 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCronusVLA: Transferring Latent Motion Across Time for Multi-Frame Prediction in Manipulation
Jun 24, 2025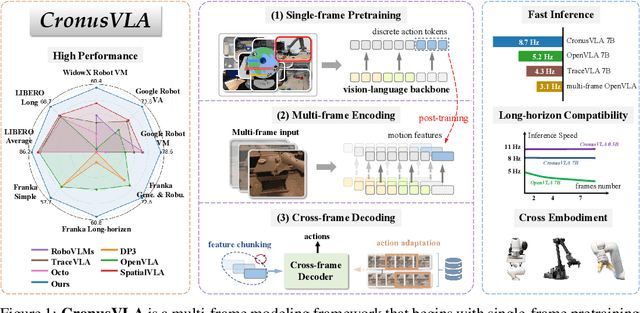
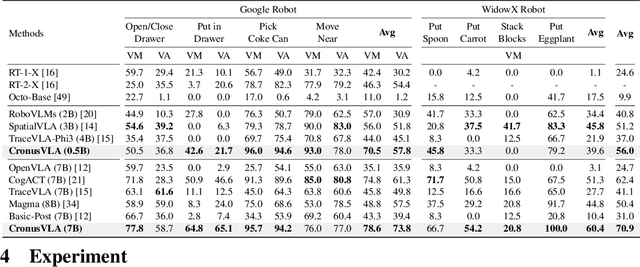
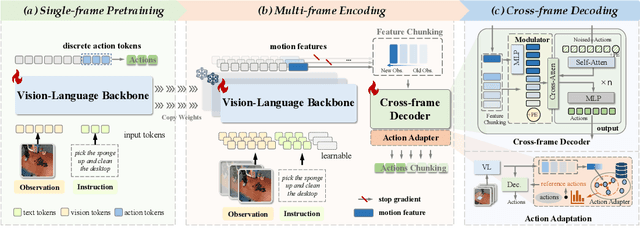
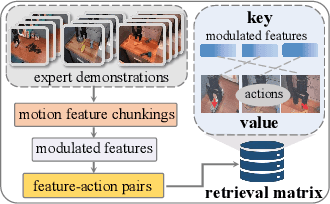
Recent vision-language-action (VLA) models built on pretrained vision-language models (VLMs) have demonstrated strong generalization across manipulation tasks. However, they remain constrained by a single-frame observation paradigm and cannot fully benefit from the motion information offered by aggregated multi-frame historical observations, as the large vision-language backbone introduces substantial computational cost and inference latency. We propose CronusVLA, a unified framework that extends single-frame VLA models to the multi-frame paradigm through an efficient post-training stage. CronusVLA comprises three key components: (1) single-frame pretraining on large-scale embodied datasets with autoregressive action tokens prediction, which establishes an embodied vision-language foundation; (2) multi-frame encoding, adapting the prediction of vision-language backbones from discrete action tokens to motion features during post-training, and aggregating motion features from historical frames into a feature chunking; (3) cross-frame decoding, which maps the feature chunking to accurate actions via a shared decoder with cross-attention. By reducing redundant token computation and caching past motion features, CronusVLA achieves efficient inference. As an application of motion features, we further propose an action adaptation mechanism based on feature-action retrieval to improve model performance during finetuning. CronusVLA achieves state-of-the-art performance on SimplerEnv with 70.9% success rate, and 12.7% improvement over OpenVLA on LIBERO. Real-world Franka experiments also show the strong performance and robustness.
Vela: Scalable Embeddings with Voice Large Language Models for Multimodal Retrieval
Jun 17, 2025Multimodal large language models (MLLMs) have seen substantial progress in recent years. However, their ability to represent multimodal information in the acoustic domain remains underexplored. In this work, we introduce Vela, a novel framework designed to adapt MLLMs for the generation of universal multimodal embeddings. By leveraging MLLMs with specially crafted prompts and selected in-context learning examples, Vela effectively bridges the modality gap across various modalities. We then propose a single-modality training approach, where the model is trained exclusively on text pairs. Our experiments show that Vela outperforms traditional CLAP models in standard text-audio retrieval tasks. Furthermore, we introduce new benchmarks that expose CLAP models' limitations in handling long texts and complex retrieval tasks. In contrast, Vela, by harnessing the capabilities of MLLMs, demonstrates robust performance in these scenarios. Our code will soon be available.
