 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTADS: Task-Aware Data Selection for Multi-Task Multimodal Pre-Training
Feb 05, 2026Large-scale multimodal pre-trained models like CLIP rely heavily on high-quality training data, yet raw web-crawled datasets are often noisy, misaligned, and redundant, leading to inefficient training and suboptimal generalization. Existing data selection methods are either heuristic-based, suffering from bias and limited diversity, or data-driven but task-agnostic, failing to optimize for multi-task scenarios. To address these gaps, we introduce TADS (Task-Aware Data Selection), a novel framework for multi-task multimodal pre-training that integrates Intrinsic Quality, Task Relevance, and Distributional Diversity into a learnable value function. TADS employs a comprehensive quality assessment system with unimodal and cross-modal operators, quantifies task relevance via interpretable similarity vectors, and optimizes diversity through cluster-based weighting. A feedback-driven meta-learning mechanism adaptively refines the selection strategy based on proxy model performance across multiple downstream tasks. Experiments on CC12M demonstrate that TADS achieves superior zero-shot performance on benchmarks like ImageNet, CIFAR-100, MS-COCO, and Flickr30K, using only 36% of the data while outperforming baselines by an average of 1.0%. This highlights that TADS significantly enhances data efficiency by curating a high-utility subset that yields a much higher performance ceiling within the same computational constraints.
E2PL: Effective and Efficient Prompt Learning for Incomplete Multi-view Multi-Label Class Incremental Learning
Jan 23, 2026Multi-view multi-label classification (MvMLC) is indispensable for modern web applications aggregating information from diverse sources. However, real-world web-scale settings are rife with missing views and continuously emerging classes, which pose significant obstacles to robust learning. Prevailing methods are ill-equipped for this reality, as they either lack adaptability to new classes or incur exponential parameter growth when handling all possible missing-view patterns, severely limiting their scalability in web environments. To systematically address this gap, we formally introduce a novel task, termed \emph{incomplete multi-view multi-label class incremental learning} (IMvMLCIL), which requires models to simultaneously address heterogeneous missing views and dynamic class expansion. To tackle this task, we propose \textsf{E2PL}, an Effective and Efficient Prompt Learning framework for IMvMLCIL. \textsf{E2PL} unifies two novel prompt designs: \emph{task-tailored prompts} for class-incremental adaptation and \emph{missing-aware prompts} for the flexible integration of arbitrary view-missing scenarios. To fundamentally address the exponential parameter explosion inherent in missing-aware prompts, we devise an \emph{efficient prototype tensorization} module, which leverages atomic tensor decomposition to elegantly reduce the prompt parameter complexity from exponential to linear w.r.t. the number of views. We further incorporate a \emph{dynamic contrastive learning} strategy explicitly model the complex dependencies among diverse missing-view patterns, thus enhancing the model's robustness. Extensive experiments on three benchmarks demonstrate that \textsf{E2PL} consistently outperforms state-of-the-art methods in both effectiveness and efficiency. The codes and datasets are available at https://anonymous.4open.science/r/code-for-E2PL.
TermGPT: Multi-Level Contrastive Fine-Tuning for Terminology Adaptation in Legal and Financial Domain
Nov 13, 2025Large language models (LLMs) have demonstrated impressive performance in text generation tasks; however, their embedding spaces often suffer from the isotropy problem, resulting in poor discrimination of domain-specific terminology, particularly in legal and financial contexts. This weakness in terminology-level representation can severely hinder downstream tasks such as legal judgment prediction or financial risk analysis, where subtle semantic distinctions are critical. To address this problem, we propose TermGPT, a multi-level contrastive fine-tuning framework designed for terminology adaptation. We first construct a sentence graph to capture semantic and structural relations, and generate semantically consistent yet discriminative positive and negative samples based on contextual and topological cues. We then devise a multi-level contrastive learning approach at both the sentence and token levels, enhancing global contextual understanding and fine-grained terminology discrimination. To support robust evaluation, we construct the first financial terminology dataset derived from official regulatory documents. Experiments show that TermGPT outperforms existing baselines in term discrimination tasks within the finance and legal domains.
