 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Active Learning for Semiconductor Defect Segmentation
Jul 23, 2025The development of X-Ray microscopy (XRM) technology has enabled non-destructive inspection of semiconductor structures for defect identification. Deep learning is widely used as the state-of-the-art approach to perform visual analysis tasks. However, deep learning based models require large amount of annotated data to train. This can be time-consuming and expensive to obtain especially for dense prediction tasks like semantic segmentation. In this work, we explore active learning (AL) as a potential solution to alleviate the annotation burden. We identify two unique challenges when applying AL on semiconductor XRM scans: large domain shift and severe class-imbalance. To address these challenges, we propose to perform contrastive pretraining on the unlabelled data to obtain the initialization weights for each AL cycle, and a rareness-aware acquisition function that favors the selection of samples containing rare classes. We evaluate our method on a semiconductor dataset that is compiled from XRM scans of high bandwidth memory structures composed of logic and memory dies, and demonstrate that our method achieves state-of-the-art performance.
DA-CIL: Towards Domain Adaptive Class-Incremental 3D Object Detection
Dec 05, 2022



Deep learning has achieved notable success in 3D object detection with the advent of large-scale point cloud datasets. However, severe performance degradation in the past trained classes, i.e., catastrophic forgetting, still remains a critical issue for real-world deployment when the number of classes is unknown or may vary. Moreover, existing 3D class-incremental detection methods are developed for the single-domain scenario, which fail when encountering domain shift caused by different datasets, varying environments, etc. In this paper, we identify the unexplored yet valuable scenario, i.e., class-incremental learning under domain shift, and propose a novel 3D domain adaptive class-incremental object detection framework, DA-CIL, in which we design a novel dual-domain copy-paste augmentation method to construct multiple augmented domains for diversifying training distributions, thereby facilitating gradual domain adaptation. Then, multi-level consistency is explored to facilitate dual-teacher knowledge distillation from different domains for domain adaptive class-incremental learning. Extensive experiments on various datasets demonstrate the effectiveness of the proposed method over baselines in the domain adaptive class-incremental learning scenario.
* Accepted by the 33rd British Machine Vision Conference (BMVC 2022)
FaultNet: Faulty Rail-Valves Detection using Deep Learning and Computer Vision
Nov 09, 2019

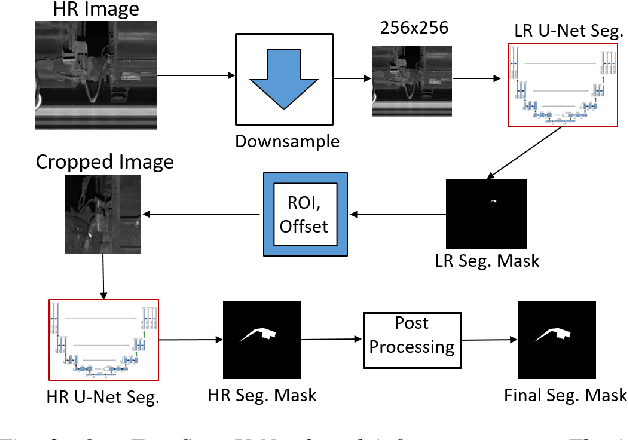
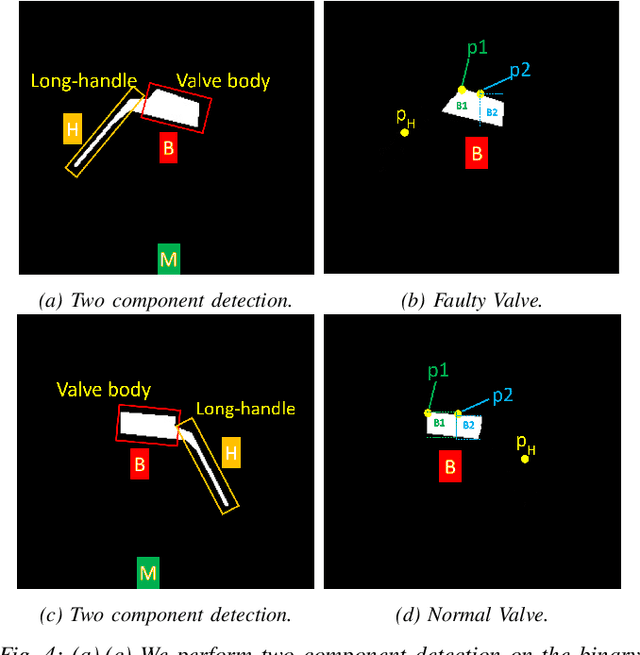
Regular inspection of rail valves and engines is an important task to ensure the safety and efficiency of railway networks around the globe. Over the past decade, computer vision and pattern recognition based techniques have gained traction for such inspection and defect detection tasks. An automated end-to-end trained system can potentially provide a low-cost, high throughput, and cheap alternative to manual visual inspection of these components. However, such systems require a huge amount of defective images for networks to understand complex defects. In this paper, a multi-phase deep learning based technique is proposed to perform accurate fault detection of rail-valves. Our approach uses a two-step method to perform high precision image segmentation of rail-valves resulting in pixel-wise accurate segmentation. Thereafter, a computer vision technique is used to identify faulty valves. We demonstrate that the proposed approach results in improved detection performance when compared to current state-of-theart techniques used in fault detection.
* 8 pages, 8 figures, ITSC 2019
Dense 3D Reconstruction for Visual Tunnel Inspection using Unmanned Aerial Vehicle
Nov 09, 2019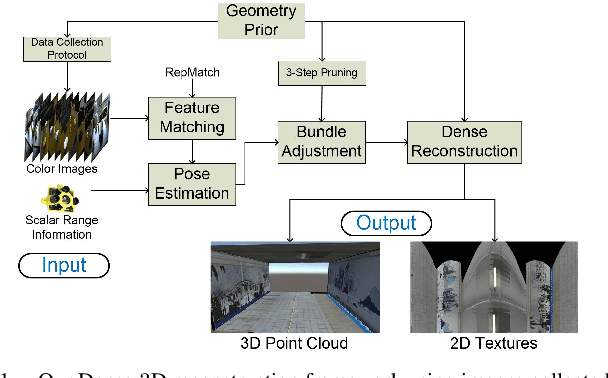



