 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Stability and Plasticity for Multi-Modal Test-Time Adaptation
Feb 28, 2026Adapting pretrained multi-modal models to evolving test-time distributions, known as multi-modal test-time adaptation, presents a significant challenge. Existing methods frequently encounter negative transfer in the unbiased modality and catastrophic forgetting in the biased modality. To address these challenges, we propose Decoupling Adaptation for Stability and Plasticity (DASP), a novel diagnose-then-mitigate framework. Our analysis reveals a critical discrepancy within the unified latent space: the biased modality exhibits substantially higher interdimensional redundancy (i.e., strong correlations across feature dimensions) compared to the unbiased modality. Leveraging this insight, DASP identifies the biased modality and implements an asymmetric adaptation strategy. This strategy employs a decoupled architecture where each modality-specific adapter is divided into stable and plastic components. The asymmetric mechanism works as follows: for the biased modality, which requires plasticity, the plastic component is activated and updated to capture domain-specific information, while the stable component remains fixed. Conversely, for the unbiased modality, which requires stability, the plastic component is bypassed, and the stable component is updated using KL regularization to prevent negative transfer. This asymmetric design enables the model to adapt flexibly to new domains while preserving generalizable knowledge. Comprehensive evaluations on diverse multi-modal benchmarks demonstrate that DASP significantly outperforms state-of-the-art methods.
Generative Reasoning Recommendation via LLMs
Oct 23, 2025Despite their remarkable reasoning capabilities across diverse domains, large language models (LLMs) face fundamental challenges in natively functioning as generative reasoning recommendation models (GRRMs), where the intrinsic modeling gap between textual semantics and collaborative filtering signals, combined with the sparsity and stochasticity of user feedback, presents significant obstacles. This work explores how to build GRRMs by adapting pre-trained LLMs, which achieves a unified understanding-reasoning-prediction manner for recommendation tasks. We propose GREAM, an end-to-end framework that integrates three components: (i) Collaborative-Semantic Alignment, which fuses heterogeneous textual evidence to construct semantically consistent, discrete item indices and auxiliary alignment tasks that ground linguistic representations in interaction semantics; (ii) Reasoning Curriculum Activation, which builds a synthetic dataset with explicit Chain-of-Thought supervision and a curriculum that progresses through behavioral evidence extraction, latent preference modeling, intent inference, recommendation formulation, and denoised sequence rewriting; and (iii) Sparse-Regularized Group Policy Optimization (SRPO), which stabilizes post-training via Residual-Sensitive Verifiable Reward and Bonus-Calibrated Group Advantage Estimation, enabling end-to-end optimization under verifiable signals despite sparse successes. GREAM natively supports two complementary inference modes: Direct Sequence Recommendation for high-throughput, low-latency deployment, and Sequential Reasoning Recommendation that first emits an interpretable reasoning chain for causal transparency. Experiments on three datasets demonstrate consistent gains over strong baselines, providing a practical path toward verifiable-RL-driven LLM recommenders.
Observe-R1: Unlocking Reasoning Abilities of MLLMs with Dynamic Progressive Reinforcement Learning
May 18, 2025



Reinforcement Learning (RL) has shown promise in improving the reasoning abilities of Large Language Models (LLMs). However, the specific challenges of adapting RL to multimodal data and formats remain relatively unexplored. In this work, we present Observe-R1, a novel framework aimed at enhancing the reasoning capabilities of multimodal large language models (MLLMs). We draw inspirations from human learning progression--from simple to complex and easy to difficult, and propose a gradual learning paradigm for MLLMs. To this end, we construct the NeuraLadder dataset, which is organized and sampled according to the difficulty and complexity of data samples for RL training. To tackle multimodal tasks, we introduce a multimodal format constraint that encourages careful observation of images, resulting in enhanced visual abilities and clearer and more structured responses. Additionally, we implement a bonus reward system that favors concise, correct answers within a length constraint, alongside a dynamic weighting mechanism that prioritizes uncertain and medium-difficulty problems, ensuring that more informative samples have a greater impact on training. Our experiments with the Qwen2.5-VL-3B and Qwen2.5-VL-7B models on 20k samples from the NeuraLadder dataset show that Observe-R1 outperforms a series of larger reasoning models on both reasoning and general benchmarks, achieving superior clarity and conciseness in reasoning chains. Ablation studies validate the effectiveness of our strategies, highlighting the robustness and generalization of our approach. The dataset and code will be released at https://github.com/zrguo/Observe-R1.
Diff-Prompt: Diffusion-Driven Prompt Generator with Mask Supervision
Apr 30, 2025Prompt learning has demonstrated promising results in fine-tuning pre-trained multimodal models. However, the performance improvement is limited when applied to more complex and fine-grained tasks. The reason is that most existing methods directly optimize the parameters involved in the prompt generation process through loss backpropagation, which constrains the richness and specificity of the prompt representations. In this paper, we propose Diffusion-Driven Prompt Generator (Diff-Prompt), aiming to use the diffusion model to generate rich and fine-grained prompt information for complex downstream tasks. Specifically, our approach consists of three stages. In the first stage, we train a Mask-VAE to compress the masks into latent space. In the second stage, we leverage an improved Diffusion Transformer (DiT) to train a prompt generator in the latent space, using the masks for supervision. In the third stage, we align the denoising process of the prompt generator with the pre-trained model in the semantic space, and use the generated prompts to fine-tune the model. We conduct experiments on a complex pixel-level downstream task, referring expression comprehension, and compare our method with various parameter-efficient fine-tuning approaches. Diff-Prompt achieves a maximum improvement of 8.87 in R@1 and 14.05 in R@5 compared to the foundation model and also outperforms other state-of-the-art methods across multiple metrics. The experimental results validate the effectiveness of our approach and highlight the potential of using generative models for prompt generation. Code is available at https://github.com/Kelvin-ywc/diff-prompt.
ConceptGuard: Continual Personalized Text-to-Image Generation with Forgetting and Confusion Mitigation
Mar 13, 2025