Implicit Counterfactual Learning for Audio-Visual Segmentation
Jul 28, 2025
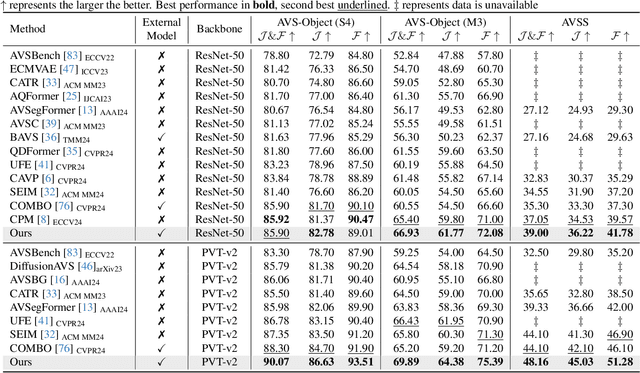
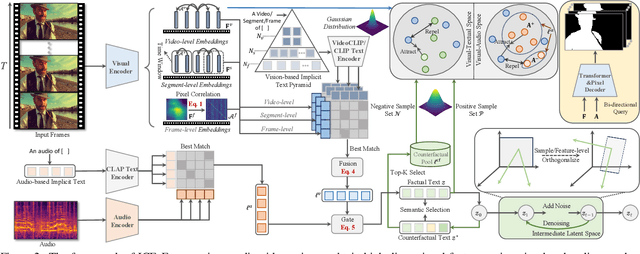
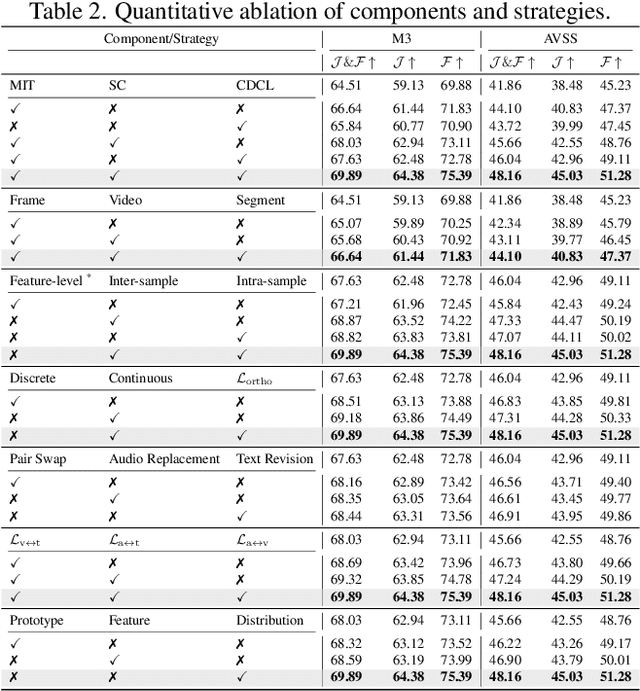
Audio-visual segmentation (AVS) aims to segment objects in videos based on audio cues. Existing AVS methods are primarily designed to enhance interaction efficiency but pay limited attention to modality representation discrepancies and imbalances. To overcome this, we propose the implicit counterfactual framework (ICF) to achieve unbiased cross-modal understanding. Due to the lack of semantics, heterogeneous representations may lead to erroneous matches, especially in complex scenes with ambiguous visual content or interference from multiple audio sources. We introduce the multi-granularity implicit text (MIT) involving video-, segment- and frame-level as the bridge to establish the modality-shared space, reducing modality gaps and providing prior guidance. Visual content carries more information and typically dominates, thereby marginalizing audio features in the decision-making. To mitigate knowledge preference, we propose the semantic counterfactual (SC) to learn orthogonal representations in the latent space, generating diverse counterfactual samples, thus avoiding biases introduced by complex functional designs and explicit modifications of text structures or attributes. We further formulate the collaborative distribution-aware contrastive learning (CDCL), incorporating factual-counterfactual and inter-modality contrasts to align representations, promoting cohesion and decoupling. Extensive experiments on three public datasets validate that the proposed method achieves state-of-the-art performance.
