 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlloc-MoE: Budget-Aware Expert Activation Allocation for Efficient Mixture-of-Experts Inference
Apr 09, 2026Mixture-of-Experts (MoE) has become a dominant architecture for scaling large language models due to their sparse activation mechanism. However, the substantial number of expert activations creates a critical latency bottleneck during inference, especially in resource-constrained deployment scenarios. Existing approaches that reduce expert activations potentially lead to severe model performance degradation. In this work, we introduce the concept of \emph{activation budget} as a constraint on the number of expert activations and propose Alloc-MoE, a unified framework that optimizes budget allocation coordinately at both the layer and token levels to minimize performance degradation. At the layer level, we introduce Alloc-L, which leverages sensitivity profiling and dynamic programming to determine the optimal allocation of expert activations across layers. At the token level, we propose Alloc-T, which dynamically redistributes activations based on routing scores, optimizing budget allocation without increasing latency. Extensive experiments across multiple MoE models demonstrate that Alloc-MoE maintains model performance under a constrained activation budget. Especially, Alloc-MoE achieves $1.15\times$ prefill and $1.34\times$ decode speedups on DeepSeek-V2-Lite at half of the original budget.
GRASS: Gradient-based Adaptive Layer-wise Importance Sampling for Memory-efficient Large Language Model Fine-tuning
Apr 09, 2026Full-parameter fine-tuning of large language models is constrained by substantial GPU memory requirements. Low-rank adaptation methods mitigate this challenge by updating only a subset of parameters. However, these approaches often limit model expressiveness and yield lower performance than full-parameter fine-tuning. Layer-wise fine-tuning methods have emerged as an alternative, enabling memory-efficient training through static layer importance sampling strategies. However, these methods overlook variations in layer importance across tasks and training stages, resulting in suboptimal performance on downstream tasks. To address these limitations, we propose GRASS, a gradient-based adaptive layer-wise importance sampling framework. GRASS utilizes mean gradient norms as a task-aware and training-stage-aware metric for estimating layer importance. Furthermore, GRASS adaptively adjusts layer sampling probabilities through an adaptive training strategy. We also introduce a layer-wise optimizer state offloading mechanism that overlaps computation and communication to further reduce memory usage while maintaining comparable training throughput. Extensive experiments across multiple models and benchmarks demonstrate that GRASS consistently outperforms state-of-the-art methods, achieving an average accuracy improvement of up to 4.38 points and reducing memory usage by up to 19.97\%.
Let the Agent Search: Autonomous Exploration Beats Rigid Workflows in Temporal Question Answering
Mar 02, 2026Temporal Knowledge Graph Question Answering (TKGQA) demands multi-hop reasoning under temporal constraints. Prior approaches based on large language models (LLMs) typically rely on rigid, hand-crafted retrieval workflows or costly supervised fine-tuning. We show that simply granting an off-the-shelf LLM autonomy, that is, letting it decide what to do next, already yields substantial gains even in a strict zero-shot setting. Building on this insight, we propose AT2QA, an autonomous, training-free agent for temporal question answering that iteratively interacts with the temporal knowledge graph via a general search tool for dynamic retrieval. Experiments on MultiTQ demonstrate large improvements: AT2QA achieves 88.7% Hits@1 (+10.7% over prior SOTA), including a +20.1% gain on challenging multi-target queries, showing that agentic autonomy can decisively outperform fine-tuning for temporal question answering. Code and the full set of sampled trajectories are available on https://github.com/AT2QA-Official-Code/AT2QA-Official-Code
ParaDySe: A Parallel-Strategy Switching Framework for Dynamic Sequence Lengths in Transformer
Nov 17, 2025Dynamic sequences with varying lengths have been widely used in the training of Transformer-based large language models (LLMs). However, current training frameworks adopt a pre-defined static parallel strategy for these sequences, causing neither communication-parallelization cancellation on short sequences nor out-of-memory on long sequences. To mitigate these issues, we propose ParaDySe, a novel adaptive Parallel strategy switching framework for Dynamic Sequences. ParaDySe enables on-the-fly optimal strategy adoption according to the immediate input sequence. It first implements the modular function libraries for parallel strategies with unified tensor layout specifications, and then builds sequence-aware memory and time cost models with hybrid methods. Guided by cost models, ParaDySe selects optimal layer-wise strategies for dynamic sequences via an efficient heuristic algorithm. By integrating these techniques together, ParaDySe achieves seamless hot-switching of optimal strategies through its well-designed function libraries. We compare ParaDySe with baselines on representative LLMs under datasets with sequence lengths up to 624K. Experimental results indicate that ParaDySe addresses OOM and CPC bottlenecks in LLM training by systematically integrating long-sequence optimizations with existing frameworks.