Diffusion customization methods have achieved impressive results with only a minimal number of user-provided images. However, existing approaches customize concepts collectively, whereas real-world applications often require sequential concept integration. This sequential nature can lead to catastrophic forgetting, where previously learned concepts are lost. In this paper, we investigate concept forgetting and concept confusion in the continual customization. To tackle these challenges, we present ConceptGuard, a comprehensive approach that combines shift embedding, concept-binding prompts and memory preservation regularization, supplemented by a priority queue which can adaptively update the importance and occurrence order of different concepts. These strategies can dynamically update, unbind and learn the relationship of the previous concepts, thus alleviating concept forgetting and confusion. Through comprehensive experiments, we show that our approach outperforms all the baseline methods consistently and significantly in both quantitative and qualitative analyses.
Smoothing the Shift: Towards Stable Test-Time Adaptation under Complex Multimodal Noises
Mar 04, 2025Test-Time Adaptation (TTA) aims to tackle distribution shifts using unlabeled test data without access to the source data. In the context of multimodal data, there are more complex noise patterns than unimodal data such as simultaneous corruptions for multiple modalities and missing modalities. Besides, in real-world applications, corruptions from different distribution shifts are always mixed. Existing TTA methods always fail in such multimodal scenario because the abrupt distribution shifts will destroy the prior knowledge from the source model, thus leading to performance degradation. To this end, we reveal a new challenge named multimodal wild TTA. To address this challenging problem, we propose two novel strategies: sample identification with interquartile range Smoothing and unimodal assistance, and Mutual information sharing (SuMi). SuMi smooths the adaptation process by interquartile range which avoids the abrupt distribution shifts. Then, SuMi fully utilizes the unimodal features to select low-entropy samples with rich multimodal information for optimization. Furthermore, mutual information sharing is introduced to align the information, reduce the discrepancies and enhance the information utilization across different modalities. Extensive experiments on two public datasets show the effectiveness and superiority over existing methods under the complex noise patterns in multimodal data. Code is available at https://github.com/zrguo/SuMi.
Low-rank Prompt Interaction for Continual Vision-Language Retrieval
Jan 24, 2025



Research on continual learning in multi-modal tasks has been receiving increasing attention. However, most existing work overlooks the explicit cross-modal and cross-task interactions. In this paper, we innovatively propose the Low-rank Prompt Interaction (LPI) to address this general problem of multi-modal understanding, which considers both cross-modal and cross-task interactions. Specifically, as for the former, we employ multi-modal correlation modules for corresponding Transformer layers. Considering that the training parameters scale to the number of layers and tasks, we propose low-rank interaction-augmented decomposition to avoid memory explosion while enhancing the cross-modal association through sharing and separating common-specific low-rank factors. In addition, due to the multi-modal semantic differences carried by the low-rank initialization, we adopt hierarchical low-rank contrastive learning to ensure training robustness. As for the latter, we initially employ a visual analysis and identify that different tasks have clear distinctions in proximity. Therefore, we introduce explicit task contrastive constraints in the prompt learning process based on task semantic distances. Experiments on two retrieval tasks show performance improvements with the introduction of a minimal number of parameters, demonstrating the effectiveness of our method. Code is available at https://github.com/Kelvin-ywc/LPI.
A Wander Through the Multimodal Landscape: Efficient Transfer Learning via Low-rank Sequence Multimodal Adapter
Dec 12, 2024
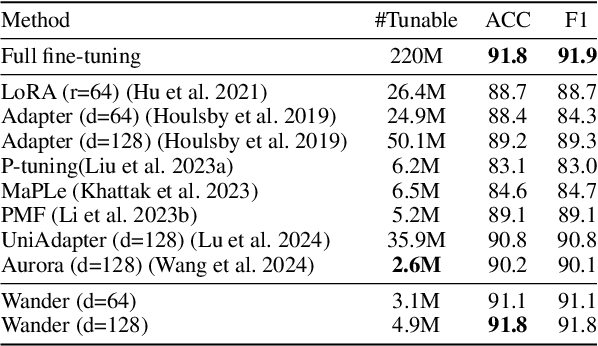