Advances in Unmanned Aerial Vehicle (UAV) opens venues for application such as tunnel inspection. Owing to its versatility to fly inside the tunnels, it can quickly identify defects and potential problems related to safety. However, long tunnels, especially with repetitive or uniform structures pose a significant problem for UAV navigation. Furthermore, post-processing visual data from the camera mounted on the UAV is required to generate useful information for the inspection task. In this work, we design a UAV with a single rotating camera to accomplish the task. Compared to other platforms, our solution can fit the stringent requirement for tunnel inspection, in terms of battery life, size and weight. While the current state-of-the-art can estimate camera pose and 3D geometry from a sequence of images, they assume large overlap, small rotational motion, and many distinct matching points between images. These assumptions severely limit their effectiveness in tunnel-like scenarios where the camera has erratic or large rotational motion, such as the one mounted on the UAV. This paper presents a novel solution which exploits Structure-from-Motion, Bundle Adjustment, and available geometry priors to robustly estimate camera pose and automatically reconstruct a fully-dense 3D scene using the least possible number of images in various challenging tunnel-like environments. We validate our system with both Virtual Reality application and experimentation with a real dataset. The results demonstrate that the proposed reconstruction along with texture mapping allows for remote navigation and inspection of tunnel-like environments, even those which are inaccessible for humans.
* 8 pages, 12 figures
A*3D Dataset: Towards Autonomous Driving in Challenging Environments
Sep 17, 2019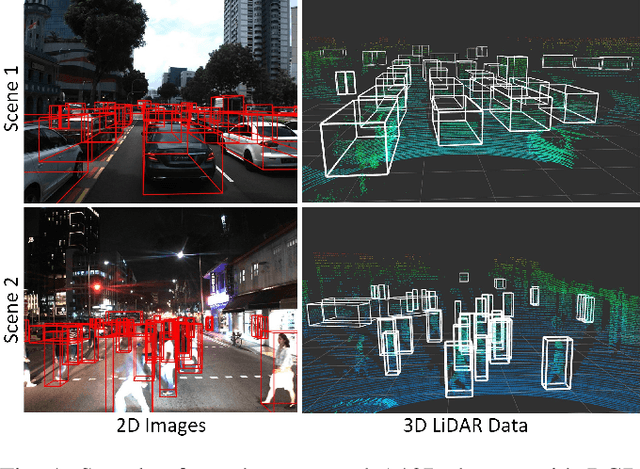
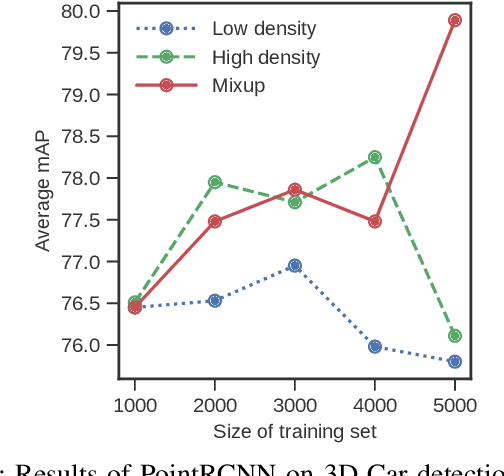
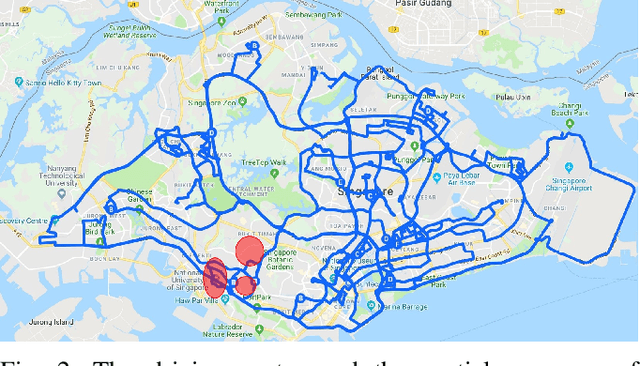
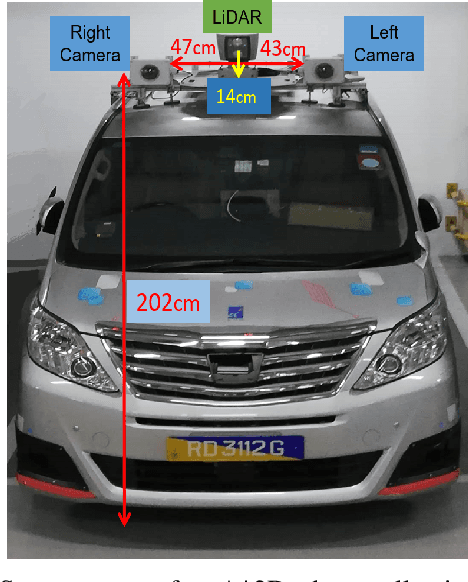
With the increasing global popularity of self-driving cars, there is an immediate need for challenging real-world datasets for benchmarking and training various computer vision tasks such as 3D object detection. Existing datasets either represent simple scenarios or provide only day-time data. In this paper, we introduce a new challenging A*3D dataset which consists of RGB images and LiDAR data with significant diversity of scene, time, and weather. The dataset consists of high-density images ($\approx~10$ times more than the pioneering KITTI dataset), heavy occlusions, a large number of night-time frames ($\approx~3$ times the nuScenes dataset), addressing the gaps in the existing datasets to push the boundaries of tasks in autonomous driving research to more challenging highly diverse environments. The dataset contains $39\text{K}$ frames, $7$ classes, and $230\text{K}$ 3D object annotations. An extensive 3D object detection benchmark evaluation on the A*3D dataset for various attributes such as high density, day-time/night-time, gives interesting insights into the advantages and limitations of training and testing 3D object detection in real-world setting.
Feature-less Stitching of Cylindrical Tunnel
Jun 27, 2018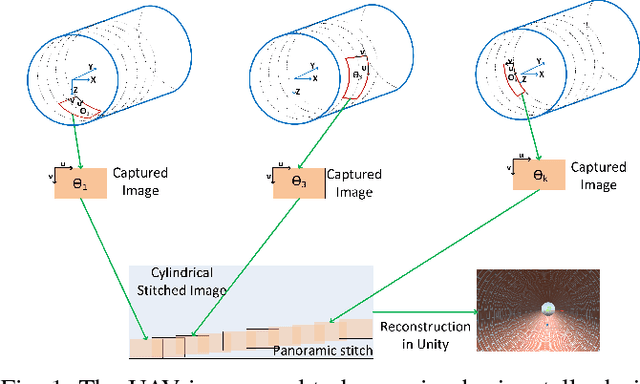
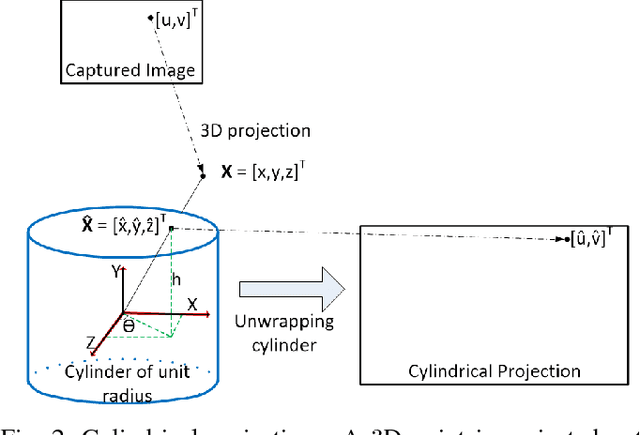