Speech Token Prediction via Compressed-to-fine Language Modeling for Speech Generation
May 30, 2025Neural audio codecs, used as speech tokenizers, have demonstrated remarkable potential in the field of speech generation. However, to ensure high-fidelity audio reconstruction, neural audio codecs typically encode audio into long sequences of speech tokens, posing a significant challenge for downstream language models in long-context modeling. We observe that speech token sequences exhibit short-range dependency: due to the monotonic alignment between text and speech in text-to-speech (TTS) tasks, the prediction of the current token primarily relies on its local context, while long-range tokens contribute less to the current token prediction and often contain redundant information. Inspired by this observation, we propose a \textbf{compressed-to-fine language modeling} approach to address the challenge of long sequence speech tokens within neural codec language models: (1) \textbf{Fine-grained Initial and Short-range Information}: Our approach retains the prompt and local tokens during prediction to ensure text alignment and the integrity of paralinguistic information; (2) \textbf{Compressed Long-range Context}: Our approach compresses long-range token spans into compact representations to reduce redundant information while preserving essential semantics. Extensive experiments on various neural audio codecs and downstream language models validate the effectiveness and generalizability of the proposed approach, highlighting the importance of token compression in improving speech generation within neural codec language models. The demo of audio samples will be available at https://anonymous.4open.science/r/SpeechTokenPredictionViaCompressedToFinedLM.
Diff-Prompt: Diffusion-Driven Prompt Generator with Mask Supervision
Apr 30, 2025Prompt learning has demonstrated promising results in fine-tuning pre-trained multimodal models. However, the performance improvement is limited when applied to more complex and fine-grained tasks. The reason is that most existing methods directly optimize the parameters involved in the prompt generation process through loss backpropagation, which constrains the richness and specificity of the prompt representations. In this paper, we propose Diffusion-Driven Prompt Generator (Diff-Prompt), aiming to use the diffusion model to generate rich and fine-grained prompt information for complex downstream tasks. Specifically, our approach consists of three stages. In the first stage, we train a Mask-VAE to compress the masks into latent space. In the second stage, we leverage an improved Diffusion Transformer (DiT) to train a prompt generator in the latent space, using the masks for supervision. In the third stage, we align the denoising process of the prompt generator with the pre-trained model in the semantic space, and use the generated prompts to fine-tune the model. We conduct experiments on a complex pixel-level downstream task, referring expression comprehension, and compare our method with various parameter-efficient fine-tuning approaches. Diff-Prompt achieves a maximum improvement of 8.87 in R@1 and 14.05 in R@5 compared to the foundation model and also outperforms other state-of-the-art methods across multiple metrics. The experimental results validate the effectiveness of our approach and highlight the potential of using generative models for prompt generation. Code is available at https://github.com/Kelvin-ywc/diff-prompt.
EyecareGPT: Boosting Comprehensive Ophthalmology Understanding with Tailored Dataset, Benchmark and Model
Apr 18, 2025Medical Large Vision-Language Models (Med-LVLMs) demonstrate significant potential in healthcare, but their reliance on general medical data and coarse-grained global visual understanding limits them in intelligent ophthalmic diagnosis. Currently, intelligent ophthalmic diagnosis faces three major challenges: (i) Data. The lack of deeply annotated, high-quality, multi-modal ophthalmic visual instruction data; (ii) Benchmark. The absence of a comprehensive and systematic benchmark for evaluating diagnostic performance; (iii) Model. The difficulty of adapting holistic visual architectures to fine-grained, region-specific ophthalmic lesion identification. In this paper, we propose the Eyecare Kit, which systematically tackles the aforementioned three key challenges with the tailored dataset, benchmark and model: First, we construct a multi-agent data engine with real-life ophthalmology data to produce Eyecare-100K, a high-quality ophthalmic visual instruction dataset. Subsequently, we design Eyecare-Bench, a benchmark that comprehensively evaluates the overall performance of LVLMs on intelligent ophthalmic diagnosis tasks across multiple dimensions. Finally, we develop the EyecareGPT, optimized for fine-grained ophthalmic visual understanding thoroughly, which incorporates an adaptive resolution mechanism and a layer-wise dense connector. Extensive experimental results indicate that the EyecareGPT achieves state-of-the-art performance in a range of ophthalmic tasks, underscoring its significant potential for the advancement of open research in intelligent ophthalmic diagnosis. Our project is available at https://github.com/DCDmllm/EyecareGPT.
