 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue of Information: A Framework for Human-Agent Communication
Jan 10, 2026Large Language Model (LLM) agents deployed for real-world tasks face a fundamental dilemma: user requests are underspecified, yet agents must decide whether to act on incomplete information or interrupt users for clarification. Existing approaches either rely on brittle confidence thresholds that require task-specific tuning, or fail to account for the varying stakes of different decisions. We introduce a decision-theoretic framework that resolves this trade-off through the Value of Information (VoI), enabling agents to dynamically weigh the expected utility gain from asking questions against the cognitive cost imposed on users. Our inference-time method requires no hyperparameter tuning and adapts seamlessly across contexts-from casual games to medical diagnosis. Experiments across four diverse domains (20 Questions, medical diagnosis, flight booking, and e-commerce) show that VoI consistently matches or exceeds the best manually-tuned baselines, achieving up to 1.36 utility points higher in high-cost settings. This work provides a parameter-free framework for adaptive agent communication that explicitly balances task risk, query ambiguity, and user effort.
Steer Model beyond Assistant: Controlling System Prompt Strength via Contrastive Decoding
Jan 10, 2026Large language models excel at complex instructions yet struggle to deviate from their helpful assistant persona, as post-training instills strong priors that resist conflicting instructions. We introduce system prompt strength, a training-free method that treats prompt adherence as a continuous control. By contrasting logits from target and default system prompts, we isolate and amplify the behavioral signal unique to the target persona by a scalar factor alpha. Across five diverse benchmarks spanning constraint satisfaction, behavioral control, pluralistic alignment, capability modulation, and stylistic control, our method yields substantial improvements: up to +8.5 strict accuracy on IFEval, +45pp refusal rate on OffTopicEval, and +13% steerability on Prompt-Steering. Our approach enables practitioners to modulate system prompt strength, providing dynamic control over model behavior without retraining.
Large Language Models Meet Virtual Cell: A Survey
Oct 09, 2025Large language models (LLMs) are transforming cellular biology by enabling the development of "virtual cells"--computational systems that represent, predict, and reason about cellular states and behaviors. This work provides a comprehensive review of LLMs for virtual cell modeling. We propose a unified taxonomy that organizes existing methods into two paradigms: LLMs as Oracles, for direct cellular modeling, and LLMs as Agents, for orchestrating complex scientific tasks. We identify three core tasks--cellular representation, perturbation prediction, and gene regulation inference--and review their associated models, datasets, evaluation benchmarks, as well as the critical challenges in scalability, generalizability, and interpretability.
EraserDiT: Fast Video Inpainting with Diffusion Transformer Model
Jun 15, 2025



Video object removal and inpainting are critical tasks in the fields of computer vision and multimedia processing, aimed at restoring missing or corrupted regions in video sequences. Traditional methods predominantly rely on flow-based propagation and spatio-temporal Transformers, but these approaches face limitations in effectively leveraging long-term temporal features and ensuring temporal consistency in the completion results, particularly when dealing with large masks. Consequently, performance on extensive masked areas remains suboptimal. To address these challenges, this paper introduces a novel video inpainting approach leveraging the Diffusion Transformer (DiT). DiT synergistically combines the advantages of diffusion models and transformer architectures to maintain long-term temporal consistency while ensuring high-quality inpainting results. We propose a Circular Position-Shift strategy to further enhance long-term temporal consistency during the inference stage. Additionally, the proposed method automatically detects objects within videos, interactively removes specified objects, and generates corresponding prompts. In terms of processing speed, it takes only 180 seconds (testing on one NVIDIA A100 GPU) to complete a video with a resolution of $1080 \times 1920$ with 121 frames without any acceleration method. Experimental results indicate that the proposed method demonstrates superior performance in content fidelity, texture restoration, and temporal consistency. Project page: https://jieliu95.github.io/EraserDiT_demo.
MATCHA: Can Multi-Agent Collaboration Build a Trustworthy Conversational Recommender?
Apr 26, 2025



In this paper, we propose a multi-agent collaboration framework called MATCHA for conversational recommendation system, leveraging large language models (LLMs) to enhance personalization and user engagement. Users can request recommendations via free-form text and receive curated lists aligned with their interests, preferences, and constraints. Our system introduces specialized agents for intent analysis, candidate generation, ranking, re-ranking, explainability, and safeguards. These agents collaboratively improve recommendations accuracy, diversity, and safety. On eight metrics, our model achieves superior or comparable performance to the current state-of-the-art. Through comparisons with six baseline models, our approach addresses key challenges in conversational recommendation systems for game recommendations, including: (1) handling complex, user-specific requests, (2) enhancing personalization through multi-agent collaboration, (3) empirical evaluation and deployment, and (4) ensuring safe and trustworthy interactions.
QuantCache: Adaptive Importance-Guided Quantization with Hierarchical Latent and Layer Caching for Video Generation
Mar 09, 2025Recently, Diffusion Transformers (DiTs) have emerged as a dominant architecture in video generation, surpassing U-Net-based models in terms of performance. However, the enhanced capabilities of DiTs come with significant drawbacks, including increased computational and memory costs, which hinder their deployment on resource-constrained devices. Current acceleration techniques, such as quantization and cache mechanism, offer limited speedup and are often applied in isolation, failing to fully address the complexities of DiT architectures. In this paper, we propose QuantCache, a novel training-free inference acceleration framework that jointly optimizes hierarchical latent caching, adaptive importance-guided quantization, and structural redundancy-aware pruning. QuantCache achieves an end-to-end latency speedup of 6.72$\times$ on Open-Sora with minimal loss in generation quality. Extensive experiments across multiple video generation benchmarks demonstrate the effectiveness of our method, setting a new standard for efficient DiT inference. The code and models will be available at https://github.com/JunyiWuCode/QuantCache.
AdaSVD: Adaptive Singular Value Decomposition for Large Language Models
Feb 04, 2025