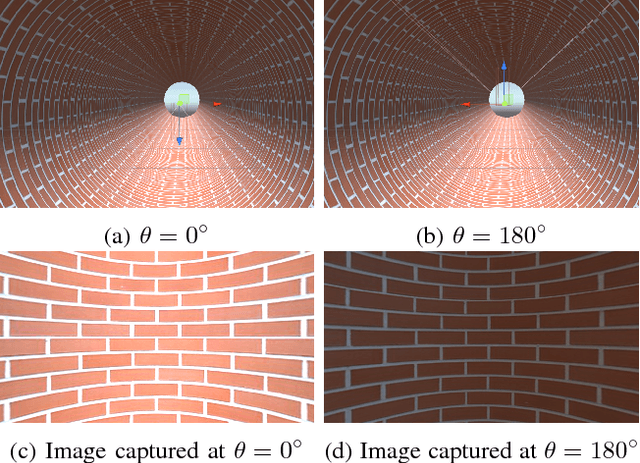
Traditional image stitching algorithms use transforms such as homography to combine different views of a scene. They usually work well when the scene is planar or when the camera is only rotated, keeping its position static. This severely limits their use in real world scenarios where an unmanned aerial vehicle (UAV) potentially hovers around and flies in an enclosed area while rotating to capture a video sequence. We utilize known scene geometry along with recorded camera trajectory to create cylindrical images captured in a given environment such as a tunnel where the camera rotates around its center. The captured images of the inner surface of the given scene are combined to create a composite panoramic image that is textured onto a 3D geometrical object in Unity graphical engine to create an immersive environment for end users.
Tracking objects using 3D object proposals
Dec 19, 2017
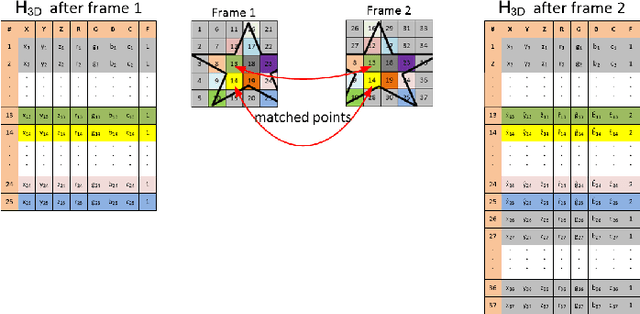