ZeroED: Hybrid Zero-shot Error Detection through Large Language Model Reasoning
Apr 06, 2025Error detection (ED) in tabular data is crucial yet challenging due to diverse error types and the need for contextual understanding. Traditional ED methods often rely heavily on manual criteria and labels, making them labor-intensive. Large language models (LLM) can minimize human effort but struggle with errors requiring a comprehensive understanding of data context. In this paper, we propose ZeroED, a novel hybrid zero-shot error detection framework, which combines LLM reasoning ability with the manual label-based ED pipeline. ZeroED operates in four steps, i.e., feature representation, error labeling, training data construction, and detector training. Initially, to enhance error distinction, ZeroED generates rich data representations using error reason-aware binary features, pre-trained embeddings, and statistical features. Then, ZeroED employs LLM to label errors holistically through in-context learning, guided by a two-step reasoning process for detailed error detection guidelines. To reduce token costs, LLMs are applied only to representative data selected via clustering-based sampling. High-quality training data is constructed through in-cluster label propagation and LLM augmentation with verification. Finally, a classifier is trained to detect all errors. Extensive experiments on seven public datasets demonstrate that, ZeroED substantially outperforms state-of-the-art methods by a maximum 30% improvement in F1 score and up to 90% token cost reduction.
Lossless Privacy-Preserving Aggregation for Decentralized Federated Learning
Jan 08, 2025



Privacy concerns arise as sensitive data proliferate. Despite decentralized federated learning (DFL) aggregating gradients from neighbors to avoid direct data transmission, it still poses indirect data leaks from the transmitted gradients. Existing privacy-preserving methods for DFL add noise to gradients. They either diminish the model predictive accuracy or suffer from ineffective gradient protection. In this paper, we propose a novel lossless privacy-preserving aggregation rule named LPPA to enhance gradient protection as much as possible but without loss of DFL model predictive accuracy. LPPA subtly injects the noise difference between the sent and received noise into transmitted gradients for gradient protection. The noise difference incorporates neighbors' randomness for each client, effectively safeguarding against data leaks. LPPA employs the noise flow conservation theory to ensure that the noise impact can be globally eliminated. The global sum of all noise differences remains zero, ensuring that accurate gradient aggregation is unaffected and the model accuracy remains intact. We theoretically prove that the privacy-preserving capacity of LPPA is \sqrt{2} times greater than that of noise addition, while maintaining comparable model accuracy to the standard DFL aggregation without noise injection. Experimental results verify the theoretical findings and show that LPPA achieves a 13% mean improvement in accuracy over noise addition. We also demonstrate the effectiveness of LPPA in protecting raw data and guaranteeing lossless model accuracy.
A Wander Through the Multimodal Landscape: Efficient Transfer Learning via Low-rank Sequence Multimodal Adapter
Dec 12, 2024
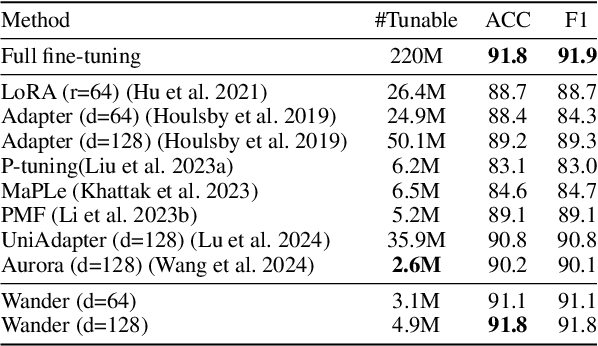


Efficient transfer learning methods such as adapter-based methods have shown great success in unimodal models and vision-language models. However, existing methods have two main challenges in fine-tuning multimodal models. Firstly, they are designed for vision-language tasks and fail to extend to situations where there are more than two modalities. Secondly, they exhibit limited exploitation of interactions between modalities and lack efficiency. To address these issues, in this paper, we propose the loW-rank sequence multimodal adapter (Wander). We first use the outer product to fuse the information from different modalities in an element-wise way effectively. For efficiency, we use CP decomposition to factorize tensors into rank-one components and achieve substantial parameter reduction. Furthermore, we implement a token-level low-rank decomposition to extract more fine-grained features and sequence relationships between modalities. With these designs, Wander enables token-level interactions between sequences of different modalities in a parameter-efficient way. We conduct extensive experiments on datasets with different numbers of modalities, where Wander outperforms state-of-the-art efficient transfer learning methods consistently. The results fully demonstrate the effectiveness, efficiency and universality of Wander.