Large language models (LLMs) have achieved remarkable success in natural language processing (NLP) tasks, yet their substantial memory requirements present significant challenges for deployment on resource-constrained devices. Singular Value Decomposition (SVD) has emerged as a promising compression technique for LLMs, offering considerable reductions in memory overhead. However, existing SVD-based methods often struggle to effectively mitigate the errors introduced by SVD truncation, leading to a noticeable performance gap when compared to the original models. Furthermore, applying a uniform compression ratio across all transformer layers fails to account for the varying importance of different layers. To address these challenges, we propose AdaSVD, an adaptive SVD-based LLM compression approach. Specifically, AdaSVD introduces adaComp, which adaptively compensates for SVD truncation errors by alternately updating the singular matrices U and V^T. Additionally, AdaSVD introduces adaCR, which adaptively assigns layer-specific compression ratios based on the relative importance of each layer. Extensive experiments across multiple LLM families and evaluation metrics demonstrate that AdaSVD consistently outperforms state-of-the-art (SOTA) SVD-based methods, achieving superior performance with significantly reduced memory requirements. The code and models will be available at https://github.com/ZHITENGLI/AdaSVD.
Can Open-source LLMs Enhance Data Synthesis for Toxic Detection?: An Experimental Study
Dec 03, 2024
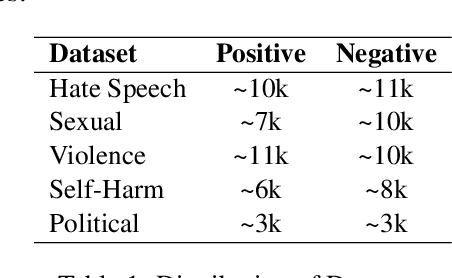


Effective toxic content detection relies heavily on high-quality and diverse data, which serves as the foundation for robust content moderation models. This study explores the potential of open-source LLMs for harmful data synthesis, utilizing prompt engineering and fine-tuning techniques to enhance data quality and diversity. In a two-stage evaluation, we first examine the capabilities of six open-source LLMs in generating harmful data across multiple datasets using prompt engineering. In the second stage, we fine-tune these models to improve data generation while addressing challenges such as hallucination, data duplication, and overfitting. Our findings reveal that Mistral excels in generating high-quality and diverse harmful data with minimal hallucination. Furthermore, fine-tuning enhances data quality, offering scalable and cost-effective solutions for augmenting datasets for specific toxic content detection tasks. These results emphasize the significance of data synthesis in building robust, standalone detection models and highlight the potential of open-source LLMs to advance smaller downstream content moderation systems. We implemented this approach in real-world industrial settings, demonstrating the feasibility and efficiency of fine-tuned open-source LLMs for harmful data synthesis.
Can Open-source LLMs Enhance Data Augmentation for Toxic Detection?: An Experimental Study
Nov 18, 2024High-quality, diverse harmful data is essential to addressing real-time applications in content moderation. Current state-of-the-art approaches to toxic content detection using GPT series models are costly and lack explainability. This paper investigates the use of prompt engineering and fine-tuning techniques on open-source LLMs to enhance harmful data augmentation specifically for toxic content detection. We conduct a two-stage empirical study, with stage 1 evaluating six open-source LLMs across multiple datasets using only prompt engineering and stage 2 focusing on fine-tuning. Our findings indicate that Mistral can excel in generating harmful data with minimal hallucination. While fine-tuning these models improves data quality and diversity, challenges such as data duplication and overfitting persist. Our experimental results highlight scalable, cost-effective strategies for enhancing toxic content detection systems. These findings not only demonstrate the potential of open-source LLMs in creating robust content moderation tools. The application of this method in real industrial scenarios further proves the feasibility and efficiency of the fine-tuned open-source LLMs for data augmentation. We hope our study will aid in understanding the capabilities and limitations of current models in toxic content detection and drive further advancements in this field.
Defending Against Social Engineering Attacks in the Age of LLMs
Jun 18, 2024



The proliferation of Large Language Models (LLMs) poses challenges in detecting and mitigating digital deception, as these models can emulate human conversational patterns and facilitate chat-based social engineering (CSE) attacks. This study investigates the dual capabilities of LLMs as both facilitators and defenders against CSE threats. We develop a novel dataset, SEConvo, simulating CSE scenarios in academic and recruitment contexts, and designed to examine how LLMs can be exploited in these situations. Our findings reveal that, while off-the-shelf LLMs generate high-quality CSE content, their detection capabilities are suboptimal, leading to increased operational costs for defense. In response, we propose ConvoSentinel, a modular defense pipeline that improves detection at both the message and the conversation levels, offering enhanced adaptability and cost-effectiveness. The retrieval-augmented module in ConvoSentinel identifies malicious intent by comparing messages to a database of similar conversations, enhancing CSE detection at all stages. Our study highlights the need for advanced strategies to leverage LLMs in cybersecurity.