A Survey on Memory-Efficient Large-Scale Model Training in AI for Science
Jan 21, 2025



Scientific research faces high costs and inefficiencies with traditional methods, but the rise of deep learning and large language models (LLMs) offers innovative solutions. This survey reviews LLM applications across scientific fields such as biology, medicine, chemistry, and meteorology, underscoring their role in advancing research. However, the continuous expansion of model size has led to significant memory demands, hindering further development and application of LLMs for science. To address this, we review memory-efficient training techniques for LLMs based on the transformer architecture, including distributed training, mixed precision training, and gradient checkpointing. Using AlphaFold 2 as an example, we demonstrate how tailored memory optimization methods can reduce storage needs while preserving prediction accuracy. We also discuss the challenges of memory optimization in practice and potential future directions, hoping to provide valuable insights for researchers and engineers.
Two-stage Generative Question Answering on Temporal Knowledge Graph Using Large Language Models
Feb 26, 2024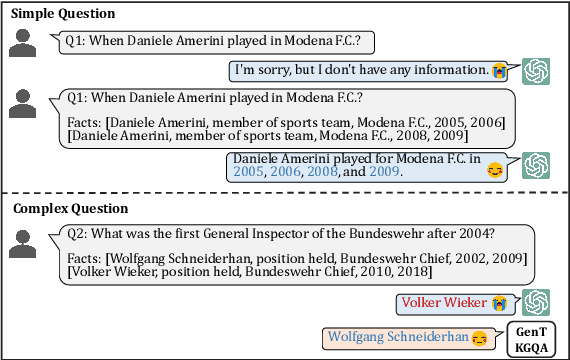
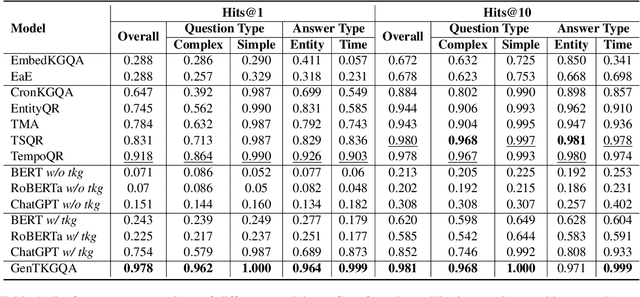
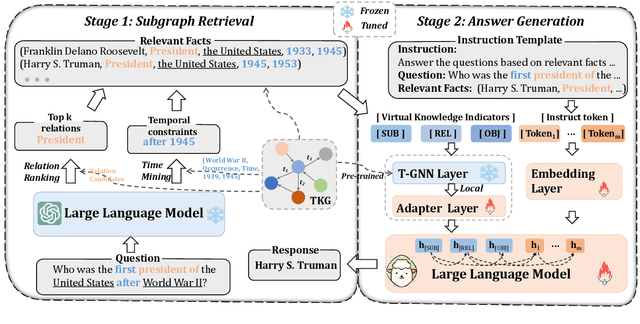
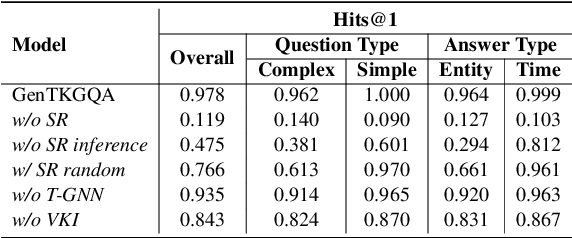
Temporal knowledge graph question answering (TKGQA) poses a significant challenge task, due to the temporal constraints hidden in questions and the answers sought from dynamic structured knowledge. Although large language models (LLMs) have made considerable progress in their reasoning ability over structured data, their application to the TKGQA task is a relatively unexplored area. This paper first proposes a novel generative temporal knowledge graph question answering framework, GenTKGQA, which guides LLMs to answer temporal questions through two phases: Subgraph Retrieval and Answer Generation. First, we exploit LLM's intrinsic knowledge to mine temporal constraints and structural links in the questions without extra training, thus narrowing down the subgraph search space in both temporal and structural dimensions. Next, we design virtual knowledge indicators to fuse the graph neural network signals of the subgraph and the text representations of the LLM in a non-shallow way, which helps the open-source LLM deeply understand the temporal order and structural dependencies among the retrieved facts through instruction tuning. Experimental results demonstrate that our model outperforms state-of-the-art baselines, even achieving 100\% on the metrics for the simple question type.
