 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Dense, Not Long: Dynamic Decoupled Conditional Advantage for Efficient Reasoning
Feb 02, 2026Reinforcement Learning with Verifiable Rewards (RLVR) can elicit strong multi-step reasoning, yet it often encourages overly verbose traces. Moreover, naive length penalties in group-relative optimization can severely hurt accuracy. We attribute this failure to two structural issues: (i) Dilution of Length Baseline, where incorrect responses (with zero length reward) depress the group baseline and over-penalize correct solutions; and (ii) Difficulty-Penalty Mismatch, where a static penalty cannot adapt to problem difficulty, suppressing necessary reasoning on hard instances while leaving redundancy on easy ones. We propose Dynamic Decoupled Conditional Advantage (DDCA) to decouple efficiency optimization from correctness. DDCA computes length advantages conditionally within the correct-response cluster to eliminate baseline dilution, and dynamically scales the penalty strength using the group pass rate as a proxy for difficulty. Experiments on GSM8K, MATH500, AMC23, and AIME25 show that DDCA consistently improves the efficiency--accuracy trade-off relative to adaptive baselines, reducing generated tokens by approximately 60% on simpler tasks (e.g., GSM8K) versus over 20% on harder benchmarks (e.g., AIME25), thereby maintaining or improving accuracy. Code is available at https://github.com/alphadl/DDCA.
CTTA-T: Continual Test-Time Adaptation for Text Understanding via Teacher-Student with a Domain-aware and Generalized Teacher
Dec 20, 2025Text understanding often suffers from domain shifts. To handle testing domains, domain adaptation (DA) is trained to adapt to a fixed and observed testing domain; a more challenging paradigm, test-time adaptation (TTA), cannot access the testing domain during training and online adapts to the testing samples during testing, where the samples are from a fixed domain. We aim to explore a more practical and underexplored scenario, continual test-time adaptation (CTTA) for text understanding, which involves a sequence of testing (unobserved) domains in testing. Current CTTA methods struggle in reducing error accumulation over domains and enhancing generalization to handle unobserved domains: 1) Noise-filtering reduces accumulated errors but discards useful information, and 2) accumulating historical domains enhances generalization, but it is hard to achieve adaptive accumulation. In this paper, we propose a CTTA-T (continual test-time adaptation for text understanding) framework adaptable to evolving target domains: it adopts a teacher-student framework, where the teacher is domain-aware and generalized for evolving domains. To improve teacher predictions, we propose a refine-then-filter based on dropout-driven consistency, which calibrates predictions and removes unreliable guidance. For the adaptation-generalization trade-off, we construct a domain-aware teacher by dynamically accumulating cross-domain semantics via incremental PCA, which continuously tracks domain shifts. Experiments show CTTA-T excels baselines.
DPRM: A Dual Implicit Process Reward Model in Multi-Hop Question Answering
Nov 11, 2025In multi-hop question answering (MHQA) tasks, Chain of Thought (CoT) improves the quality of generation by guiding large language models (LLMs) through multi-step reasoning, and Knowledge Graphs (KGs) reduce hallucinations via semantic matching. Outcome Reward Models (ORMs) provide feedback after generating the final answers but fail to evaluate the process for multi-step reasoning. Traditional Process Reward Models (PRMs) evaluate the reasoning process but require costly human annotations or rollout generation. While implicit PRM is trained only with outcome signals and derives step rewards through reward parameterization without explicit annotations, it is more suitable for multi-step reasoning in MHQA tasks. However, existing implicit PRM has only been explored for plain text scenarios. When adapting to MHQA tasks, it cannot handle the graph structure constraints in KGs and capture the potential inconsistency between CoT and KG paths. To address these limitations, we propose the DPRM (Dual Implicit Process Reward Model). It trains two implicit PRMs for CoT and KG reasoning in MHQA tasks. Both PRMs, namely KG-PRM and CoT-PRM, derive step-level rewards from outcome signals via reward parameterization without additional explicit annotations. Among them, KG-PRM uses preference pairs to learn structural constraints from KGs. DPRM further introduces a consistency constraint between CoT and KG reasoning steps, making the two PRMs mutually verify and collaboratively optimize the reasoning paths. We also provide a theoretical demonstration of the derivation of process rewards. Experimental results show that our method outperforms 13 baselines on multiple datasets with up to 16.6% improvement on Hit@1.
