 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCom: Unified Multimodal Modeling via Compressed Continuous Semantic Representations
Mar 11, 2026Current unified multimodal models typically rely on discrete visual tokenizers to bridge the modality gap. However, discretization inevitably discards fine-grained semantic information, leading to suboptimal performance in visual understanding tasks. Conversely, directly modeling continuous semantic representations (e.g., CLIP, SigLIP) poses significant challenges in high-dimensional generative modeling, resulting in slow convergence and training instability. To resolve this dilemma, we introduce UniCom, a unified framework that harmonizes multimodal understanding and generation via compressed continuous representation. We empirically demonstrate that reducing channel dimension is significantly more effective than spatial downsampling for both reconstruction and generation. Accordingly, we design an attention-based semantic compressor to distill dense features into a compact unified representation. Furthermore, we validate that the transfusion architecture surpasses query-based designs in convergence and consistency. Experiments demonstrate that UniCom achieves state-of-the-art generation performance among unified models. Notably, by preserving rich semantic priors, it delivers exceptional controllability in image editing and maintains image consistency even without relying on VAE.
Proact-VL: A Proactive VideoLLM for Real-Time AI Companions
Mar 03, 2026Proactive and real-time interactive experiences are essential for human-like AI companions, yet face three key challenges: (1) achieving low-latency inference under continuous streaming inputs, (2) autonomously deciding when to respond, and (3) controlling both quality and quantity of generated content to meet real-time constraints. In this work, we instantiate AI companions through two gaming scenarios, commentator and guide, selected for their suitability for automatic evaluation. We introduce the Live Gaming Benchmark, a large-scale dataset with three representative scenarios: solo commentary, co-commentary, and user guidance, and present Proact-VL, a general framework that shapes multimodal language models into proactive, real-time interactive agents capable of human-like environment perception and interaction. Extensive experiments show Proact-VL achieves superior response latency and quality while maintaining strong video understanding capabilities, demonstrating its practicality for real-time interactive applications.
WorldEdit: Towards Open-World Image Editing with a Knowledge-Informed Benchmark
Feb 06, 2026Recent advances in image editing models have demonstrated remarkable capabilities in executing explicit instructions, such as attribute manipulation, style transfer, and pose synthesis. However, these models often face challenges when dealing with implicit editing instructions, which describe the cause of a visual change without explicitly detailing the resulting outcome. These limitations arise because existing models rely on uniform editing strategies that are not equipped to handle the complex world knowledge and reasoning required for implicit instructions. To address this gap, we introduce \textbf{WorldEdit}, a dataset specifically designed to enable world-driven image editing. WorldEdit consists of high-quality editing samples, guided by paraphrased instructions that align with real-world causal logic. Furthermore, we provide \textbf{WorldEdit-Test} for evaluating the existing model's performance on causal editing scenarios. With WorldEdit, we use a two-stage training framework for fine-tuning models like Bagel, integrating with a causal verification reward. Our results show that the proposed dataset and methods significantly narrow the gap with GPT-4o and Nano-Banana, demonstrating competitive performance not only in instruction following but also in knowledge plausibility, where many open-source systems typically struggle.
From Noisy to Native: LLM-driven Graph Restoration for Test-Time Graph Domain Adaptation
Oct 09, 2025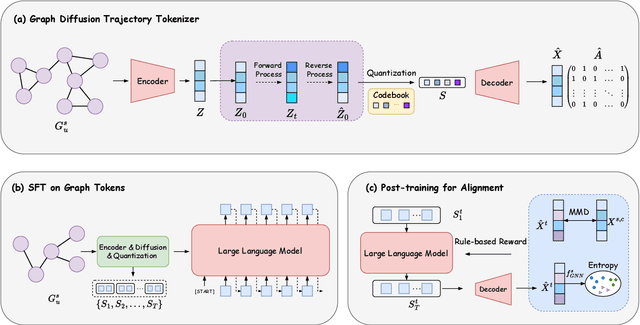
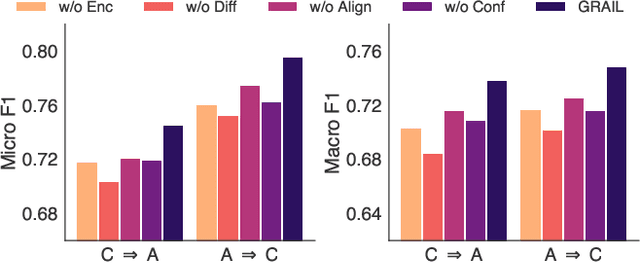
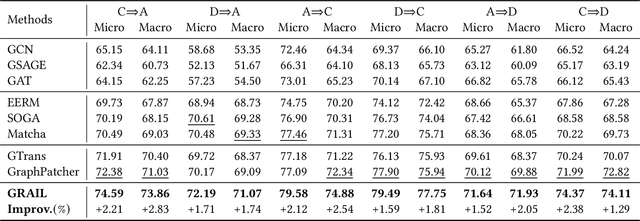
Graph domain adaptation (GDA) has achieved great attention due to its effectiveness in addressing the domain shift between train and test data. A significant bottleneck in existing graph domain adaptation methods is their reliance on source-domain data, which is often unavailable due to privacy or security concerns. This limitation has driven the development of Test-Time Graph Domain Adaptation (TT-GDA), which aims to transfer knowledge without accessing the source examples. Inspired by the generative power of large language models (LLMs), we introduce a novel framework that reframes TT-GDA as a generative graph restoration problem, "restoring the target graph to its pristine, source-domain-like state". There are two key challenges: (1) We need to construct a reasonable graph restoration process and design an effective encoding scheme that an LLM can understand, bridging the modality gap. (2) We need to devise a mechanism to ensure the restored graph acquires the intrinsic features of the source domain, even without access to the source data. To ensure the effectiveness of graph restoration, we propose GRAIL, that restores the target graph into a state that is well-aligned with the source domain. Specifically, we first compress the node representations into compact latent features and then use a graph diffusion process to model the graph restoration process. Then a quantization module encodes the restored features into discrete tokens. Building on this, an LLM is fine-tuned as a generative restorer to transform a "noisy" target graph into a "native" one. To further improve restoration quality, we introduce a reinforcement learning process guided by specialized alignment and confidence rewards. Extensive experiments demonstrate the effectiveness of our approach across various datasets.