TFDMNet: A Novel Network Structure Combines the Time Domain and Frequency Domain Features
Jan 29, 2024Convolutional neural network (CNN) has achieved impressive success in computer vision during the past few decades. The image convolution operation helps CNNs to get good performance on image-related tasks. However, it also has high computation complexity and hard to be parallelized. This paper proposes a novel Element-wise Multiplication Layer (EML) to replace convolution layers, which can be trained in the frequency domain. Theoretical analyses show that EMLs lower the computation complexity and easier to be parallelized. Moreover, we introduce a Weight Fixation mechanism to alleviate the problem of over-fitting, and analyze the working behavior of Batch Normalization and Dropout in the frequency domain. To get the balance between the computation complexity and memory usage, we propose a new network structure, namely Time-Frequency Domain Mixture Network (TFDMNet), which combines the advantages of both convolution layers and EMLs. Experimental results imply that TFDMNet achieves good performance on MNIST, CIFAR-10 and ImageNet databases with less number of operations comparing with corresponding CNNs.
A Unified Generative Framework based on Prompt Learning for Various Information Extraction Tasks
Sep 23, 2022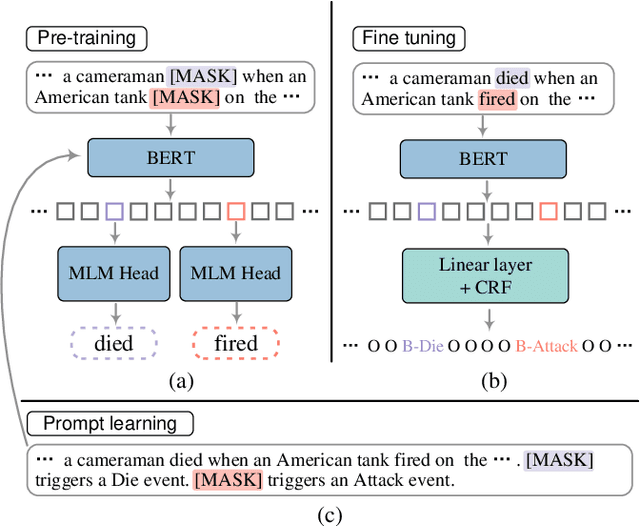
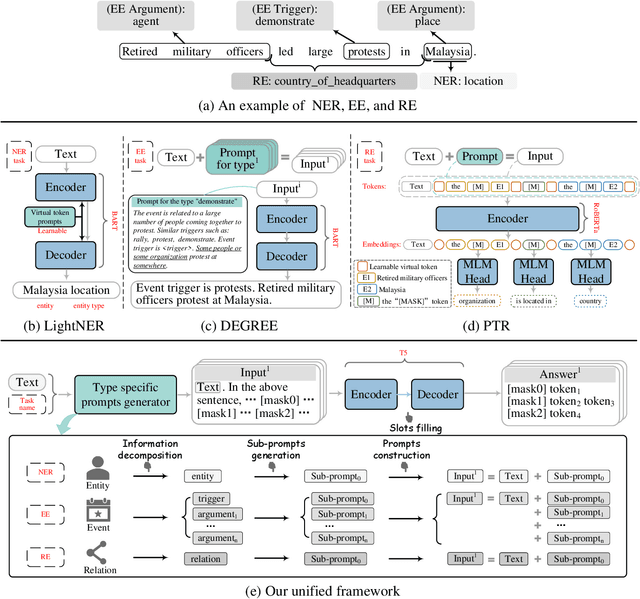
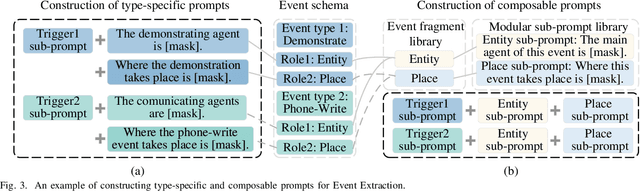
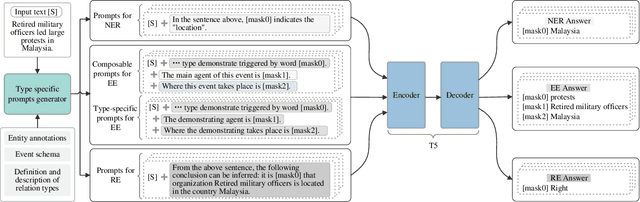
Prompt learning is an effective paradigm that bridges gaps between the pre-training tasks and the corresponding downstream applications. Approaches based on this paradigm have achieved great transcendent results in various applications. However, it still needs to be answered how to design a unified framework based on the prompt learning paradigm for various information extraction tasks. In this paper, we propose a novel composable prompt-based generative framework, which could be applied to a wide range of tasks in the field of Information Extraction. Specifically, we reformulate information extraction tasks into the form of filling slots in pre-designed type-specific prompts, which consist of one or multiple sub-prompts. A strategy of constructing composable prompts is proposed to enhance the generalization ability to extract events in data-scarce scenarios. Furthermore, to fit this framework, we transform Relation Extraction into the task of determining semantic consistency in prompts. The experimental results demonstrate that our approach surpasses compared baselines on real-world datasets in data-abundant and data-scarce scenarios. Further analysis of the proposed framework is presented, as well as numerical experiments conducted to investigate impact factors of performance on various tasks.
