 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbRace: Accelerating Sparse Communication for Distributed Training of NLP Neural Networks
Oct 18, 2021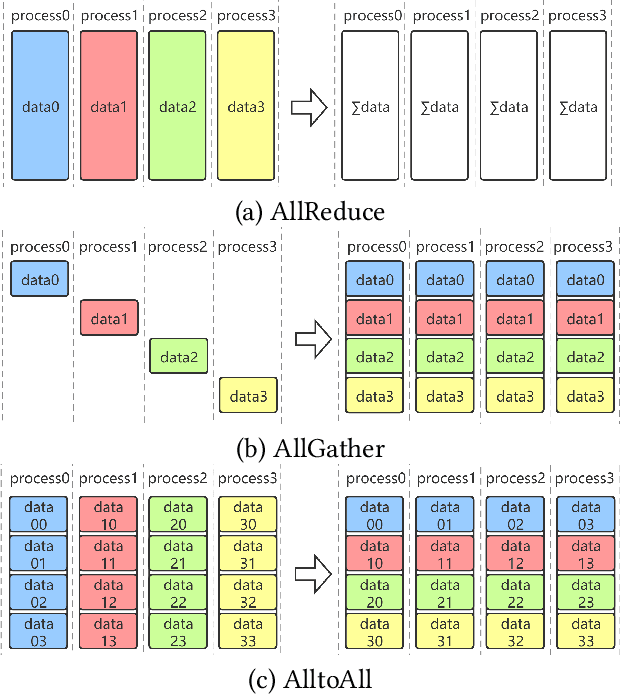
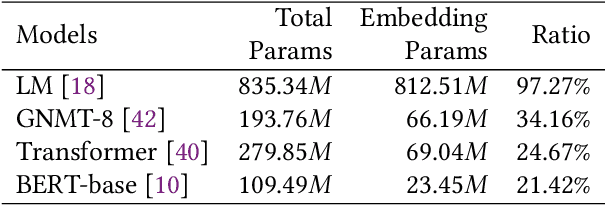
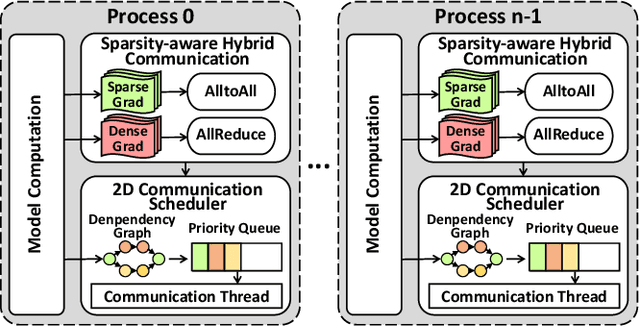
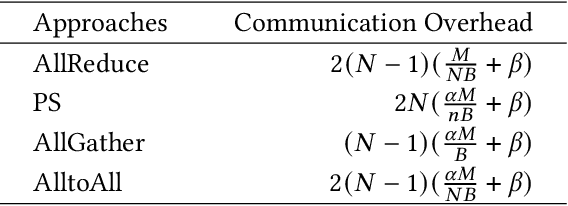
Distributed data-parallel training has been widely used for natural language processing (NLP) neural network models. However, the embedding tables in NLP models, holding a large portion of parameters and bringing dramatic sparsity in communication, make it a big challenge to efficiently scale the distributed training. Current distributed training frameworks mainly concentrate on dense models but neglect the sparsity of NLP models, resulting in significant communication overhead and relatively poor scalability. In this paper, we propose EmbRace, an efficient communication framework designed to accelerate sparse communication of distributed NLP model training. EmbRace introduces Sparsity-aware Hybrid Communication, which combines AlltoAll and AllReduce to optimize the communication overhead for sparse and dense data in NLP models. EmbRace further introduces a 2D Communication Scheduling approach to thoroughly overlap communication with computation by optimizing model computation procedure, relaxing the dependency of embeddings, and scheduling communication with a priority queue. We implement EmbRace based on PyTorch and Horovod, and conduct comprehensive evaluations with four representative NLP models on two high-performance GPU clusters. Experimental results show that EmbRace achieves up to 30.66X speedup on 16 GPUs clusters among four popular distributed training baselines.