 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimRPD: Optimizing Recruitment Proactive Dialogue Agents through Simulator-Based Data Evaluation and Selection
Jan 08, 2026Task-oriented proactive dialogue agents play a pivotal role in recruitment, particularly for steering conversations towards specific business outcomes, such as acquiring social-media contacts for private-channel conversion. Although supervised fine-tuning and reinforcement learning have proven effective for training such agents, their performance is heavily constrained by the scarcity of high-quality, goal-oriented domain-specific training data. To address this challenge, we propose SimRPD, a three-stage framework for training recruitment proactive dialogue agents. First, we develop a high-fidelity user simulator to synthesize large-scale conversational data through multi-turn online dialogue. Then we introduce a multi-dimensional evaluation framework based on Chain-of-Intention (CoI) to comprehensively assess the simulator and effectively select high-quality data, incorporating both global-level and instance-level metrics. Finally, we train the recruitment proactive dialogue agent on the selected dataset. Experiments in a real-world recruitment scenario demonstrate that SimRPD outperforms existing simulator-based data selection strategies, highlighting its practical value for industrial deployment and its potential applicability to other business-oriented dialogue scenarios.
From Shots to Stories: LLM-Assisted Video Editing with Unified Language Representations
May 18, 2025Large Language Models (LLMs) and Vision-Language Models (VLMs) have demonstrated remarkable reasoning and generalization capabilities in video understanding; however, their application in video editing remains largely underexplored. This paper presents the first systematic study of LLMs in the context of video editing. To bridge the gap between visual information and language-based reasoning, we introduce L-Storyboard, an intermediate representation that transforms discrete video shots into structured language descriptions suitable for LLM processing. We categorize video editing tasks into Convergent Tasks and Divergent Tasks, focusing on three core tasks: Shot Attributes Classification, Next Shot Selection, and Shot Sequence Ordering. To address the inherent instability of divergent task outputs, we propose the StoryFlow strategy, which converts the divergent multi-path reasoning process into a convergent selection mechanism, effectively enhancing task accuracy and logical coherence. Experimental results demonstrate that L-Storyboard facilitates a more robust mapping between visual information and language descriptions, significantly improving the interpretability and privacy protection of video editing tasks. Furthermore, StoryFlow enhances the logical consistency and output stability in Shot Sequence Ordering, underscoring the substantial potential of LLMs in intelligent video editing.
An Information Compensation Framework for Zero-Shot Skeleton-based Action Recognition
Jun 02, 2024



Zero-shot human skeleton-based action recognition aims to construct a model that can recognize actions outside the categories seen during training. Previous research has focused on aligning sequences' visual and semantic spatial distributions. However, these methods extract semantic features simply. They ignore that proper prompt design for rich and fine-grained action cues can provide robust representation space clustering. In order to alleviate the problem of insufficient information available for skeleton sequences, we design an information compensation learning framework from an information-theoretic perspective to improve zero-shot action recognition accuracy with a multi-granularity semantic interaction mechanism. Inspired by ensemble learning, we propose a multi-level alignment (MLA) approach to compensate information for action classes. MLA aligns multi-granularity embeddings with visual embedding through a multi-head scoring mechanism to distinguish semantically similar action names and visually similar actions. Furthermore, we introduce a new loss function sampling method to obtain a tight and robust representation. Finally, these multi-granularity semantic embeddings are synthesized to form a proper decision surface for classification. Significant action recognition performance is achieved when evaluated on the challenging NTU RGB+D, NTU RGB+D 120, and PKU-MMD benchmarks and validate that multi-granularity semantic features facilitate the differentiation of action clusters with similar visual features.
Deep MSFOP: Multiple Spectral filter Operators Preservation in Deep Functional Maps for Unsupervised Shape Matching
Feb 06, 2024



We propose a novel constraint called Multiple Spectral filter Operators Preservation (MSFOR) to compute functional maps and based on it, develop an efficient deep functional map architecture called Deep MSFOP for shape matching. The core idea is that, instead of using the general descriptor preservation constraint, we require our maps to preserve multiple spectral filter operators. This allows us to incorporate more informative geometrical information, contained in different frequency bands of functions, into the functional map computing. This can be confirmed by that some previous techniques like wavelet preservation and LBO commutativity are actually our special cases. Moreover, we also develop a very efficient way to compute the maps with MSFOP constraint, which can be conveniently embedded into the deep learning, especially having learnable filter operators. Utilizing the above results, we finally design our Deep MSFOP pipeline, equipped with a suitable unsupervised loss jointly penalizing the functional map and the underlying pointwise map. Our deep functional map has notable advantages, including that the functional map is more geometrically informative and guaranteed to be proper, and the computing is numerically stable. Extensive experimental results on different datasets demonstrate that our approach outperforms the existing state-of-the-art methods, especially in challenging settings like non-isometric and inconsistent topology datasets.