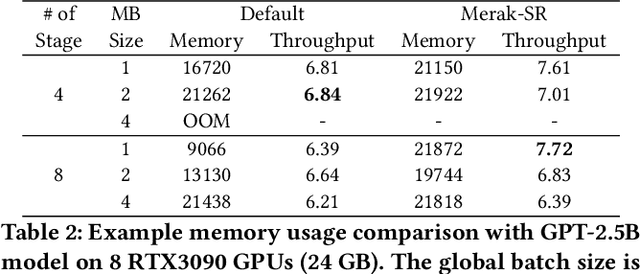
Merak: An Efficient Distributed DNN Training Framework with Automated 3D Parallelism for Giant Foundation Models
Jun 21, 2022
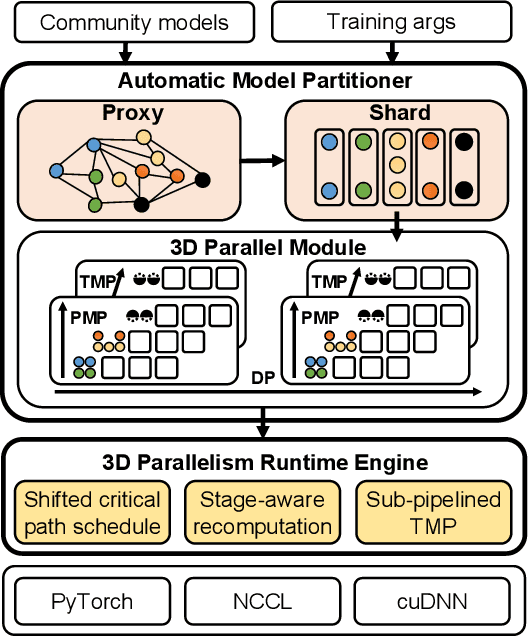

Foundation models are becoming the dominant deep learning technologies. Pretraining a foundation model is always time-consumed due to the large scale of both the model parameter and training dataset. Besides being computing-intensive, the training process is extremely memory-intensive and communication-intensive. These features make it necessary to apply 3D parallelism, which integrates data parallelism, pipeline model parallelism and tensor model parallelism, to achieve high training efficiency. To achieve this goal, some custom software frameworks such as Megatron-LM and DeepSpeed are developed. However, current 3D parallelism frameworks still meet two issues: i) they are not transparent to model developers, which need to manually modify the model to parallelize training. ii) their utilization of computation, GPU memory and network bandwidth are not sufficient. We propose Merak, an automated 3D parallelism deep learning training framework with high resource utilization. Merak automatically deploys with an automatic model partitioner, which uses a graph sharding algorithm on a proxy representation of the model. Merak also presents the non-intrusive API for scaling out foundation model training with minimal code modification. In addition, we design a high-performance 3D parallel runtime engine in Merak. It uses several techniques to exploit available training resources, including shifted critical path pipeline schedule that brings a higher computation utilization, stage-aware recomputation that makes use of idle worker memory, and sub-pipelined tensor model parallelism that overlaps communication and computation. Experiments on 64 GPUs show Merak can speedup the training performance over the state-of-the-art 3D parallelism frameworks of models with 1.5, 2.5, 8.3, and 20 billion parameters by up to 1.42X, 1.39X, 1.43X, and 1.61X, respectively.