3D object proposals, quickly detected regions in a 3D scene that likely contain an object of interest, are an effective approach to improve the computational efficiency and accuracy of the object detection framework. In this work, we propose a novel online method that uses our previously developed 3D object proposals, in a RGB-D video sequence, to match and track static objects in the scene using shape matching. Our main observation is that depth images provide important information about the geometry of the scene that is often ignored in object matching techniques. Our method takes less than a second in MATLAB on the UW-RGBD scene dataset on a single thread CPU and thus, has potential to be used in low-power chips in Unmanned Aerial Vehicles (UAVs), quadcopters, and drones.
* 4 pages, 4 figures, published in APSIPA 2017
Locating 3D Object Proposals: A Depth-Based Online Approach
Sep 08, 2017



2D object proposals, quickly detected regions in an image that likely contain an object of interest, are an effective approach for improving the computational efficiency and accuracy of object detection in color images. In this work, we propose a novel online method that generates 3D object proposals in a RGB-D video sequence. Our main observation is that depth images provide important information about the geometry of the scene. Diverging from the traditional goal of 2D object proposals to provide a high recall (lots of 2D bounding boxes near potential objects), we aim for precise 3D proposals. We leverage on depth information per frame and multi-view scene information to obtain accurate 3D object proposals. Using efficient but robust registration enables us to combine multiple frames of a scene in near real time and generate 3D bounding boxes for potential 3D regions of interest. Using standard metrics, such as Precision-Recall curves and F-measure, we show that the proposed approach is significantly more accurate than the current state-of-the-art techniques. Our online approach can be integrated into SLAM based video processing for quick 3D object localization. Our method takes less than a second in MATLAB on the UW-RGBD scene dataset on a single thread CPU and thus, has potential to be used in low-power chips in Unmanned Aerial Vehicles (UAVs), quadcopters, and drones.
* 14 pages, 12 figures, journal
Calibration of depth cameras using denoised depth images
Sep 08, 2017



Depth sensing devices have created various new applications in scientific and commercial research with the advent of Microsoft Kinect and PMD (Photon Mixing Device) cameras. Most of these applications require the depth cameras to be pre-calibrated. However, traditional calibration methods using a checkerboard do not work very well for depth cameras due to the low image resolution. In this paper, we propose a depth calibration scheme which excels in estimating camera calibration parameters when only a handful of corners and calibration images are available. We exploit the noise properties of PMD devices to denoise depth measurements and perform camera calibration using the denoised depth as an additional set of measurements. Our synthetic and real experiments show that our depth denoising and depth based calibration scheme provides significantly better results than traditional calibration methods.
* 5 pages, 3 figures, conference