 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelftok: Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 18, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 12, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Fine Structure-Aware Sampling: A New Sampling Training Scheme for Pixel-Aligned Implicit Models in Single-View Human Reconstruction
Feb 29, 2024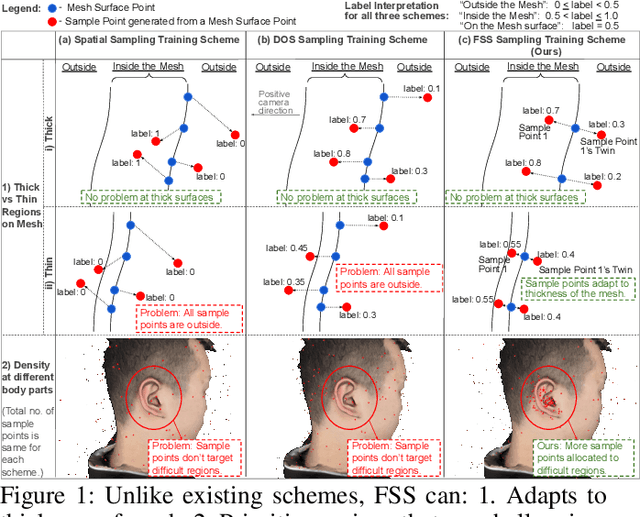
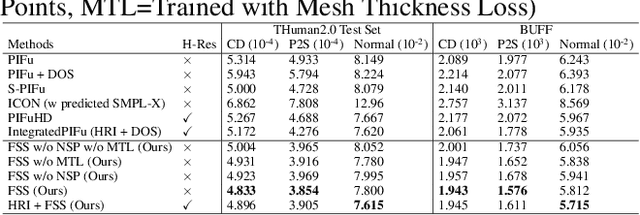
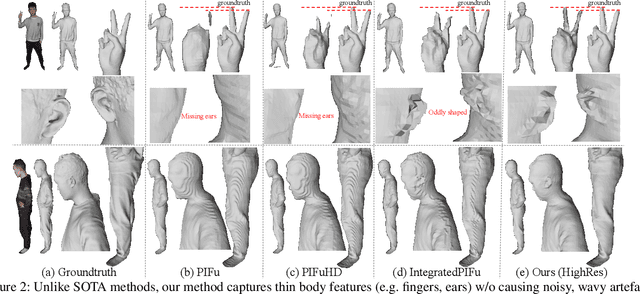
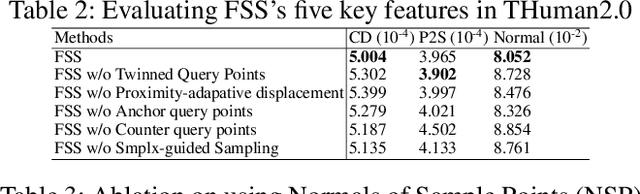
Pixel-aligned implicit models, such as PIFu, PIFuHD, and ICON, are used for single-view clothed human reconstruction. These models need to be trained using a sampling training scheme. Existing sampling training schemes either fail to capture thin surfaces (e.g. ears, fingers) or cause noisy artefacts in reconstructed meshes. To address these problems, we introduce Fine Structured-Aware Sampling (FSS), a new sampling training scheme to train pixel-aligned implicit models for single-view human reconstruction. FSS resolves the aforementioned problems by proactively adapting to the thickness and complexity of surfaces. In addition, unlike existing sampling training schemes, FSS shows how normals of sample points can be capitalized in the training process to improve results. Lastly, to further improve the training process, FSS proposes a mesh thickness loss signal for pixel-aligned implicit models. It becomes computationally feasible to introduce this loss once a slight reworking of the pixel-aligned implicit function framework is carried out. Our results show that our methods significantly outperform SOTA methods qualitatively and quantitatively. Our code is publicly available at https://github.com/kcyt/FSS.
IntegratedPIFu: Integrated Pixel Aligned Implicit Function for Single-view Human Reconstruction
Nov 15, 2022We propose IntegratedPIFu, a new pixel aligned implicit model that builds on the foundation set by PIFuHD. IntegratedPIFu shows how depth and human parsing information can be predicted and capitalised upon in a pixel-aligned implicit model. In addition, IntegratedPIFu introduces depth oriented sampling, a novel training scheme that improve any pixel aligned implicit model ability to reconstruct important human features without noisy artefacts. Lastly, IntegratedPIFu presents a new architecture that, despite using less model parameters than PIFuHD, is able to improves the structural correctness of reconstructed meshes. Our results show that IntegratedPIFu significantly outperforms existing state of the arts methods on single view human reconstruction. Our code has been made available online.
Dense 3D Reconstruction for Visual Tunnel Inspection using Unmanned Aerial Vehicle
Nov 09, 2019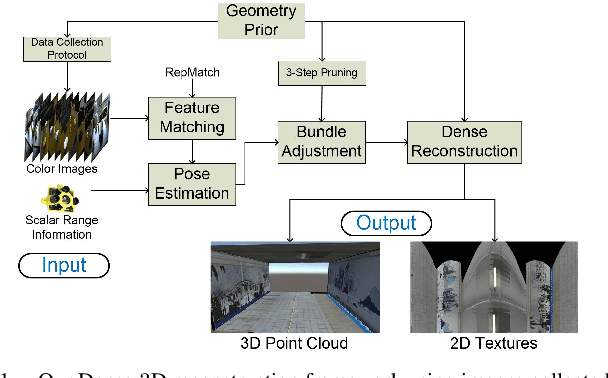



Advances in Unmanned Aerial Vehicle (UAV) opens venues for application such as tunnel inspection. Owing to its versatility to fly inside the tunnels, it can quickly identify defects and potential problems related to safety. However, long tunnels, especially with repetitive or uniform structures pose a significant problem for UAV navigation. Furthermore, post-processing visual data from the camera mounted on the UAV is required to generate useful information for the inspection task. In this work, we design a UAV with a single rotating camera to accomplish the task. Compared to other platforms, our solution can fit the stringent requirement for tunnel inspection, in terms of battery life, size and weight. While the current state-of-the-art can estimate camera pose and 3D geometry from a sequence of images, they assume large overlap, small rotational motion, and many distinct matching points between images. These assumptions severely limit their effectiveness in tunnel-like scenarios where the camera has erratic or large rotational motion, such as the one mounted on the UAV. This paper presents a novel solution which exploits Structure-from-Motion, Bundle Adjustment, and available geometry priors to robustly estimate camera pose and automatically reconstruct a fully-dense 3D scene using the least possible number of images in various challenging tunnel-like environments. We validate our system with both Virtual Reality application and experimentation with a real dataset. The results demonstrate that the proposed reconstruction along with texture mapping allows for remote navigation and inspection of tunnel-like environments, even those which are inaccessible for humans.
* 8 pages, 12 figures