DELTA: Dynamically Optimizing GPU Memory beyond Tensor Recomputation
Mar 30, 2022

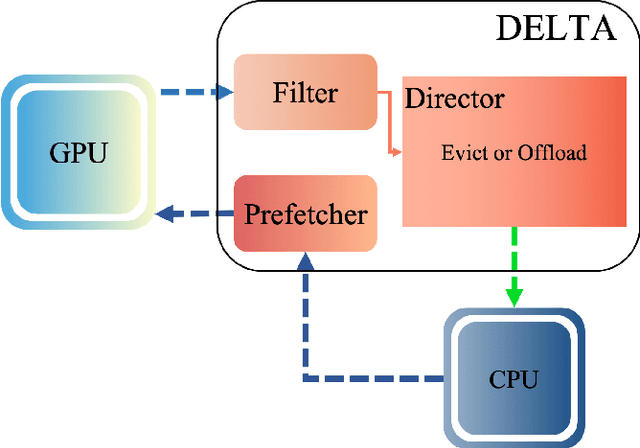
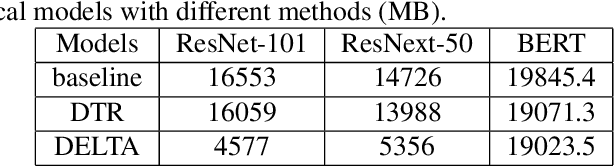
The further development of deep neural networks is hampered by the limited GPU memory resource. Therefore, the optimization of GPU memory resources is highly demanded. Swapping and recomputation are commonly applied to make better use of GPU memory in deep learning. However, as an emerging domain, several challenges remain:1)The efficiency of recomputation is limited for both static and dynamic methods. 2)Swapping requires offloading parameters manually, which incurs a great time cost. 3) There is no such dynamic and fine-grained method that involves tensor swapping together with tensor recomputation nowadays. To remedy the above issues, we propose a novel scheduler manager named DELTA(Dynamic tEnsor offLoad and recompuTAtion). To the best of our knowledge, we are the first to make a reasonable dynamic runtime scheduler on the combination of tensor swapping and tensor recomputation without user oversight. In DELTA, we propose a filter algorithm to select the optimal tensors to be released out of GPU memory and present a director algorithm to select a proper action for each of these tensors. Furthermore, prefetching and overlapping are deliberately considered to overcome the time cost caused by swapping and recomputing tensors. Experimental results show that DELTA not only saves 40%-70% of GPU memory, surpassing the state-of-the-art method to a great extent but also gets comparable convergence results as the baseline with acceptable time delay. Also, DELTA gains 2.04$\times$ maximum batchsize when training ResNet-50 and 2.25$\times$ when training ResNet-101 compared with the baseline. Besides, comparisons between the swapping cost and recomputation cost in our experiments demonstrate the importance of making a reasonable dynamic scheduler on tensor swapping and tensor recomputation, which refutes the arguments in some related work that swapping should be the first and best choice.