OmniCam: Unified Multimodal Video Generation via Camera Control
Apr 03, 2025



Camera control, which achieves diverse visual effects by changing camera position and pose, has attracted widespread attention. However, existing methods face challenges such as complex interaction and limited control capabilities. To address these issues, we present OmniCam, a unified multimodal camera control framework. Leveraging large language models and video diffusion models, OmniCam generates spatio-temporally consistent videos. It supports various combinations of input modalities: the user can provide text or video with expected trajectory as camera path guidance, and image or video as content reference, enabling precise control over camera motion. To facilitate the training of OmniCam, we introduce the OmniTr dataset, which contains a large collection of high-quality long-sequence trajectories, videos, and corresponding descriptions. Experimental results demonstrate that our model achieves state-of-the-art performance in high-quality camera-controlled video generation across various metrics.
Astrea: A MOE-based Visual Understanding Model with Progressive Alignment
Mar 12, 2025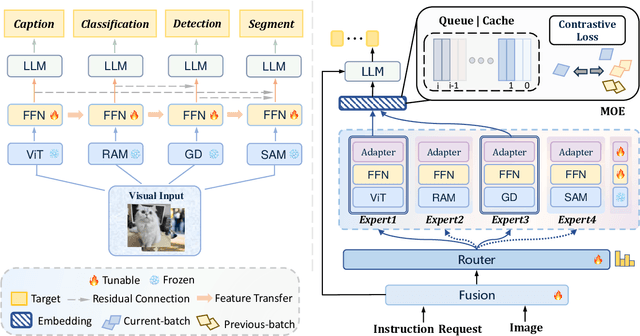
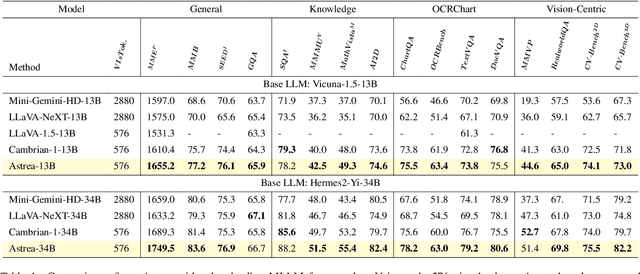
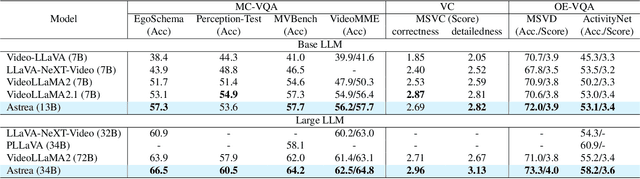
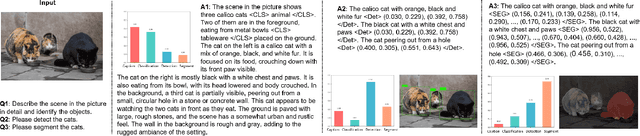
Vision-Language Models (VLMs) based on Mixture-of-Experts (MoE) architectures have emerged as a pivotal paradigm in multimodal understanding, offering a powerful framework for integrating visual and linguistic information. However, the increasing complexity and diversity of tasks present significant challenges in coordinating load balancing across heterogeneous visual experts, where optimizing one specialist's performance often compromises others' capabilities. To address task heterogeneity and expert load imbalance, we propose Astrea, a novel multi-expert collaborative VLM architecture based on progressive pre-alignment. Astrea introduces three key innovations: 1) A heterogeneous expert coordination mechanism that integrates four specialized models (detection, segmentation, classification, captioning) into a comprehensive expert matrix covering essential visual comprehension elements; 2) A dynamic knowledge fusion strategy featuring progressive pre-alignment to harmonize experts within the VLM latent space through contrastive learning, complemented by probabilistically activated stochastic residual connections to preserve knowledge continuity; 3) An enhanced optimization framework utilizing momentum contrastive learning for long-range dependency modeling and adaptive weight allocators for real-time expert contribution calibration. Extensive evaluations across 12 benchmark tasks spanning VQA, image captioning, and cross-modal retrieval demonstrate Astrea's superiority over state-of-the-art models, achieving an average performance gain of +4.7\%. This study provides the first empirical demonstration that progressive pre-alignment strategies enable VLMs to overcome task heterogeneity limitations, establishing new methodological foundations for developing general-purpose multimodal agents.