RLJP: Legal Judgment Prediction via First-Order Logic Rule-enhanced with Large Language Models
May 27, 2025Legal Judgment Prediction (LJP) is a pivotal task in legal AI. Existing semantic-enhanced LJP models integrate judicial precedents and legal knowledge for high performance. But they neglect legal reasoning logic, a critical component of legal judgments requiring rigorous logical analysis. Although some approaches utilize legal reasoning logic for high-quality predictions, their logic rigidity hinders adaptation to case-specific logical frameworks, particularly in complex cases that are lengthy and detailed. This paper proposes a rule-enhanced legal judgment prediction framework based on first-order logic (FOL) formalism and comparative learning (CL) to develop an adaptive adjustment mechanism for legal judgment logic and further enhance performance in LJP. Inspired by the process of human exam preparation, our method follows a three-stage approach: first, we initialize judgment rules using the FOL formalism to capture complex reasoning logic accurately; next, we propose a Confusion-aware Contrastive Learning (CACL) to dynamically optimize the judgment rules through a quiz consisting of confusable cases; finally, we utilize the optimized judgment rules to predict legal judgments. Experimental results on two public datasets show superior performance across all metrics. The code is publicly available{https://anonymous.4open.science/r/RLJP-FDF1}.
Zero-resource Hallucination Detection for Text Generation via Graph-based Contextual Knowledge Triples Modeling
Sep 18, 2024



LLMs obtain remarkable performance but suffer from hallucinations. Most research on detecting hallucination focuses on the questions with short and concrete correct answers that are easy to check the faithfulness. Hallucination detections for text generation with open-ended answers are more challenging. Some researchers use external knowledge to detect hallucinations in generated texts, but external resources for specific scenarios are hard to access. Recent studies on detecting hallucinations in long text without external resources conduct consistency comparison among multiple sampled outputs. To handle long texts, researchers split long texts into multiple facts and individually compare the consistency of each pairs of facts. However, these methods (1) hardly achieve alignment among multiple facts; (2) overlook dependencies between multiple contextual facts. In this paper, we propose a graph-based context-aware (GCA) hallucination detection for text generations, which aligns knowledge facts and considers the dependencies between contextual knowledge triples in consistency comparison. Particularly, to align multiple facts, we conduct a triple-oriented response segmentation to extract multiple knowledge triples. To model dependencies among contextual knowledge triple (facts), we construct contextual triple into a graph and enhance triples' interactions via message passing and aggregating via RGCN. To avoid the omission of knowledge triples in long text, we conduct a LLM-based reverse verification via reconstructing the knowledge triples. Experiments show that our model enhances hallucination detection and excels all baselines.
Perception of Knowledge Boundary for Large Language Models through Semi-open-ended Question Answering
May 23, 2024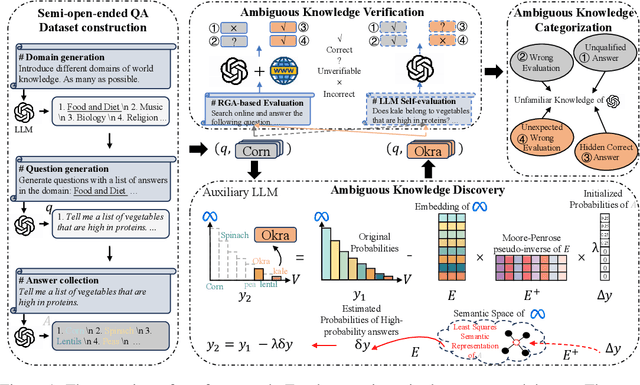
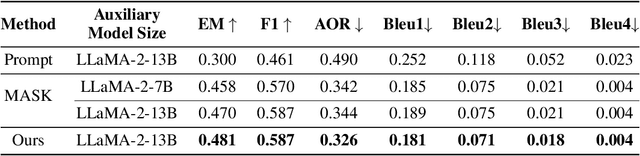
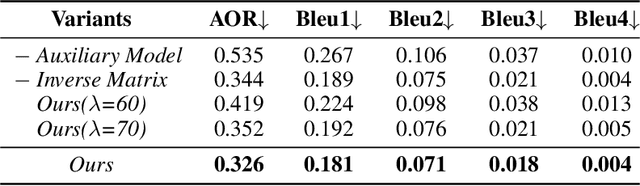
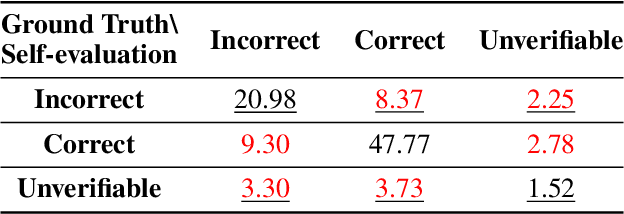
Large Language Models (LLMs) are widely used for knowledge-seeking yet suffer from hallucinations. The knowledge boundary (KB) of an LLM limits its factual understanding, beyond which it may begin to hallucinate. Investigating the perception of LLMs' KB is crucial for detecting hallucinations and LLMs' reliable generation. Current studies perceive LLMs' KB on questions with a concrete answer (close-ended questions) while paying limited attention to semi-open-ended questions (SoeQ) that correspond to many potential answers. Some researchers achieve it by judging whether the question is answerable or not. However, this paradigm is unsuitable for SoeQ, which are usually partially answerable, containing both answerable and ambiguous (unanswerable) answers. Ambiguous answers are essential for knowledge-seeking, but they may go beyond the KB of LLMs. In this paper, we perceive the LLMs' KB with SoeQ by discovering more ambiguous answers. First, we apply an LLM-based approach to construct SoeQ and obtain answers from a target LLM. Unfortunately, the output probabilities of mainstream black-box LLMs are inaccessible to sample for low-probability ambiguous answers. Therefore, we apply an open-sourced auxiliary model to explore ambiguous answers for the target LLM. We calculate the nearest semantic representation for existing answers to estimate their probabilities, with which we reduce the generation probability of high-probability answers to achieve a more effective generation. Finally, we compare the results from the RAG-based evaluation and LLM self-evaluation to categorize four types of ambiguous answers that are beyond the KB of the target LLM. Following our method, we construct a dataset to perceive the KB for GPT-4. We find that GPT-4 performs poorly on SoeQ and is often unaware of its KB. Besides, our auxiliary model, LLaMA-2-13B, is effective in discovering more ambiguous answers.