Efficient transfer learning methods such as adapter-based methods have shown great success in unimodal models and vision-language models. However, existing methods have two main challenges in fine-tuning multimodal models. Firstly, they are designed for vision-language tasks and fail to extend to situations where there are more than two modalities. Secondly, they exhibit limited exploitation of interactions between modalities and lack efficiency. To address these issues, in this paper, we propose the loW-rank sequence multimodal adapter (Wander). We first use the outer product to fuse the information from different modalities in an element-wise way effectively. For efficiency, we use CP decomposition to factorize tensors into rank-one components and achieve substantial parameter reduction. Furthermore, we implement a token-level low-rank decomposition to extract more fine-grained features and sequence relationships between modalities. With these designs, Wander enables token-level interactions between sequences of different modalities in a parameter-efficient way. We conduct extensive experiments on datasets with different numbers of modalities, where Wander outperforms state-of-the-art efficient transfer learning methods consistently. The results fully demonstrate the effectiveness, efficiency and universality of Wander.
Bridging the Gap for Test-Time Multimodal Sentiment Analysis
Dec 10, 2024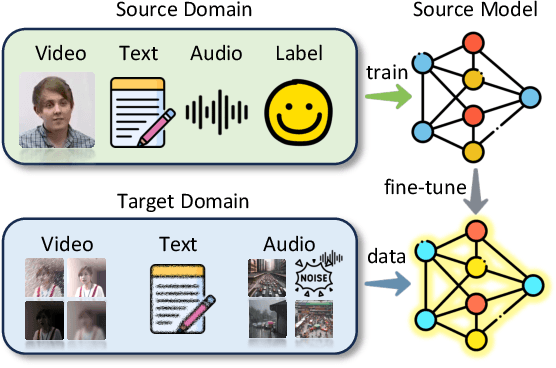
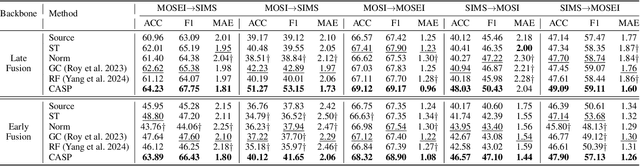

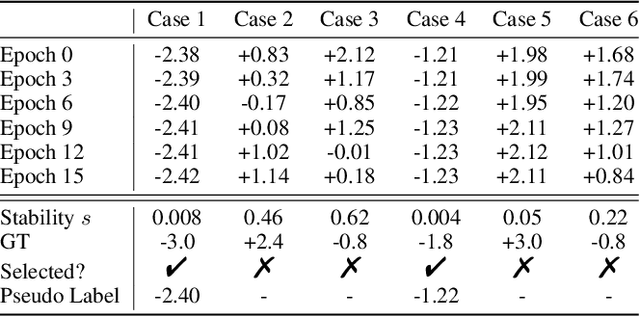
Multimodal sentiment analysis (MSA) is an emerging research topic that aims to understand and recognize human sentiment or emotions through multiple modalities. However, in real-world dynamic scenarios, the distribution of target data is always changing and different from the source data used to train the model, which leads to performance degradation. Common adaptation methods usually need source data, which could pose privacy issues or storage overheads. Therefore, test-time adaptation (TTA) methods are introduced to improve the performance of the model at inference time. Existing TTA methods are always based on probabilistic models and unimodal learning, and thus can not be applied to MSA which is often considered as a multimodal regression task. In this paper, we propose two strategies: Contrastive Adaptation and Stable Pseudo-label generation (CASP) for test-time adaptation for multimodal sentiment analysis. The two strategies deal with the distribution shifts for MSA by enforcing consistency and minimizing empirical risk, respectively. Extensive experiments show that CASP brings significant and consistent improvements to the performance of the model across various distribution shift settings and with different backbones, demonstrating its effectiveness and versatility. Our codes are available at https://github.com/zrguo/CASP.
Classifier-guided Gradient Modulation for Enhanced Multimodal Learning
Nov 03, 2024Multimodal learning has developed very fast in recent years. However, during the multimodal training process, the model tends to rely on only one modality based on which it could learn faster, thus leading to inadequate use of other modalities. Existing methods to balance the training process always have some limitations on the loss functions, optimizers and the number of modalities and only consider modulating the magnitude of the gradients while ignoring the directions of the gradients. To solve these problems, in this paper, we present a novel method to balance multimodal learning with Classifier-Guided Gradient Modulation (CGGM), considering both the magnitude and directions of the gradients. We conduct extensive experiments on four multimodal datasets: UPMC-Food 101, CMU-MOSI, IEMOCAP and BraTS 2021, covering classification, regression and segmentation tasks. The results show that CGGM outperforms all the baselines and other state-of-the-art methods consistently, demonstrating its effectiveness and versatility. Our code is available at https://github.com/zrguo/CGGM.