IRBridge: Solving Image Restoration Bridge with Pre-trained Generative Diffusion Models
May 30, 2025Bridge models in image restoration construct a diffusion process from degraded to clear images. However, existing methods typically require training a bridge model from scratch for each specific type of degradation, resulting in high computational costs and limited performance. This work aims to efficiently leverage pretrained generative priors within existing image restoration bridges to eliminate this requirement. The main challenge is that standard generative models are typically designed for a diffusion process that starts from pure noise, while restoration tasks begin with a low-quality image, resulting in a mismatch in the state distributions between the two processes. To address this challenge, we propose a transition equation that bridges two diffusion processes with the same endpoint distribution. Based on this, we introduce the IRBridge framework, which enables the direct utilization of generative models within image restoration bridges, offering a more flexible and adaptable approach to image restoration. Extensive experiments on six image restoration tasks demonstrate that IRBridge efficiently integrates generative priors, resulting in improved robustness and generalization performance. Code will be available at GitHub.
Embracing Imperfection: Simulating Students with Diverse Cognitive Levels Using LLM-based Agents
May 26, 2025Large language models (LLMs) are revolutionizing education, with LLM-based agents playing a key role in simulating student behavior. A major challenge in student simulation is modeling the diverse learning patterns of students at various cognitive levels. However, current LLMs, typically trained as ``helpful assistants'', target at generating perfect responses. As a result, they struggle to simulate students with diverse cognitive abilities, as they often produce overly advanced answers, missing the natural imperfections that characterize student learning and resulting in unrealistic simulations. To address this issue, we propose a training-free framework for student simulation. We begin by constructing a cognitive prototype for each student using a knowledge graph, which captures their understanding of concepts from past learning records. This prototype is then mapped to new tasks to predict student performance. Next, we simulate student solutions based on these predictions and iteratively refine them using a beam search method to better replicate realistic mistakes. To validate our approach, we construct the \texttt{Student\_100} dataset, consisting of $100$ students working on Python programming and $5,000$ learning records. Experimental results show that our method consistently outperforms baseline models, achieving $100\%$ improvement in simulation accuracy.
Selftok: Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 18, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 12, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Diff-Prompt: Diffusion-Driven Prompt Generator with Mask Supervision
Apr 30, 2025Prompt learning has demonstrated promising results in fine-tuning pre-trained multimodal models. However, the performance improvement is limited when applied to more complex and fine-grained tasks. The reason is that most existing methods directly optimize the parameters involved in the prompt generation process through loss backpropagation, which constrains the richness and specificity of the prompt representations. In this paper, we propose Diffusion-Driven Prompt Generator (Diff-Prompt), aiming to use the diffusion model to generate rich and fine-grained prompt information for complex downstream tasks. Specifically, our approach consists of three stages. In the first stage, we train a Mask-VAE to compress the masks into latent space. In the second stage, we leverage an improved Diffusion Transformer (DiT) to train a prompt generator in the latent space, using the masks for supervision. In the third stage, we align the denoising process of the prompt generator with the pre-trained model in the semantic space, and use the generated prompts to fine-tune the model. We conduct experiments on a complex pixel-level downstream task, referring expression comprehension, and compare our method with various parameter-efficient fine-tuning approaches. Diff-Prompt achieves a maximum improvement of 8.87 in R@1 and 14.05 in R@5 compared to the foundation model and also outperforms other state-of-the-art methods across multiple metrics. The experimental results validate the effectiveness of our approach and highlight the potential of using generative models for prompt generation. Code is available at https://github.com/Kelvin-ywc/diff-prompt.
Reasoning Physical Video Generation with Diffusion Timestep Tokens via Reinforcement Learning
Apr 22, 2025Despite recent progress in video generation, producing videos that adhere to physical laws remains a significant challenge. Traditional diffusion-based methods struggle to extrapolate to unseen physical conditions (eg, velocity) due to their reliance on data-driven approximations. To address this, we propose to integrate symbolic reasoning and reinforcement learning to enforce physical consistency in video generation. We first introduce the Diffusion Timestep Tokenizer (DDT), which learns discrete, recursive visual tokens by recovering visual attributes lost during the diffusion process. The recursive visual tokens enable symbolic reasoning by a large language model. Based on it, we propose the Phys-AR framework, which consists of two stages: The first stage uses supervised fine-tuning to transfer symbolic knowledge, while the second stage applies reinforcement learning to optimize the model's reasoning abilities through reward functions based on physical conditions. Our approach allows the model to dynamically adjust and improve the physical properties of generated videos, ensuring adherence to physical laws. Experimental results demonstrate that PhysAR can generate videos that are physically consistent.