LTOS: Layout-controllable Text-Object Synthesis via Adaptive Cross-attention Fusions
Apr 21, 2024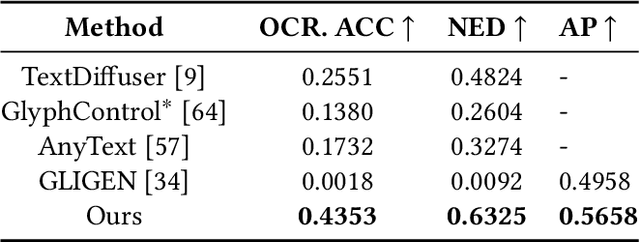
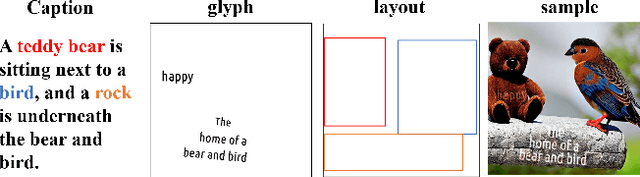


Controllable text-to-image generation synthesizes visual text and objects in images with certain conditions, which are frequently applied to emoji and poster generation. Visual text rendering and layout-to-image generation tasks have been popular in controllable text-to-image generation. However, each of these tasks typically focuses on single modality generation or rendering, leaving yet-to-be-bridged gaps between the approaches correspondingly designed for each of the tasks. In this paper, we combine text rendering and layout-to-image generation tasks into a single task: layout-controllable text-object synthesis (LTOS) task, aiming at synthesizing images with object and visual text based on predefined object layout and text contents. As compliant datasets are not readily available for our LTOS task, we construct a layout-aware text-object synthesis dataset, containing elaborate well-aligned labels of visual text and object information. Based on the dataset, we propose a layout-controllable text-object adaptive fusion (TOF) framework, which generates images with clear, legible visual text and plausible objects. We construct a visual-text rendering module to synthesize text and employ an object-layout control module to generate objects while integrating the two modules to harmoniously generate and integrate text content and objects in images. To better the image-text integration, we propose a self-adaptive cross-attention fusion module that helps the image generation to attend more to important text information. Within such a fusion module, we use a self-adaptive learnable factor to learn to flexibly control the influence of cross-attention outputs on image generation. Experimental results show that our method outperforms the state-of-the-art in LTOS, text rendering, and layout-to-image tasks, enabling harmonious visual text rendering and object generation.
