 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstrea: A MOE-based Visual Understanding Model with Progressive Alignment
Mar 12, 2025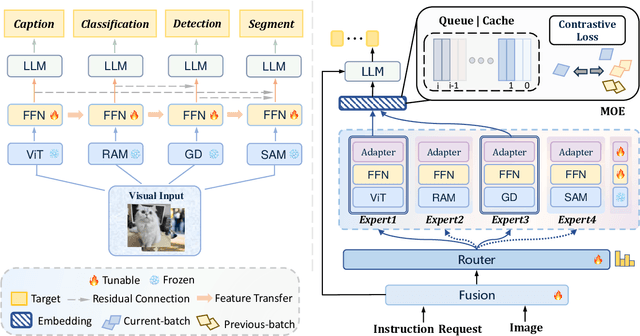
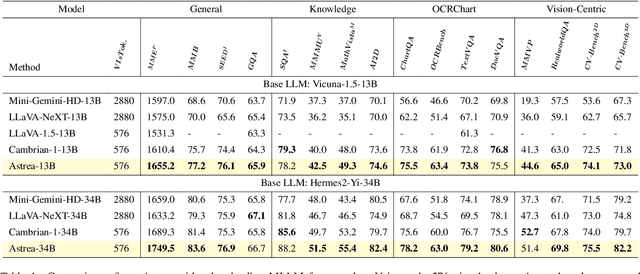
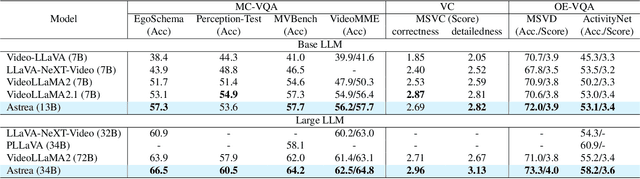
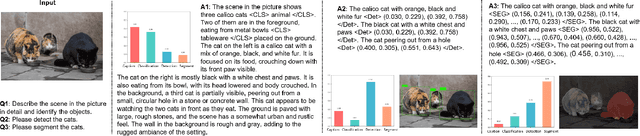
Vision-Language Models (VLMs) based on Mixture-of-Experts (MoE) architectures have emerged as a pivotal paradigm in multimodal understanding, offering a powerful framework for integrating visual and linguistic information. However, the increasing complexity and diversity of tasks present significant challenges in coordinating load balancing across heterogeneous visual experts, where optimizing one specialist's performance often compromises others' capabilities. To address task heterogeneity and expert load imbalance, we propose Astrea, a novel multi-expert collaborative VLM architecture based on progressive pre-alignment. Astrea introduces three key innovations: 1) A heterogeneous expert coordination mechanism that integrates four specialized models (detection, segmentation, classification, captioning) into a comprehensive expert matrix covering essential visual comprehension elements; 2) A dynamic knowledge fusion strategy featuring progressive pre-alignment to harmonize experts within the VLM latent space through contrastive learning, complemented by probabilistically activated stochastic residual connections to preserve knowledge continuity; 3) An enhanced optimization framework utilizing momentum contrastive learning for long-range dependency modeling and adaptive weight allocators for real-time expert contribution calibration. Extensive evaluations across 12 benchmark tasks spanning VQA, image captioning, and cross-modal retrieval demonstrate Astrea's superiority over state-of-the-art models, achieving an average performance gain of +4.7\%. This study provides the first empirical demonstration that progressive pre-alignment strategies enable VLMs to overcome task heterogeneity limitations, establishing new methodological foundations for developing general-purpose multimodal agents.