Bridging the Gap for Test-Time Multimodal Sentiment Analysis
Dec 10, 2024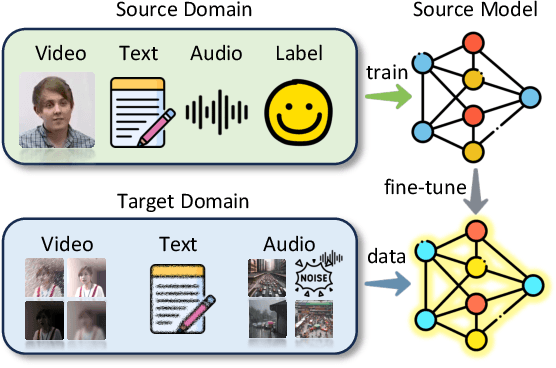
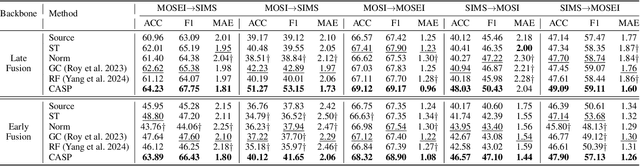

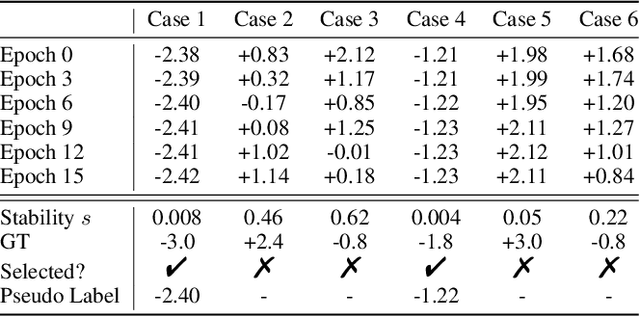
Multimodal sentiment analysis (MSA) is an emerging research topic that aims to understand and recognize human sentiment or emotions through multiple modalities. However, in real-world dynamic scenarios, the distribution of target data is always changing and different from the source data used to train the model, which leads to performance degradation. Common adaptation methods usually need source data, which could pose privacy issues or storage overheads. Therefore, test-time adaptation (TTA) methods are introduced to improve the performance of the model at inference time. Existing TTA methods are always based on probabilistic models and unimodal learning, and thus can not be applied to MSA which is often considered as a multimodal regression task. In this paper, we propose two strategies: Contrastive Adaptation and Stable Pseudo-label generation (CASP) for test-time adaptation for multimodal sentiment analysis. The two strategies deal with the distribution shifts for MSA by enforcing consistency and minimizing empirical risk, respectively. Extensive experiments show that CASP brings significant and consistent improvements to the performance of the model across various distribution shift settings and with different backbones, demonstrating its effectiveness and versatility. Our codes are available at https://github.com/zrguo/CASP.