360°REA: Towards A Reusable Experience Accumulation with 360° Assessment for Multi-Agent System
Apr 08, 2024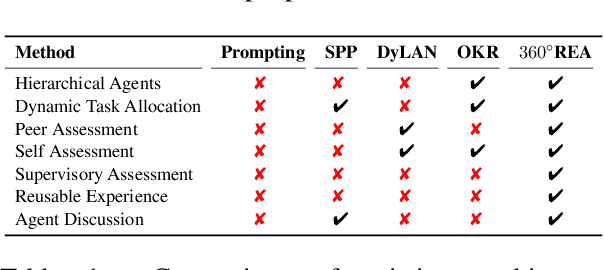
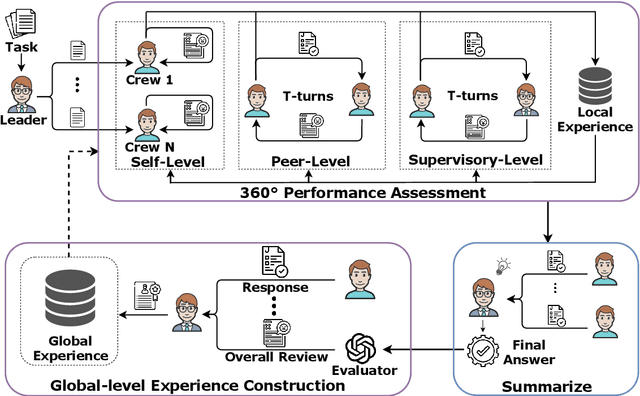
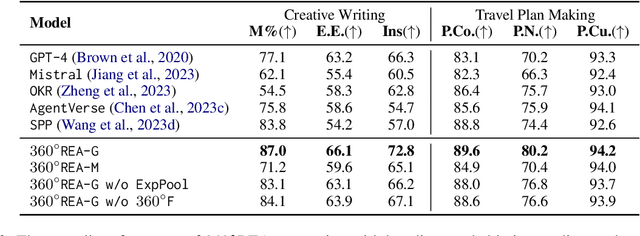
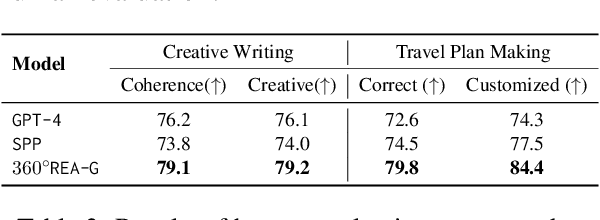
Large language model agents have demonstrated remarkable advancements across various complex tasks. Recent works focus on optimizing the agent team or employing self-reflection to iteratively solve complex tasks. Since these agents are all based on the same LLM, only conducting self-evaluation or removing underperforming agents does not substantively enhance the capability of the agents. We argue that a comprehensive evaluation and accumulating experience from evaluation feedback is an effective approach to improving system performance. In this paper, we propose Reusable Experience Accumulation with 360{\deg} Assessment (360{\deg}REA), a hierarchical multi-agent framework inspired by corporate organizational practices. The framework employs a novel 360{\deg} performance assessment method for multi-perspective performance evaluation with fine-grained assessment. To enhance the capability of agents in addressing complex tasks, we introduce dual-level experience pool for agents to accumulate experience through fine-grained assessment. Extensive experiments on complex task datasets demonstrate the effectiveness of 360{\deg}REA.
Learn to Disguise: Avoid Refusal Responses in LLM's Defense via a Multi-agent Attacker-Disguiser Game
Apr 03, 2024



With the enhanced performance of large models on natural language processing tasks, potential moral and ethical issues of large models arise. There exist malicious attackers who induce large models to jailbreak and generate information containing illegal, privacy-invasive information through techniques such as prompt engineering. As a result, large models counter malicious attackers' attacks using techniques such as safety alignment. However, the strong defense mechanism of the large model through rejection replies is easily identified by attackers and used to strengthen attackers' capabilities. In this paper, we propose a multi-agent attacker-disguiser game approach to achieve a weak defense mechanism that allows the large model to both safely reply to the attacker and hide the defense intent. First, we construct a multi-agent framework to simulate attack and defense scenarios, playing different roles to be responsible for attack, disguise, safety evaluation, and disguise evaluation tasks. After that, we design attack and disguise game algorithms to optimize the game strategies of the attacker and the disguiser and use the curriculum learning process to strengthen the capabilities of the agents. The experiments verify that the method in this paper is more effective in strengthening the model's ability to disguise the defense intent compared with other methods. Moreover, our approach can adapt any black-box large model to assist the model in defense and does not suffer from model version iterations.
LLM-based Privacy Data Augmentation Guided by Knowledge Distillation with a Distribution Tutor for Medical Text Classification
Feb 26, 2024



As sufficient data are not always publically accessible for model training, researchers exploit limited data with advanced learning algorithms or expand the dataset via data augmentation (DA). Conducting DA in private domain requires private protection approaches (i.e. anonymization and perturbation), but those methods cannot provide protection guarantees. Differential privacy (DP) learning methods theoretically bound the protection but are not skilled at generating pseudo text samples with large models. In this paper, we transfer DP-based pseudo sample generation task to DP-based generated samples discrimination task, where we propose a DP-based DA method with a LLM and a DP-based discriminator for text classification on private domains. We construct a knowledge distillation model as the DP-based discriminator: teacher models, accessing private data, teaches students how to select private samples with calibrated noise to achieve DP. To constrain the distribution of DA's generation, we propose a DP-based tutor that models the noised private distribution and controls samples' generation with a low privacy cost. We theoretically analyze our model's privacy protection and empirically verify our model.