Multi-Scene Generalized Trajectory Global Graph Solver with Composite Nodes for Multiple Object Tracking
Dec 14, 2023The global multi-object tracking (MOT) system can consider interaction, occlusion, and other ``visual blur'' scenarios to ensure effective object tracking in long videos. Among them, graph-based tracking-by-detection paradigms achieve surprising performance. However, their fully-connected nature poses storage space requirements that challenge algorithm handling long videos. Currently, commonly used methods are still generated trajectories by building one-forward associations across frames. Such matches produced under the guidance of first-order similarity information may not be optimal from a longer-time perspective. Moreover, they often lack an end-to-end scheme for correcting mismatches. This paper proposes the Composite Node Message Passing Network (CoNo-Link), a multi-scene generalized framework for modeling ultra-long frames information for association. CoNo-Link's solution is a low-storage overhead method for building constrained connected graphs. In addition to the previous method of treating objects as nodes, the network innovatively treats object trajectories as nodes for information interaction, improving the graph neural network's feature representation capability. Specifically, we formulate the graph-building problem as a top-k selection task for some reliable objects or trajectories. Our model can learn better predictions on longer-time scales by adding composite nodes. As a result, our method outperforms the state-of-the-art in several commonly used datasets.
Language Knowledge-Assisted Representation Learning for Skeleton-Based Action Recognition
May 21, 2023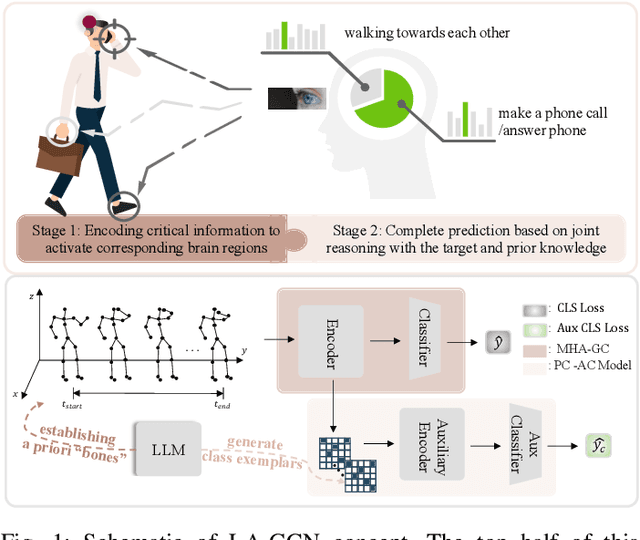

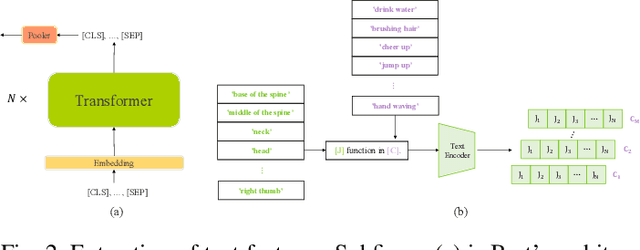

How humans understand and recognize the actions of others is a complex neuroscientific problem that involves a combination of cognitive mechanisms and neural networks. Research has shown that humans have brain areas that recognize actions that process top-down attentional information, such as the temporoparietal association area. Also, humans have brain regions dedicated to understanding the minds of others and analyzing their intentions, such as the medial prefrontal cortex of the temporal lobe. Skeleton-based action recognition creates mappings for the complex connections between the human skeleton movement patterns and behaviors. Although existing studies encoded meaningful node relationships and synthesized action representations for classification with good results, few of them considered incorporating a priori knowledge to aid potential representation learning for better performance. LA-GCN proposes a graph convolution network using large-scale language models (LLM) knowledge assistance. First, the LLM knowledge is mapped into a priori global relationship (GPR) topology and a priori category relationship (CPR) topology between nodes. The GPR guides the generation of new "bone" representations, aiming to emphasize essential node information from the data level. The CPR mapping simulates category prior knowledge in human brain regions, encoded by the PC-AC module and used to add additional supervision-forcing the model to learn class-distinguishable features. In addition, to improve information transfer efficiency in topology modeling, we propose multi-hop attention graph convolution. It aggregates each node's k-order neighbor simultaneously to speed up model convergence. LA-GCN reaches state-of-the-art on NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets.
