 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Prox: Training-Free Vision Transformer Architecture Search via Automatic Proxy Discovery
Dec 14, 2023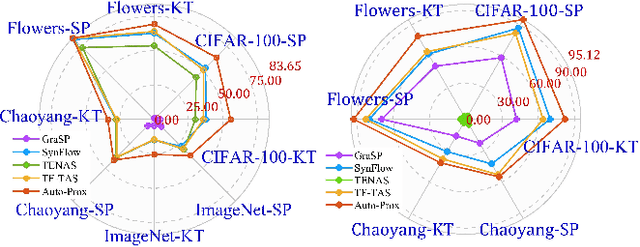
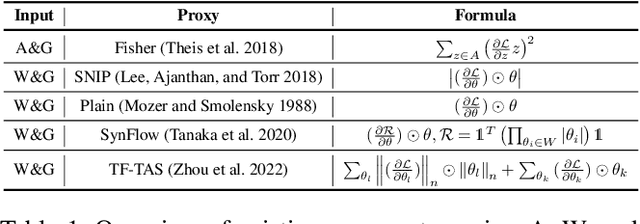
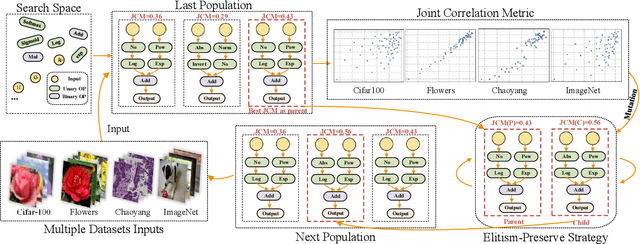
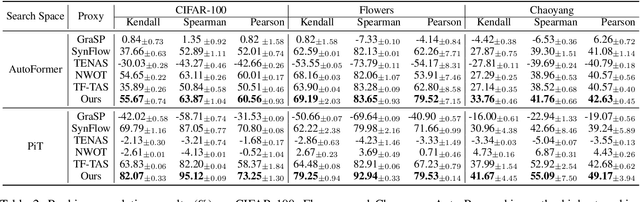
The substantial success of Vision Transformer (ViT) in computer vision tasks is largely attributed to the architecture design. This underscores the necessity of efficient architecture search for designing better ViTs automatically. As training-based architecture search methods are computationally intensive, there is a growing interest in training-free methods that use zero-cost proxies to score ViTs. However, existing training-free approaches require expert knowledge to manually design specific zero-cost proxies. Moreover, these zero-cost proxies exhibit limitations to generalize across diverse domains. In this paper, we introduce Auto-Prox, an automatic proxy discovery framework, to address the problem. First, we build the ViT-Bench-101, which involves different ViT candidates and their actual performance on multiple datasets. Utilizing ViT-Bench-101, we can evaluate zero-cost proxies based on their score-accuracy correlation. Then, we represent zero-cost proxies with computation graphs and organize the zero-cost proxy search space with ViT statistics and primitive operations. To discover generic zero-cost proxies, we propose a joint correlation metric to evolve and mutate different zero-cost proxy candidates. We introduce an elitism-preserve strategy for search efficiency to achieve a better trade-off between exploitation and exploration. Based on the discovered zero-cost proxy, we conduct a ViT architecture search in a training-free manner. Extensive experiments demonstrate that our method generalizes well to different datasets and achieves state-of-the-art results both in ranking correlation and final accuracy. Codes can be found at https://github.com/lilujunai/Auto-Prox-AAAI24.
DaMSTF: Domain Adversarial Learning Enhanced Meta Self-Training for Domain Adaptation
Aug 05, 2023



Self-training emerges as an important research line on domain adaptation. By taking the model's prediction as the pseudo labels of the unlabeled data, self-training bootstraps the model with pseudo instances in the target domain. However, the prediction errors of pseudo labels (label noise) challenge the performance of self-training. To address this problem, previous approaches only use reliable pseudo instances, i.e., pseudo instances with high prediction confidence, to retrain the model. Although these strategies effectively reduce the label noise, they are prone to miss the hard examples. In this paper, we propose a new self-training framework for domain adaptation, namely Domain adversarial learning enhanced Self-Training Framework (DaMSTF). Firstly, DaMSTF involves meta-learning to estimate the importance of each pseudo instance, so as to simultaneously reduce the label noise and preserve hard examples. Secondly, we design a meta constructor for constructing the meta-validation set, which guarantees the effectiveness of the meta-learning module by improving the quality of the meta-validation set. Thirdly, we find that the meta-learning module suffers from the training guidance vanishment and tends to converge to an inferior optimal. To this end, we employ domain adversarial learning as a heuristic neural network initialization method, which can help the meta-learning module converge to a better optimal. Theoretically and experimentally, we demonstrate the effectiveness of the proposed DaMSTF. On the cross-domain sentiment classification task, DaMSTF improves the performance of BERT with an average of nearly 4%.
Meta-Tsallis-Entropy Minimization: A New Self-Training Approach for Domain Adaptation on Text Classification
Aug 04, 2023



Text classification is a fundamental task for natural language processing, and adapting text classification models across domains has broad applications. Self-training generates pseudo-examples from the model's predictions and iteratively trains on the pseudo-examples, i.e., minimizes the loss on the source domain and the Gibbs entropy on the target domain. However, Gibbs entropy is sensitive to prediction errors, and thus, self-training tends to fail when the domain shift is large. In this paper, we propose Meta-Tsallis Entropy minimization (MTEM), which applies a meta-learning algorithm to optimize the instance adaptive Tsallis entropy on the target domain. To reduce the computation cost of MTEM, we propose an approximation technique to approximate the Second-order derivation involved in the meta-learning. To efficiently generate pseudo labels, we propose an annealing sampling mechanism for exploring the model's prediction probability. Theoretically, we prove the convergence of the meta-learning algorithm in MTEM and analyze the effectiveness of MTEM in achieving domain adaptation. Experimentally, MTEM improves the adaptation performance of BERT with an average of 4 percent on the benchmark dataset.