Human Limits in Machine Learning: Prediction of Plant Phenotypes Using Soil Microbiome Data
Jun 19, 2023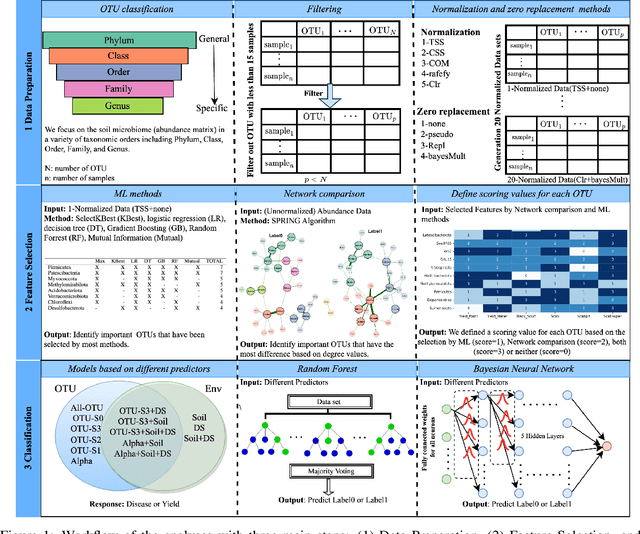



The preservation of soil health has been identified as one of the main challenges of the XXI century given its vast (and potentially threatening) ramifications in agriculture, human health and biodiversity. Here, we provide the first deep investigation of the predictive potential of machine-learning models to understand the connections between soil and biological phenotypes. Indeed, we investigate an integrative framework performing accurate machine-learning-based prediction of plant phenotypes from biological, chemical and physical properties of the soil via two models: random forest and Bayesian neural network. We show that prediction is improved, as evidenced by higher weighted F1 scores, when incorporating into the models environmental features like soil physicochemical properties and microbial population density in addition to the microbiome information. Furthermore, by exploring multiple data preprocessing strategies such as normalization, zero replacement, and data augmentation, we confirm that human decisions have a huge impact on the predictive performance. In particular, we show that the naive total sum scaling normalization that is commonly used in microbiome research is not the optimal strategy to maximize predictive power. In addition, we find that accurately defined labels are more important than normalization, taxonomic level or model characteristics. That is, if humans are unable to classify the samples and provide accurate labels, the performance of machine-learning models will be limited. Lastly, we present strategies for domain scientists via a full model selection decision tree to identify the human choices that maximize the prediction power of the models. Our work is accompanied by open source reproducible scripts (https://github.com/solislemuslab/soil-microbiome-nn) for maximum outreach among the microbiome research community.
Merak: An Efficient Distributed DNN Training Framework with Automated 3D Parallelism for Giant Foundation Models
Jun 21, 2022
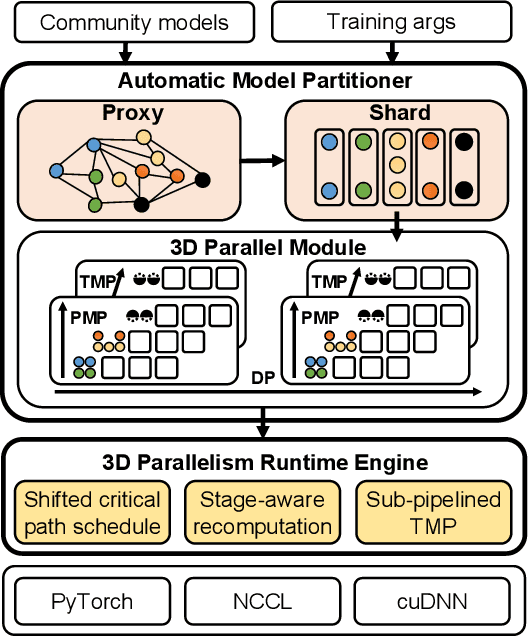

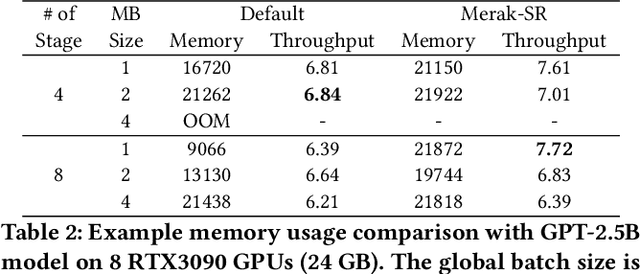
Foundation models are becoming the dominant deep learning technologies. Pretraining a foundation model is always time-consumed due to the large scale of both the model parameter and training dataset. Besides being computing-intensive, the training process is extremely memory-intensive and communication-intensive. These features make it necessary to apply 3D parallelism, which integrates data parallelism, pipeline model parallelism and tensor model parallelism, to achieve high training efficiency. To achieve this goal, some custom software frameworks such as Megatron-LM and DeepSpeed are developed. However, current 3D parallelism frameworks still meet two issues: i) they are not transparent to model developers, which need to manually modify the model to parallelize training. ii) their utilization of computation, GPU memory and network bandwidth are not sufficient. We propose Merak, an automated 3D parallelism deep learning training framework with high resource utilization. Merak automatically deploys with an automatic model partitioner, which uses a graph sharding algorithm on a proxy representation of the model. Merak also presents the non-intrusive API for scaling out foundation model training with minimal code modification. In addition, we design a high-performance 3D parallel runtime engine in Merak. It uses several techniques to exploit available training resources, including shifted critical path pipeline schedule that brings a higher computation utilization, stage-aware recomputation that makes use of idle worker memory, and sub-pipelined tensor model parallelism that overlaps communication and computation. Experiments on 64 GPUs show Merak can speedup the training performance over the state-of-the-art 3D parallelism frameworks of models with 1.5, 2.5, 8.3, and 20 billion parameters by up to 1.42X, 1.39X, 1.43X, and 1.61X, respectively.