boundary or edge detection built on Deep Convolutional Neural Networks (CNNs) typically suffer from the issue of predicted edges being thick and need post-processing to obtain crisp boundaries. Highly imbalanced categories of boundary versus background in training data is one of main reasons for the above problem. In this work, the aim is to make CNNs produce sharp boundaries without post-processing. We introduce a novel loss for boundary detection, which is very effective for classifying imbalanced data and allows CNNs to produce crisp boundaries. Moreover, we propose an end-to-end network which adopts the bottom-up/top-down architecture to tackle the task. The proposed network effectively leverages hierarchical features and produces pixel-accurate boundary mask, which is critical to reconstruct the edge map. Our experiments illustrate that directly making crisp prediction not only promotes the visual results of CNNs, but also achieves better results against the state-of-the-art on the BSDS500 dataset (ODS F-score of .815) and the NYU Depth dataset (ODS F-score of .762).
Relative Depth Order Estimation Using Multi-scale Densely Connected Convolutional Networks
Jul 27, 2017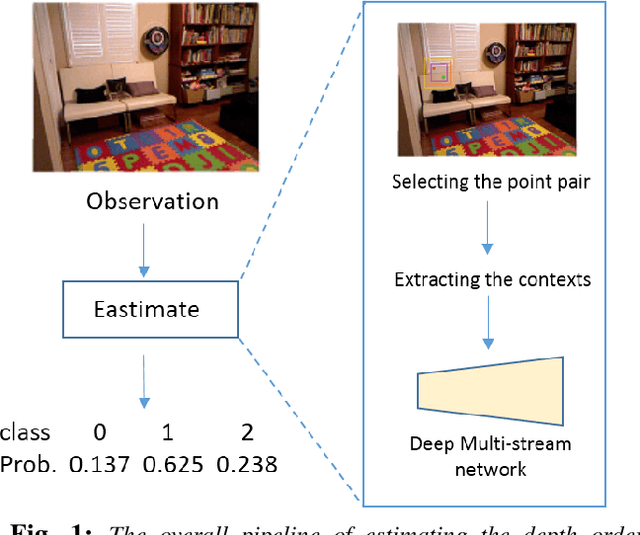
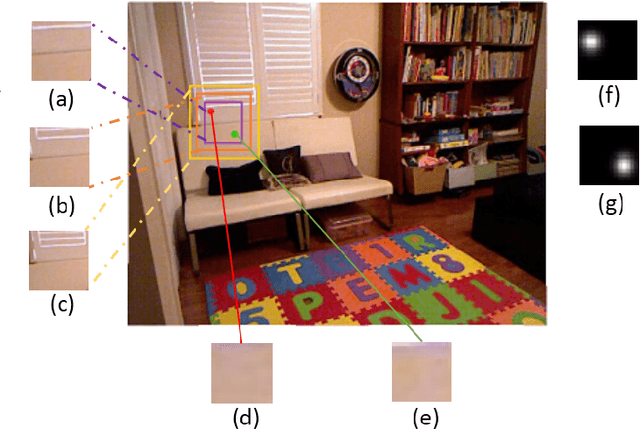


We study the problem of estimating the relative depth order of point pairs in a monocular image. Recent advances mainly focus on using deep convolutional neural networks (DCNNs) to learn and infer the ordinal information from multiple contextual information of the points pair such as global scene context, local contextual information, and the locations. However, it remains unclear how much each context contributes to the task. To address this, we first examine the contribution of each context cue [1], [2] to the performance in the context of depth order estimation. We find out the local context surrounding the points pair contributes the most and the global scene context helps little. Based on the findings, we propose a simple method, using a multi-scale densely-connected network to tackle the task. Instead of learning the global structure, we dedicate to explore the local structure by learning to regress from regions of multiple sizes around the point pairs. Moreover, we use the recent densely connected network [3] to encourage substantial feature reuse as well as deepen our network to boost the performance. We show in experiments that the results of our approach is on par with or better than the state-of-the-art methods with the benefit of using only a small number of training data.