Sparse Alignment Enhanced Latent Diffusion Transformer for Zero-Shot Speech Synthesis
Feb 26, 2025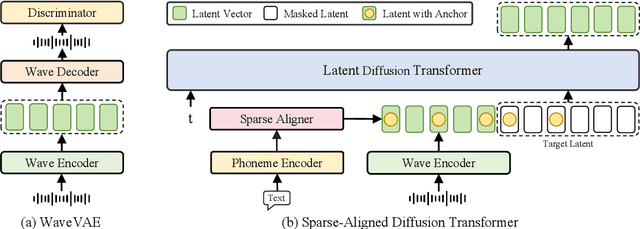
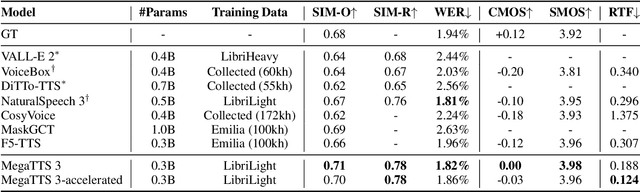
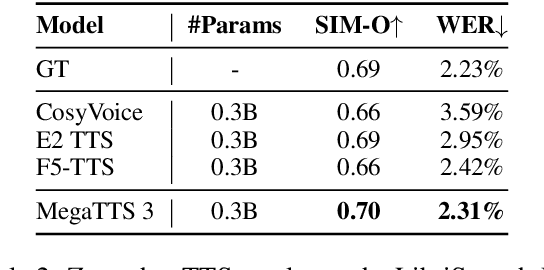

While recent zero-shot text-to-speech (TTS) models have significantly improved speech quality and expressiveness, mainstream systems still suffer from issues related to speech-text alignment modeling: 1) models without explicit speech-text alignment modeling exhibit less robustness, especially for hard sentences in practical applications; 2) predefined alignment-based models suffer from naturalness constraints of forced alignments. This paper introduces \textit{S-DiT}, a TTS system featuring an innovative sparse alignment algorithm that guides the latent diffusion transformer (DiT). Specifically, we provide sparse alignment boundaries to S-DiT to reduce the difficulty of alignment learning without limiting the search space, thereby achieving high naturalness. Moreover, we employ a multi-condition classifier-free guidance strategy for accent intensity adjustment and adopt the piecewise rectified flow technique to accelerate the generation process. Experiments demonstrate that S-DiT achieves state-of-the-art zero-shot TTS speech quality and supports highly flexible control over accent intensity. Notably, our system can generate high-quality one-minute speech with only 8 sampling steps. Audio samples are available at https://sditdemo.github.io/sditdemo/.
EAGER-LLM: Enhancing Large Language Models as Recommenders through Exogenous Behavior-Semantic Integration
Feb 20, 2025Large language models (LLMs) are increasingly leveraged as foundational backbones in the development of advanced recommender systems, offering enhanced capabilities through their extensive knowledge and reasoning. Existing llm-based recommender systems (RSs) often face challenges due to the significant differences between the linguistic semantics of pre-trained LLMs and the collaborative semantics essential for RSs. These systems use pre-trained linguistic semantics but learn collaborative semantics from scratch via the llm-Backbone. However, LLMs are not designed for recommendations, leading to inefficient collaborative learning, weak result correlations, and poor integration of traditional RS features. To address these challenges, we propose EAGER-LLM, a decoder-only llm-based generative recommendation framework that integrates endogenous and exogenous behavioral and semantic information in a non-intrusive manner. Specifically, we propose 1)dual-source knowledge-rich item indices that integrates indexing sequences for exogenous signals, enabling efficient link-wide processing; 2)non-invasive multiscale alignment reconstruction tasks guide the model toward a deeper understanding of both collaborative and semantic signals; 3)an annealing adapter designed to finely balance the model's recommendation performance with its comprehension capabilities. We demonstrate EAGER-LLM's effectiveness through rigorous testing on three public benchmarks.
OmniChat: Enhancing Spoken Dialogue Systems with Scalable Synthetic Data for Diverse Scenarios
Jan 02, 2025



With the rapid development of large language models, researchers have created increasingly advanced spoken dialogue systems that can naturally converse with humans. However, these systems still struggle to handle the full complexity of real-world conversations, including audio events, musical contexts, and emotional expressions, mainly because current dialogue datasets are constrained in both scale and scenario diversity. In this paper, we propose leveraging synthetic data to enhance the dialogue models across diverse scenarios. We introduce ShareChatX, the first comprehensive, large-scale dataset for spoken dialogue that spans diverse scenarios. Based on this dataset, we introduce OmniChat, a multi-turn dialogue system with a heterogeneous feature fusion module, designed to optimize feature selection in different dialogue contexts. In addition, we explored critical aspects of training dialogue systems using synthetic data. Through comprehensive experimentation, we determined the ideal balance between synthetic and real data, achieving state-of-the-art results on the real-world dialogue dataset DailyTalk. We also highlight the crucial importance of synthetic data in tackling diverse, complex dialogue scenarios, especially those involving audio and music. For more details, please visit our demo page at \url{https://sharechatx.github.io/}.