Restricting Greed in Training of Generative Adversarial Network
Sep 06, 2018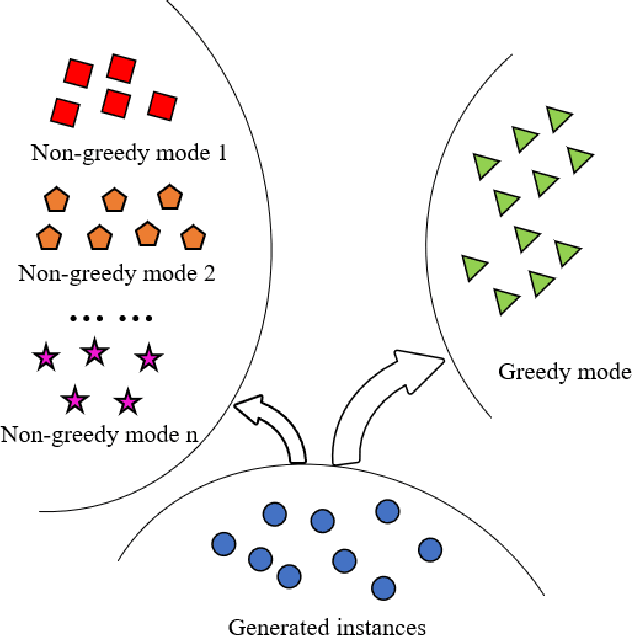
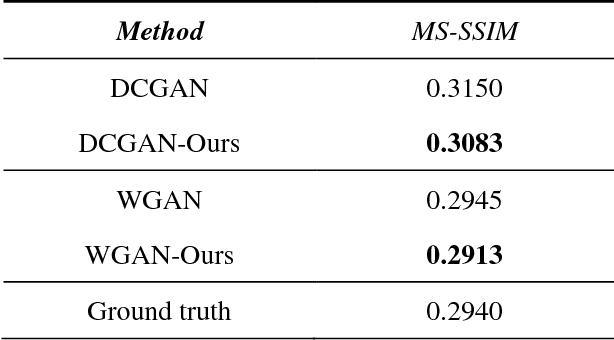
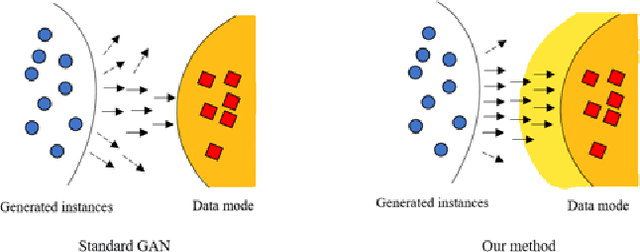
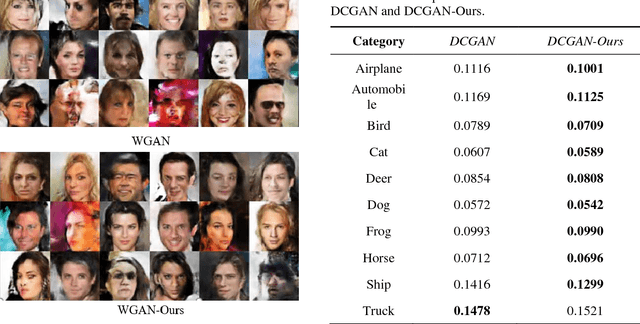
Generative adversarial network (GAN) has gotten wide re-search interest in the field of deep learning. Variations of GAN have achieved competitive results on specific tasks. However, the stability of training and diversity of generated instances are still worth studying further. Training of GAN can be thought of as a greedy procedure, in which the generative net tries to make the locally optimal choice (minimizing loss function of discriminator) in each iteration. Unfortunately, this often makes generated data resemble only a few modes of real data and rotate between modes. To alleviate these problems, we propose a novel training strategy to restrict greed in training of GAN. With help of our method, the generated samples can cover more instance modes with more stable training process. Evaluating our method on several representative datasets, we demonstrate superiority of improved training strategy on typical GAN models with different distance metrics.