 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerak: An Efficient Distributed DNN Training Framework with Automated 3D Parallelism for Giant Foundation Models
Jun 21, 2022
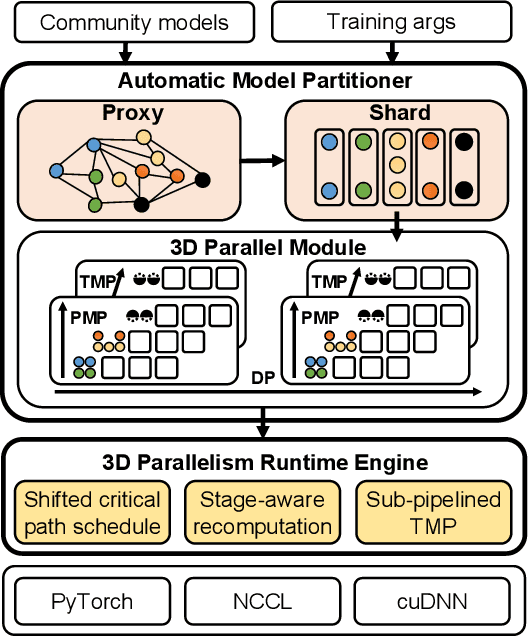

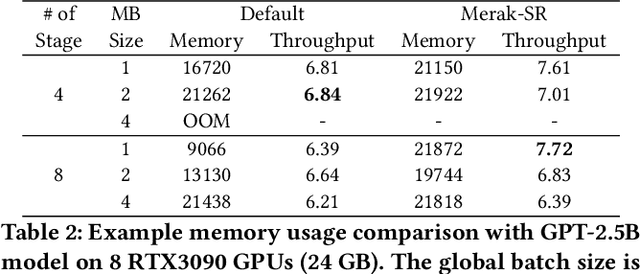
Foundation models are becoming the dominant deep learning technologies. Pretraining a foundation model is always time-consumed due to the large scale of both the model parameter and training dataset. Besides being computing-intensive, the training process is extremely memory-intensive and communication-intensive. These features make it necessary to apply 3D parallelism, which integrates data parallelism, pipeline model parallelism and tensor model parallelism, to achieve high training efficiency. To achieve this goal, some custom software frameworks such as Megatron-LM and DeepSpeed are developed. However, current 3D parallelism frameworks still meet two issues: i) they are not transparent to model developers, which need to manually modify the model to parallelize training. ii) their utilization of computation, GPU memory and network bandwidth are not sufficient. We propose Merak, an automated 3D parallelism deep learning training framework with high resource utilization. Merak automatically deploys with an automatic model partitioner, which uses a graph sharding algorithm on a proxy representation of the model. Merak also presents the non-intrusive API for scaling out foundation model training with minimal code modification. In addition, we design a high-performance 3D parallel runtime engine in Merak. It uses several techniques to exploit available training resources, including shifted critical path pipeline schedule that brings a higher computation utilization, stage-aware recomputation that makes use of idle worker memory, and sub-pipelined tensor model parallelism that overlaps communication and computation. Experiments on 64 GPUs show Merak can speedup the training performance over the state-of-the-art 3D parallelism frameworks of models with 1.5, 2.5, 8.3, and 20 billion parameters by up to 1.42X, 1.39X, 1.43X, and 1.61X, respectively.
EmbRace: Accelerating Sparse Communication for Distributed Training of NLP Neural Networks
Oct 18, 2021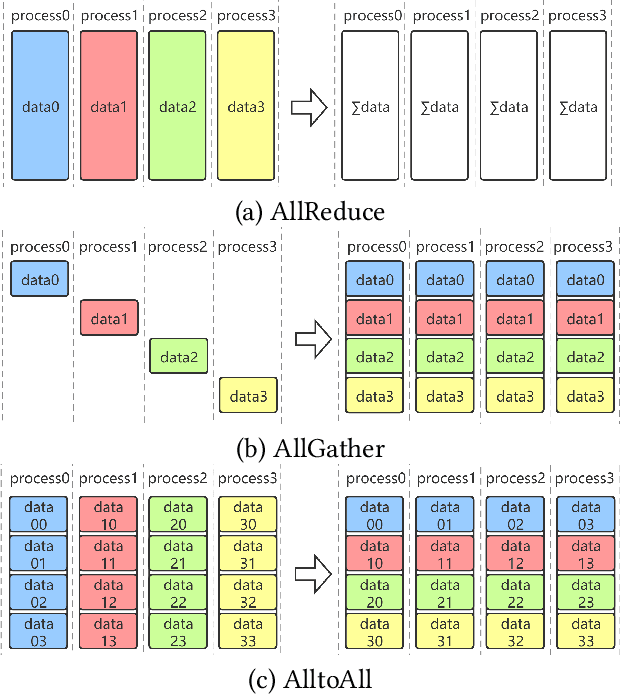
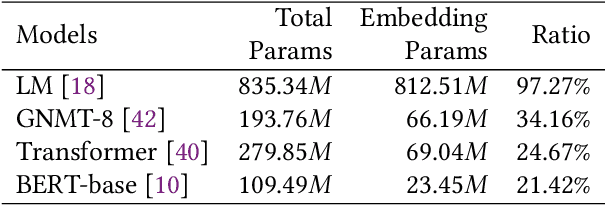
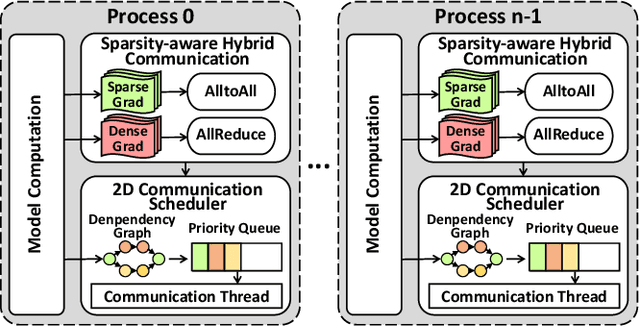
Distributed data-parallel training has been widely used for natural language processing (NLP) neural network models. However, the embedding tables in NLP models, holding a large portion of parameters and bringing dramatic sparsity in communication, make it a big challenge to efficiently scale the distributed training. Current distributed training frameworks mainly concentrate on dense models but neglect the sparsity of NLP models, resulting in significant communication overhead and relatively poor scalability. In this paper, we propose EmbRace, an efficient communication framework designed to accelerate sparse communication of distributed NLP model training. EmbRace introduces Sparsity-aware Hybrid Communication, which combines AlltoAll and AllReduce to optimize the communication overhead for sparse and dense data in NLP models. EmbRace further introduces a 2D Communication Scheduling approach to thoroughly overlap communication with computation by optimizing model computation procedure, relaxing the dependency of embeddings, and scheduling communication with a priority queue. We implement EmbRace based on PyTorch and Horovod, and conduct comprehensive evaluations with four representative NLP models on two high-performance GPU clusters. Experimental results show that EmbRace achieves up to 30.66X speedup on 16 GPUs clusters among four popular distributed training baselines.