Differentiable and Scalable Generative Adversarial Models for Data Imputation
Jan 10, 2022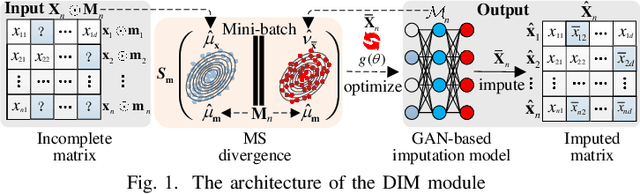
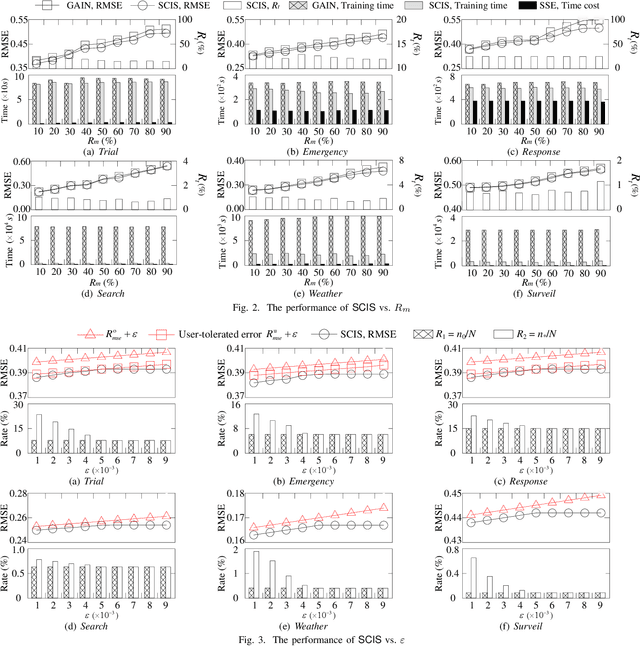
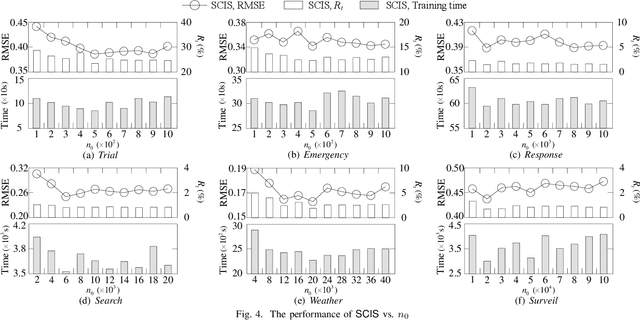
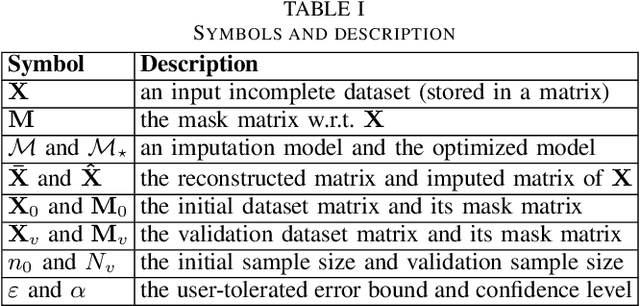
Data imputation has been extensively explored to solve the missing data problem. The dramatically increasing volume of incomplete data makes the imputation models computationally infeasible in many real-life applications. In this paper, we propose an effective scalable imputation system named SCIS to significantly speed up the training of the differentiable generative adversarial imputation models under accuracy-guarantees for large-scale incomplete data. SCIS consists of two modules, differentiable imputation modeling (DIM) and sample size estimation (SSE). DIM leverages a new masking Sinkhorn divergence function to make an arbitrary generative adversarial imputation model differentiable, while for such a differentiable imputation model, SSE can estimate an appropriate sample size to ensure the user-specified imputation accuracy of the final model. Extensive experiments upon several real-life large-scale datasets demonstrate that, our proposed system can accelerate the generative adversarial model training by 7.1x. Using around 7.6% samples, SCIS yields competitive accuracy with the state-of-the-art imputation methods in a much shorter computation time.